Selenium es la herramienta de prueba de software de automatización que obtiene el sitio web, realiza varias acciones u obtiene los datos del sitio web. Fue desarrollado principalmente para facilitar el trabajo de prueba mediante la automatización de las aplicaciones web. Hoy en día, además de usarse para pruebas, también se puede usar para hacer que el trabajo tedioso sea interesante. ¿Sabe que con la ayuda de Selenium, también puede extraer datos de la tabla en el sitio web? La respuesta es Sí , podemos eliminar fácilmente los datos de la tabla del sitio web. En este artículo se explica lo que debe hacer para extraer los datos de la tabla del sitio web.
Enfoque a seguir:
Consideremos el programa HTML simple que contiene tablas solo para comprender el enfoque de extraer la tabla del sitio web.
HTML
<!DOCTYPE html> <html> <head> <title>Selenium Table</title> </head> <body> <table border="1"> <thead> <tr> <th>Name</th> <th>Class</th> </tr> </thead> <tbody> <tr> <td>Vinayak</td> <td>12</td> </tr> <tr> <td>Ishita</td> <td>10</td> </tr> </tbody> </table> </body> </html>
Salida del navegador:

Siga los pasos a continuación:
Una vez que haya creado el archivo HTML, puede seguir los pasos a continuación y extraer datos de la tabla del sitio web por su cuenta.
- Primero, declare el controlador web
driver=webdriver.Chrome(executable_path=”Declare la ruta donde está instalado el controlador web”)
- Ahora, abra el sitio web desde el que desea obtener los datos de la tabla.
driver.get("Specify the path of the website")
- A continuación, debe encontrar filas en la tabla.
rows=1+len(driver.find_elements_by_xpath("Specify the altered path"))
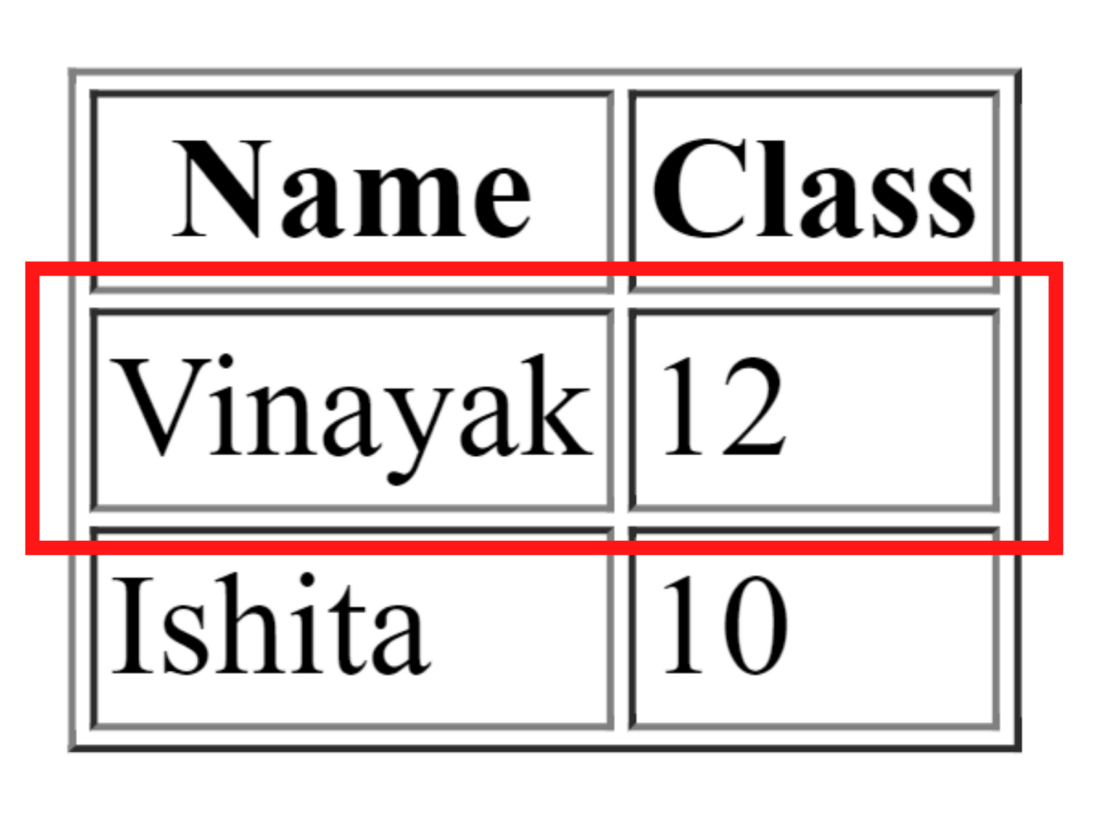
Aquí, el xpath alterado significa que si el xpath de la fila 1 es /html/body/table/tbody/tr[1] entonces, el xpath alterado será /html/body/table/tbody/tr Lo que se debe hacer aquí es para eliminar el valor de índice de la fila de la tabla.
NOTA: Recuerde agregar 1 al valor de la fila para el encabezado de la tabla, ya que no se incluyó al calcular las filas de la tabla.
- Además, busque columnas en la tabla.
cols=len(driver.find_elements_by_xpath("Specify the altered path"))
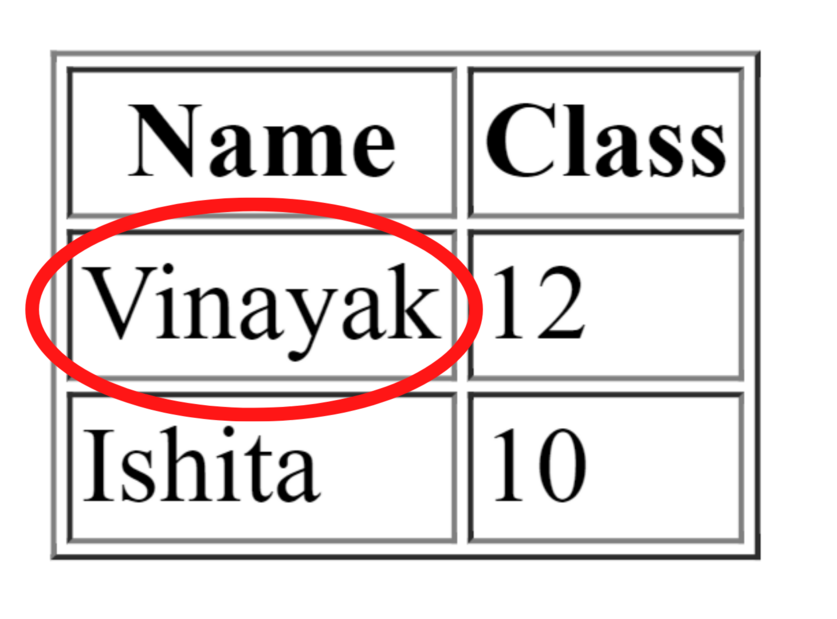
Aquí, el xpath alterado significa que si el xpath de la columna que muestra la salida Vinayak es /html/body/table/tbody/tr[1]/td[1] entonces, el xpath alterado será /html/body/table/tbody/tr /td Lo que debe hacerse aquí es eliminar el valor de índice de la fila de la tabla y los datos de la tabla.
- Además, obtenga datos de cada columna del cuerpo de la tabla.
for r in range(2, rows+1):
for p in range(1, cols+1):
value = driver.find_element_by_xpath("Specify the altered path").text
Aquí, el xpath alterado significa que si el xpath de la columna que muestra la salida Vinayak es /html/body/table/tbody/tr[1]/td[1] entonces, el xpath alterado será /html/body/table/tbody/tr [“+str(r)+”]/td[“+str(p)+”] Lo que se debe hacer aquí es agregar str(r) y str(p) para el valor de índice de la fila de la tabla y la tabla datos respectivamente.
- Finalmente, imprima los datos de la tabla.
print(value, end=' ') print()
¿Cómo extraer datos de la tabla del sitio web en Selenium?
Como hemos visto ahora, el enfoque a seguir para extraer los datos de la tabla mientras se usa la herramienta de automatización Selenium. Ahora, veamos el ejemplo completo de los datos de la tabla de desguace del sitio web. Utilizaremos este sitio web para extraer los datos de su tabla en el siguiente programa.
Python
# Python program to scrape table from website
# import libraries selenium and time
from selenium import webdriver
from time import sleep
# Create webdriver object
driver = webdriver.Chrome(
executable_path="C:\selenium\chromedriver_win32\chromedriver.exe")
# Get the website
driver.get(
"https://www.geeksforgeeks.org/find_element_by_link_text-driver-method-selenium-python/")
# Make Python sleep for some time
sleep(2)
# Obtain the number of rows in body
rows = 1+len(driver.find_elements_by_xpath(
"/html/body/div[3]/div[2]/div/div[1]/div/div/div/article/div[3]/div/table/tbody/tr"))
# Obtain the number of columns in table
cols = len(driver.find_elements_by_xpath(
"/html/body/div[3]/div[2]/div/div[1]/div/div/div/article/div[3]/div/table/tbody/tr[1]/td"))
# Print rows and columns
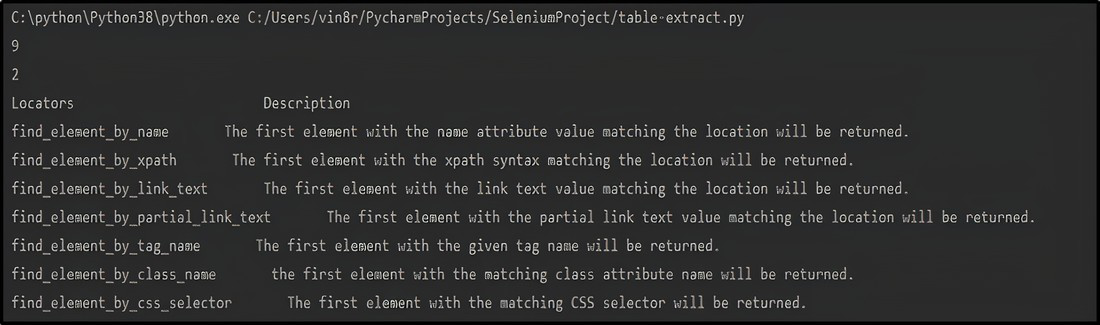
print(rows)
print(cols)
# Printing the table headers
print("Locators "+" Description")
# Printing the data of the table
for r in range(2, rows+1):
for p in range(1, cols+1):
# obtaining the text from each column of the table
value = driver.find_element_by_xpath(
"/html/body/div[3]/div[2]/div/div[1]/div/div/div/article/div[3]/div/table/tbody/tr["+str(r)+"]/td["+str(p)+"]").text
print(value, end=' ')
print()
Además, ejecute el código python usando:
python run.py
Producción: