En este artículo, aprenderemos cómo eliminar todas las URL de la página web utilizando el lenguaje de programación R.
Para descartar URL, usaremos bibliotecas httr y XML . Usaremos el paquete httr para hacer requests HTTPXML y XML para identificar URL usando etiquetas xml.
- La biblioteca httr se utiliza para realizar requests HTTP en lenguaje R, ya que proporciona un contenedor para el paquete curl.
- La biblioteca XML se utiliza para trabajar con archivos XML y etiquetas XML.
Instalación:
instalar.paquetes(“httr”)
instalar.paquetes(“XML”)
Después de instalar los paquetes necesarios, debemos importar las bibliotecas httr y XML y crear una variable y almacenar la URL del sitio. Ahora usaremos GET() de los paquetes httr para realizar requests HTTP, por lo que tenemos datos sin procesar y necesitamos convertirlos en formato HTML, lo que se puede hacer usando htmlParse() el
Hemos eliminado con éxito los datos HTML, pero solo necesitamos las URL, por lo que para eliminar la URL, usamos xpathSApply() y le pasamos los datos HTML. Todavía no hemos completado, ahora tenemos que pasarle la etiqueta XML para que podamos obtener todo lo relacionado con eso. etiqueta. Para las URL, usaremos la etiqueta «href» , que se usa para declarar las URL.
Nota: no necesita usar install.packages() si ya instaló el paquete una vez.
Implementación paso a paso
Paso 1: Instalación de bibliotecas:
R
# installing packages
install.packages("httr")
install.packages("XML")
Paso 2: Importar bibliotecas:
R
# importing packages library(httr) library(XML)
Paso 3: Realización de requests HTTP:
En este paso, pasaremos nuestra URL en GET() para solicitar datos del sitio y almacenar los datos devueltos en la variable de recursos.
R
url<-"https://www.geeksforgeeks.org" # making http request resource<-GET(url)
Paso 4: Analice los datos del sitio en formato HTML:
En este paso, analizamos los datos en HTML usando htmlparse().
R
# parsing data to html format parse<-htmlParse(resource)
Paso 5: Identifique las URL e imprímalas:
En este paso, usamos xpathSApply() para ubicar las URL.
R
# scrapping all the href tags links<-xpathSApply(parse,path = "//a",xmlGetAttr,"href") # printing links print(links)
Sabemos que la etiqueta <a> se usa para definir la URL y se almacena en el atributo href .
<a href=”url”></a>
Entonces xpathSApply() encontrará todas las etiquetas <a> y eliminará el enlace almacenado en el atributo href . Y luego almacenaremos todas las URL en una variable y las imprimiremos.
Ejemplo:
R
# installing packages
install.packages("httr")
install.packages("XML")
# importing packages
library(httr)
library(XML)
# storing request url in url variable
url < -"https://www.geeksforgeeks.org"
# making http request
resource < -GET(url)
# converting all the data to HTML format
parse < -htmlParse(resource)
# scrapping all the href tags
links < -xpathSApply(parse, path="//a", xmlGetAttr, "href")
# printing links
print(links)
Producción:
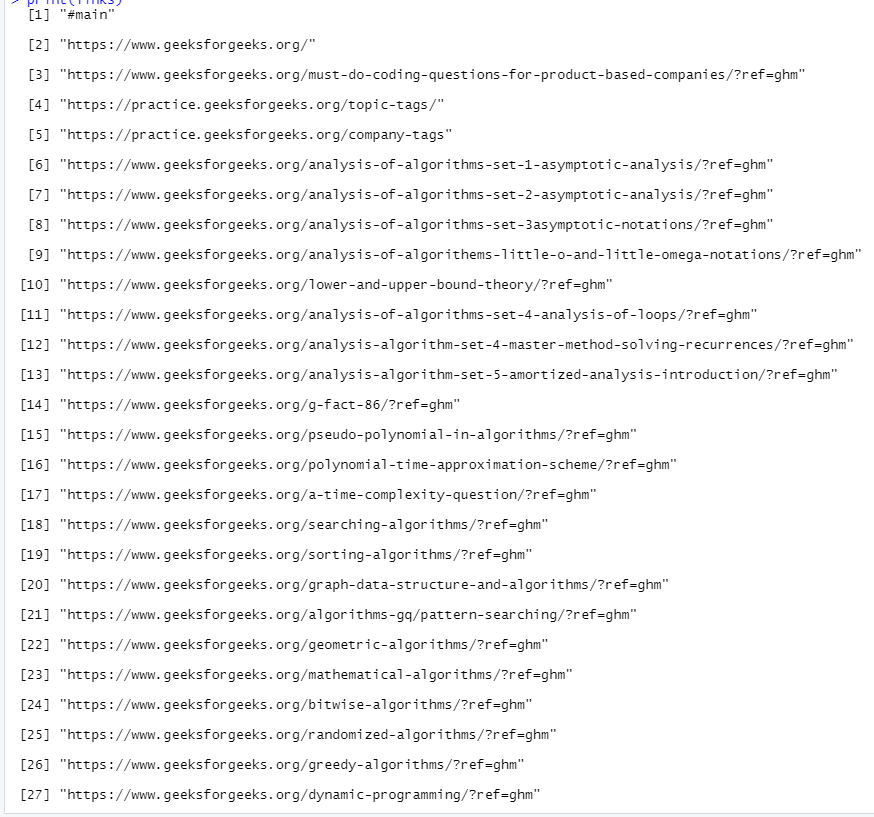
Publicación traducida automáticamente
Artículo escrito por vinamrayadav y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA