Muchas veces, mientras se trabaja en el marco de datos de PySpark SQL, los marcos de datos contienen muchos valores NULL/Ninguno en las columnas, en muchos de los casos, antes de realizar cualquiera de las operaciones del marco de datos, primero tenemos que manejar los valores NULL/Ninguno para obtener el deseado. resultado o salida, tenemos que filtrar esos valores NULL del marco de datos.
En este artículo, aprenderá cómo filtrar la columna del marco de datos de PySpark con valores NULL/Ninguno.
Para filtrar los valores NULL/None, tenemos la función en PySpark API conocida como filter() y con esta función, estamos usando la función isNotNull() .
Sintaxis:
- df.filter (condición): esta función devuelve el nuevo marco de datos con los valores que satisfacen la condición dada.
- df.column_name.isNotNull() : esta función se usa para filtrar las filas que no son NULL/Ninguno en la columna del marco de datos.
Ejemplo 1: filtrado de la columna del marco de datos de PySpark con el valor Ninguno
En el siguiente código, hemos creado la sesión de Spark y luego hemos creado el marco de datos que contiene algunos valores de Ninguno en cada columna. Ahora, hemos filtrado los valores Ninguno presentes en la columna Nombre usando filter() en el que hemos pasado la condición df.Name.isNotNull() para filtrar los valores Ninguno de la columna Nombre.
Python
# importing necessary libraries
from pyspark.sql import SparkSession
# function to create SparkSession
def create_session():
spk = SparkSession.builder \
.master("local") \
.appName("Filter_values.com") \
.getOrCreate()
return spk
# function to create dataframe
def create_df(spark, data, schema):
df1 = spark.createDataFrame(data, schema)
return df1
if __name__ == "__main__":
# calling function to create SparkSession
spark = create_session()
input_data = [("Shivansh", "Data Scientist", "Noida"),
(None, "Software Developer", None),
("Swati", "Data Analyst", "Hyderabad"),
(None, None, "Noida"),
("Arpit", "Android Developer", "Banglore"),
(None, None, None)]
schema = ["Name", "Job Profile", "City"]
# calling function to create dataframe
df = create_df(spark, input_data, schema)
# filtering the columns with None values
df = df.filter(df.Name.isNotNull())
# visulizing the dataframe
df.show()
Producción:
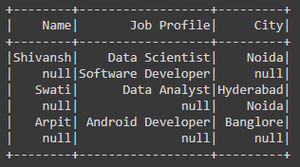
Trama de datos original
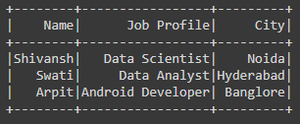
Marco de datos después de filtrar valores NULL/Ninguno
Ejemplo 2: filtrado de la columna del marco de datos de PySpark con valores NULL/Ninguno usando la función filter()
En el siguiente código, hemos creado la sesión de Spark y luego hemos creado el marco de datos que contiene algunos valores de Ninguno en cada columna. Ahora, hemos filtrado los valores Ninguno presentes en la columna Ciudad usando filter() en el que hemos pasado la condición en forma de idioma inglés, es decir, «La ciudad no es nula». Esta es la condición para filtrar los valores Ninguno de la columna Ciudad.
Nota: La condición debe estar entre comillas dobles.
Python
# importing necessary libraries
from pyspark.sql import SparkSession
# function to create new SparkSession
def create_session():
spk = SparkSession.builder \
.master("local") \
.appName("Filter_values.com") \
.getOrCreate()
return spk
def create_df(spark, data, schema):
df1 = spark.createDataFrame(data, schema)
return df1
if __name__ == "__main__":
# calling function to create SparkSession
spark = create_session()
input_data = [("Shivansh", "Data Scientist", "Noida"),
(None, "Software Developer", None),
("Swati", "Data Analyst", "Hyderabad"),
(None, None, "Noida"),
("Arpit", "Android Developer", "Banglore"),
(None, None, None)]
schema = ["Name", "Job Profile", "City"]
# calling function to create dataframe
df = create_df(spark, input_data, schema)
# filtering the columns with None values
df = df.filter("City is Not NULL")
# visulizing the dataframe
df.show()
Producción:
Trama de datos original
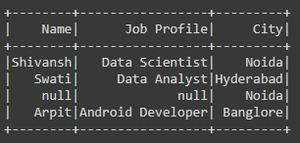
Después de filtrar valores NULL/Ninguno de la columna de la ciudad
Ejemplo 3: filtrar columnas con valores Ninguno usando filter() cuando el nombre de la columna tiene espacio
En el siguiente código, hemos creado la sesión de Spark y luego hemos creado el marco de datos que contiene algunos valores de Ninguno en cada columna. Hemos filtrado los valores Ninguno presentes en la columna ‘Perfil de trabajo’ usando la función filter() en la que hemos pasado la condición df[“Perfil de trabajo”].isNotNull() para filtrar los valores Ninguno de la columna Perfil de trabajo.
Nota: Para acceder al nombre de la columna que tiene espacio entre las palabras, se accede usando corchetes [] significa que con referencia al marco de datos tenemos que dar el nombre usando corchetes.
Python
# importing necessary libraries
from pyspark.sql import SparkSession
# function to create SparkSession
def create_session():
spk = SparkSession.builder \
.master("local") \
.appName("Filter_values.com") \
.getOrCreate()
return spk
def create_df(spark, data, schema):
df1 = spark.createDataFrame(data, schema)
return df1
if __name__ == "__main__":
# calling function to create SparkSession
spark = create_session()
input_data = [("Shivansh", "Data Scientist", "Noida"),
(None, "Software Developer", None),
("Swati", "Data Analyst", "Hyderabad"),
(None, None, "Noida"),
("Arpit", "Android Developer", "Banglore"),
(None, None, None)]
schema = ["Name", "Job Profile", "City"]
# calling function to create dataframe
df = create_df(spark, input_data, schema)
# filtering the Job Profile with None values
df = df.filter(df["Job Profile"].isNotNull())
# visulizing the dataframe
df.show()
Producción:
Trama de datos original
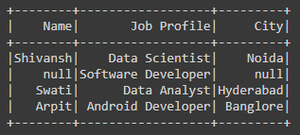
Después de filtrar valores NULL/Ninguno de la columna Perfil de trabajo
Publicación traducida automáticamente
Artículo escrito por srishivansh5404 y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA