Requisito previo: introducción al diseño del compilador
Básicamente tenemos dos fases de compiladores, a saber, la fase de análisis y la fase de síntesis. La fase de análisis crea una representación intermedia del código fuente dado. La fase de síntesis crea un programa objetivo equivalente a partir de la representación intermedia.
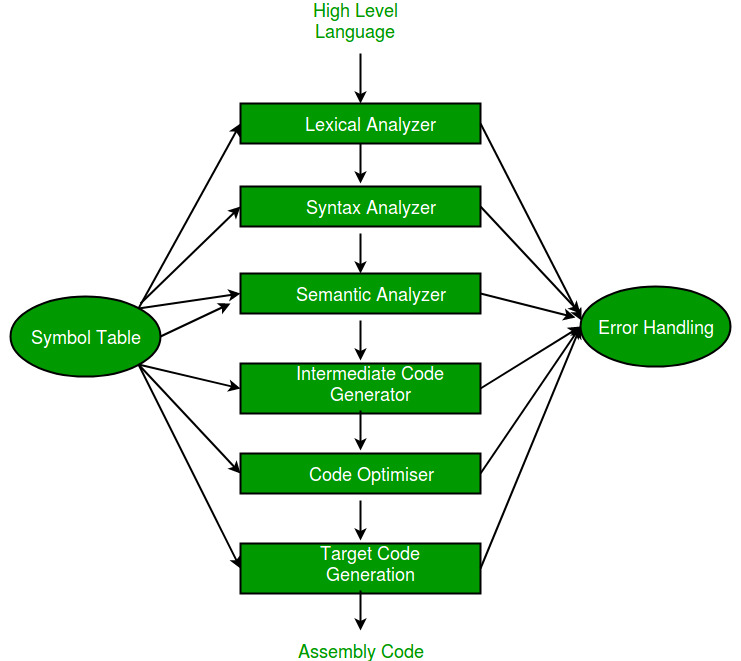
Tabla de símbolos: es una estructura de datos utilizada y mantenida por el compilador, que consta de todos los nombres de los identificadores junto con sus tipos. Ayuda al compilador a funcionar sin problemas al encontrar los identificadores rápidamente.
El análisis de un programa fuente se divide principalmente en tres fases. Están:
- Análisis lineal
: implica una fase de exploración en la que el flujo de caracteres se lee de izquierda a derecha. Luego se agrupa en varias fichas que tienen un significado colectivo. - Análisis jerárquico
: en esta fase de análisis, en función de un significado colectivo, los tokens se clasifican jerárquicamente en grupos anidados. - Análisis semántico
: esta fase se utiliza para verificar si los componentes del programa fuente son significativos o no.
El compilador tiene dos módulos, a saber, el front-end y el back-end. Front-end constituye el analizador léxico, el analizador semántico, el analizador de sintaxis y el generador de código intermedio. Y el resto se ensamblan para formar la parte trasera.
- Analizador léxico :
también se le llama escáner. Toma la salida del preprocesador (que realiza la inclusión de archivos y la expansión de macros) como la entrada que está en un lenguaje puro de alto nivel. Lee los caracteres del programa fuente y los agrupa en lexemas (secuencia de caracteres que “van juntos”). Cada lexema corresponde a una ficha. Los tokens se definen mediante expresiones regulares que el analizador léxico entiende. También elimina errores léxicos (p. ej., caracteres erróneos), comentarios y espacios en blanco. - Analizador de sintaxis : a veces se le llama analizador. Construye el árbol de análisis. Toma todos los tokens uno por uno y usa la gramática libre de contexto para construir el árbol de análisis.
¿Por qué Gramática?
Las reglas de la programación se pueden representar en su totalidad en unas pocas producciones. Usando estas producciones podemos representar lo que realmente es el programa. La entrada debe verificarse si está en el formato deseado o no.
El árbol de análisis también se denomina árbol de derivación. Los árboles de análisis se construyen generalmente para verificar la ambigüedad en la gramática dada. Hay ciertas reglas asociadas con el árbol de derivación.- Cualquier identificador es una expresión.
- Cualquier número puede ser llamado una expresión.
- Realizar cualquier operación en la expresión dada siempre dará como resultado una expresión. Por ejemplo, la suma de dos expresiones también es una expresión.
- El árbol de análisis se puede comprimir para formar un árbol de sintaxis

- Analizador semántico: verifica el árbol de análisis, ya sea significativo o no. Además, produce un árbol de análisis verificado. También realiza verificación de tipos, verificación de etiquetas y verificación de control de flujo.
- Generador de código intermedio : genera código intermedio, que es una forma que una máquina puede ejecutar fácilmente. Tenemos muchos códigos intermedios populares. Ejemplo: tres códigos de dirección, etc. El código intermedio se convierte a lenguaje de máquina utilizando las dos últimas fases que dependen de la plataforma.
Hasta el código intermedio, es lo mismo para todos los compiladores, pero después de eso, depende de la plataforma. Para construir un nuevo compilador no necesitamos construirlo desde cero. Podemos tomar el código intermedio del compilador ya existente y construir las dos últimas partes.
- Code Optimizer : transforma el código para que consuma menos recursos y produzca más velocidad. El significado del código que se está transformando no se altera. La optimización se puede clasificar en dos tipos: dependiente de la máquina e independiente de la máquina.
- Generador de código de destino: el objetivo principal del generador de código de destino es escribir un código que la máquina pueda entender y también registrar la asignación, la selección de instrucciones, etc. La salida depende del tipo de ensamblador. Esta es la etapa final de la compilación. El código optimizado se convierte en código de máquina reubicable que luego forma la entrada para el enlazador y el cargador.
Todas estas seis fases están asociadas con el administrador de la tabla de símbolos y el controlador de errores, como se muestra en el diagrama de bloques anterior.
Publicación traducida automáticamente
Artículo escrito por Rajesh_Kr_Jha y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA