Los filtros son programas que toman texto sin formato (ya sea almacenado en un archivo o producido por otro programa) como entrada estándar, lo transforman en un formato significativo y luego lo devuelven como salida estándar. Linux tiene una serie de filtros. A continuación se explican algunos de los filtros más utilizados:
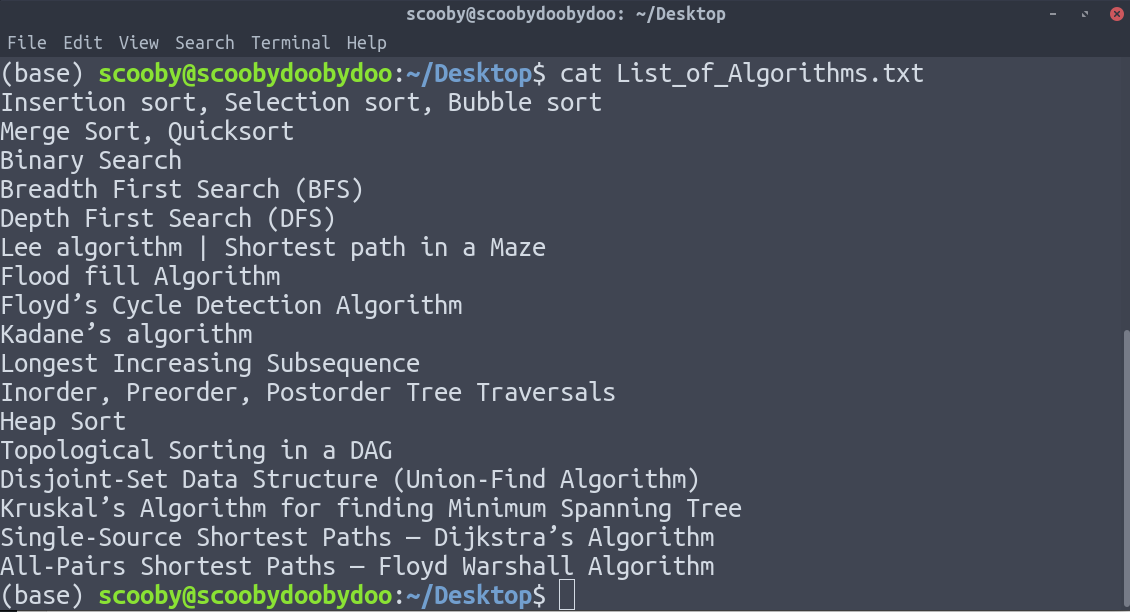
1. cat : Muestra el texto del archivo línea por línea.
Sintaxis:
cat [path]
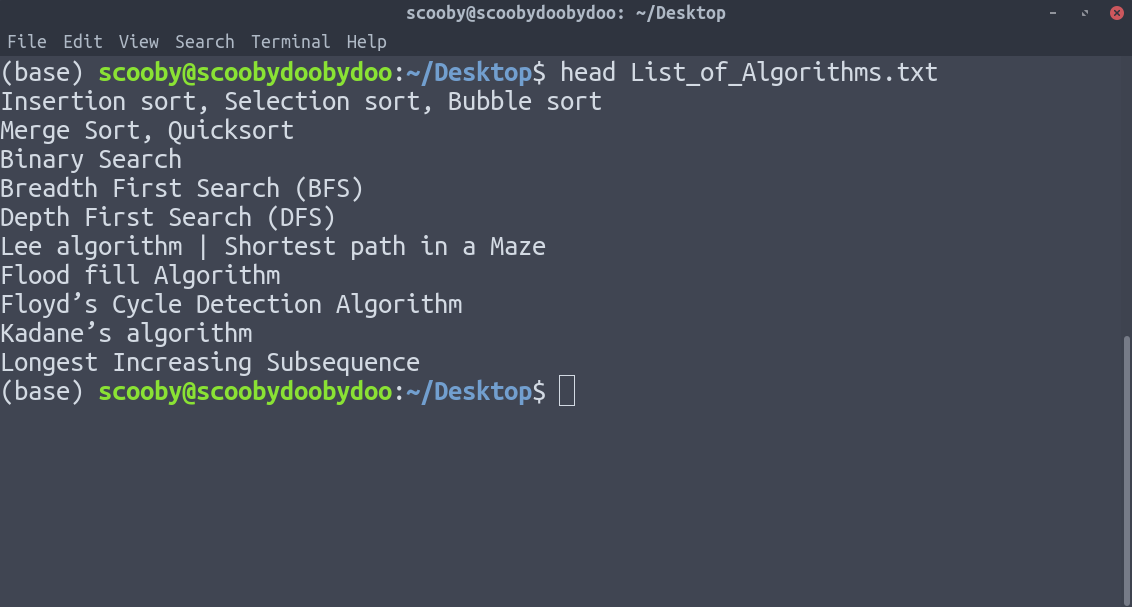
2. head : muestra las primeras n líneas de los archivos de texto especificados. Si no se especifica el número de líneas, por defecto imprime las primeras 10 líneas.
Sintaxis:
head [-number_of_lines_to_print] [path]
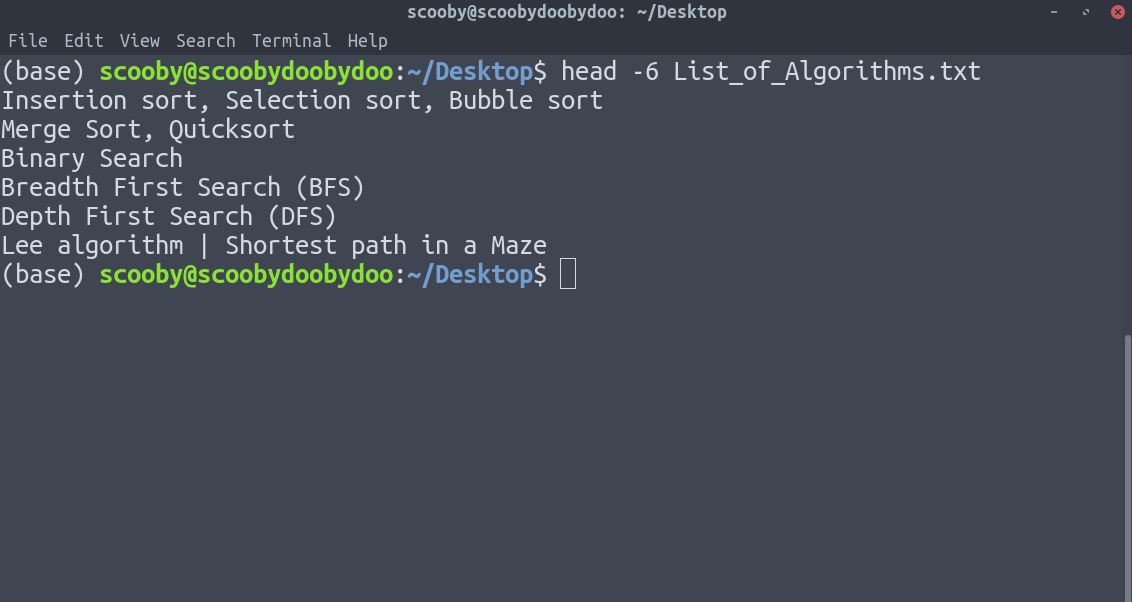
3. cola: funciona de la misma manera que la cabeza, solo que en orden inverso. La única diferencia en la cola es que devuelve las líneas de abajo hacia arriba.
Sintaxis:
tail [-number_of_lines_to_print] [path]
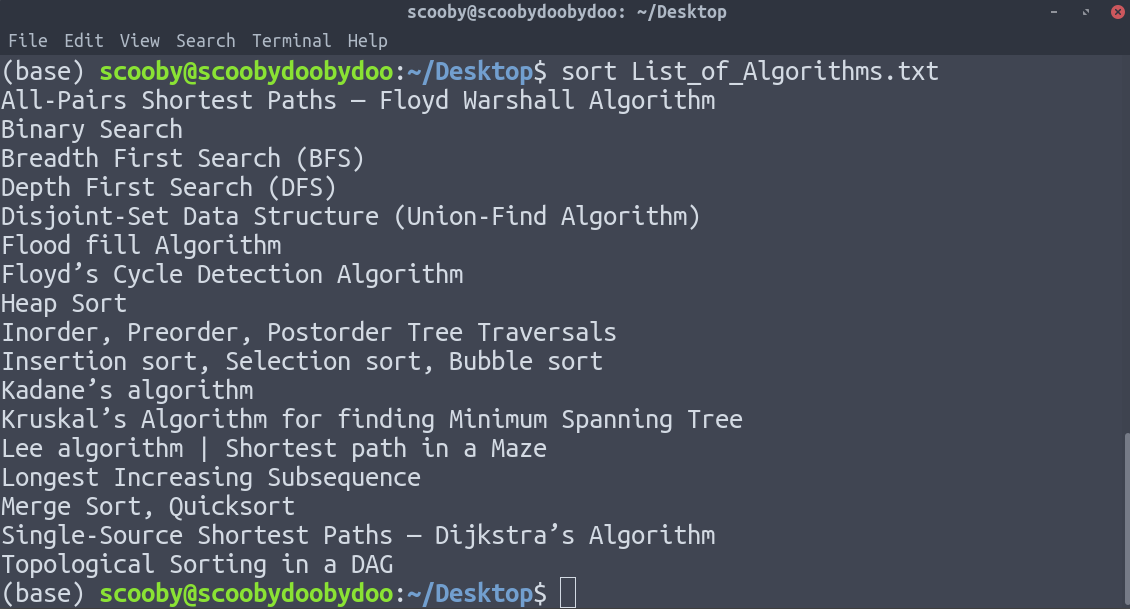
4. ordenar : ordena las líneas alfabéticamente de forma predeterminada, pero hay muchas opciones disponibles para modificar el mecanismo de clasificación. Asegúrese de revisar la página principal para ver todo lo que puede hacer.
Sintaxis:
sort [-options] [path]
5. uniq : elimina las líneas duplicadas. uniq tiene la limitación de que solo puede eliminar líneas duplicadas continuas (aunque esto se puede solucionar mediante el uso de tuberías). Suponiendo que tenemos los siguientes datos.
Sintaxis:
uniq [options] [path]
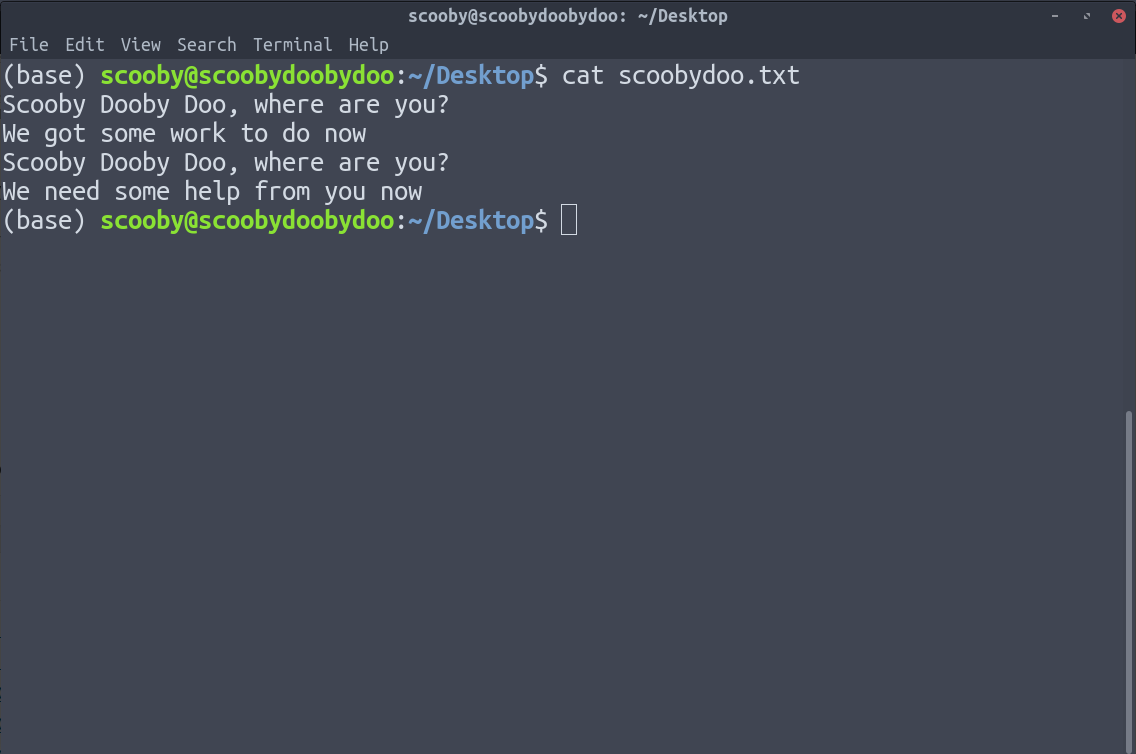
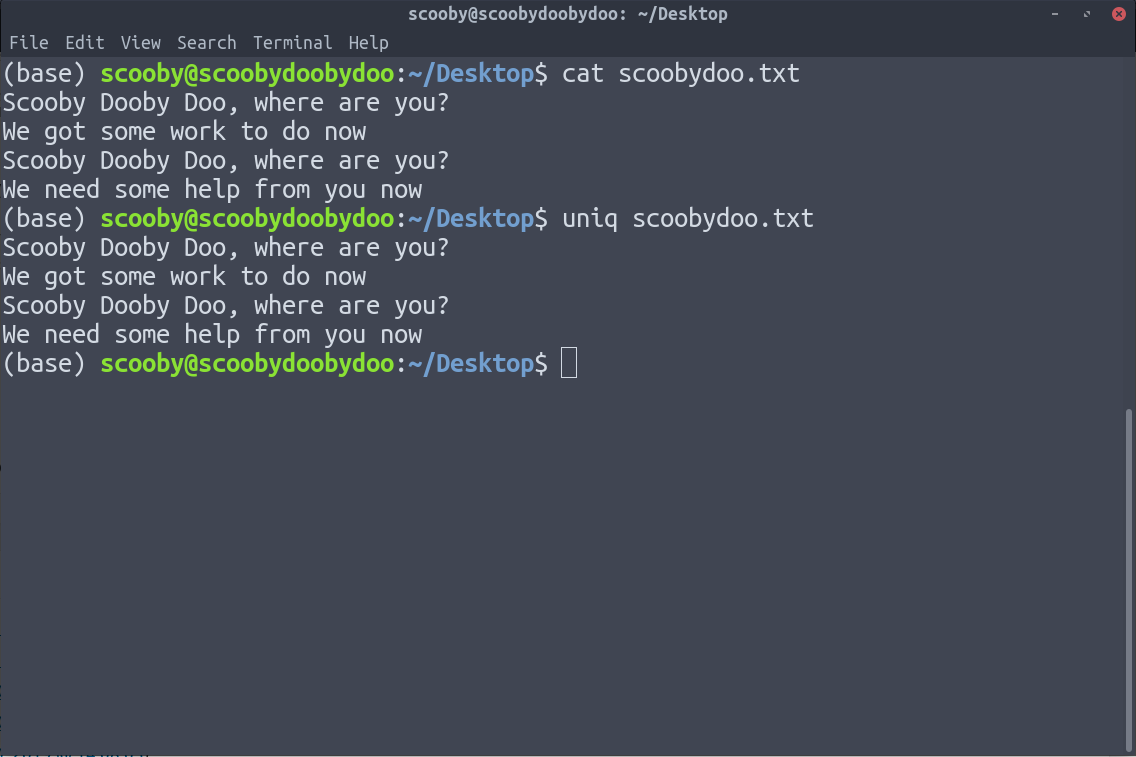
Puede ver que aplicar uniq no elimina las líneas duplicadas, porque uniq solo elimina las líneas duplicadas que están juntas.
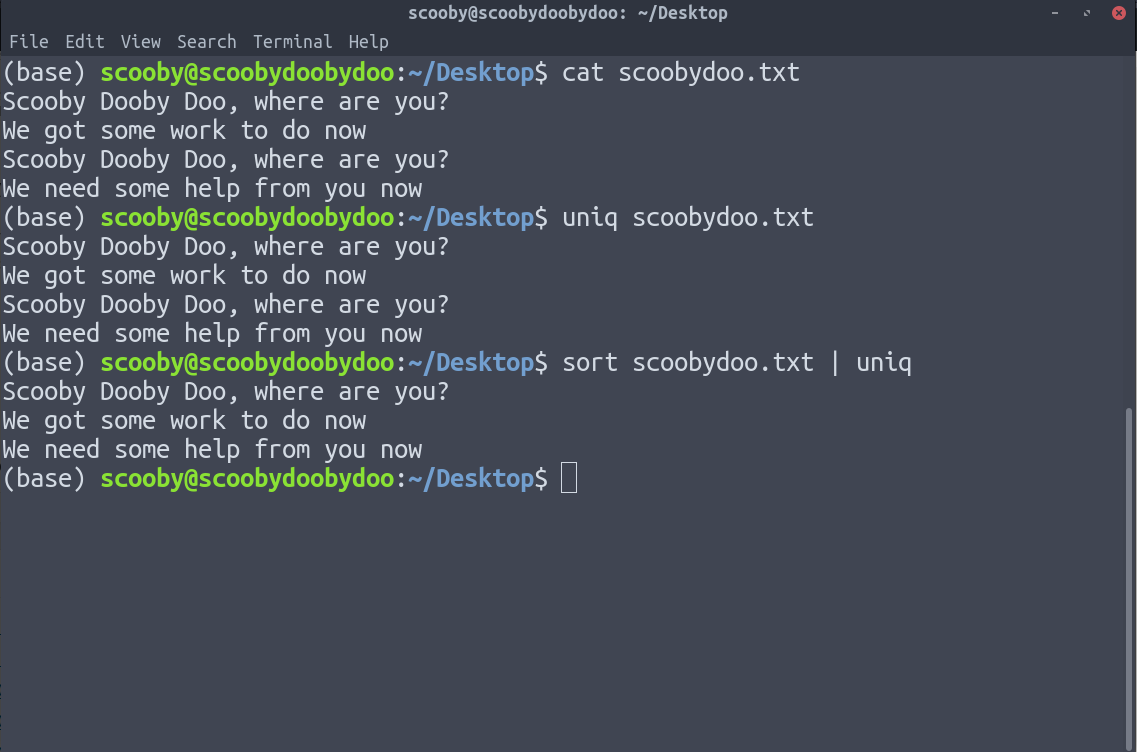
Al aplicar uniq a los datos ordenados, elimina las líneas duplicadas porque, después de ordenar los datos, las líneas duplicadas se juntan.
6. wc : el comando wc proporciona el número de líneas, palabras y caracteres de los datos.
Sintaxis:
wc [-options] [path]
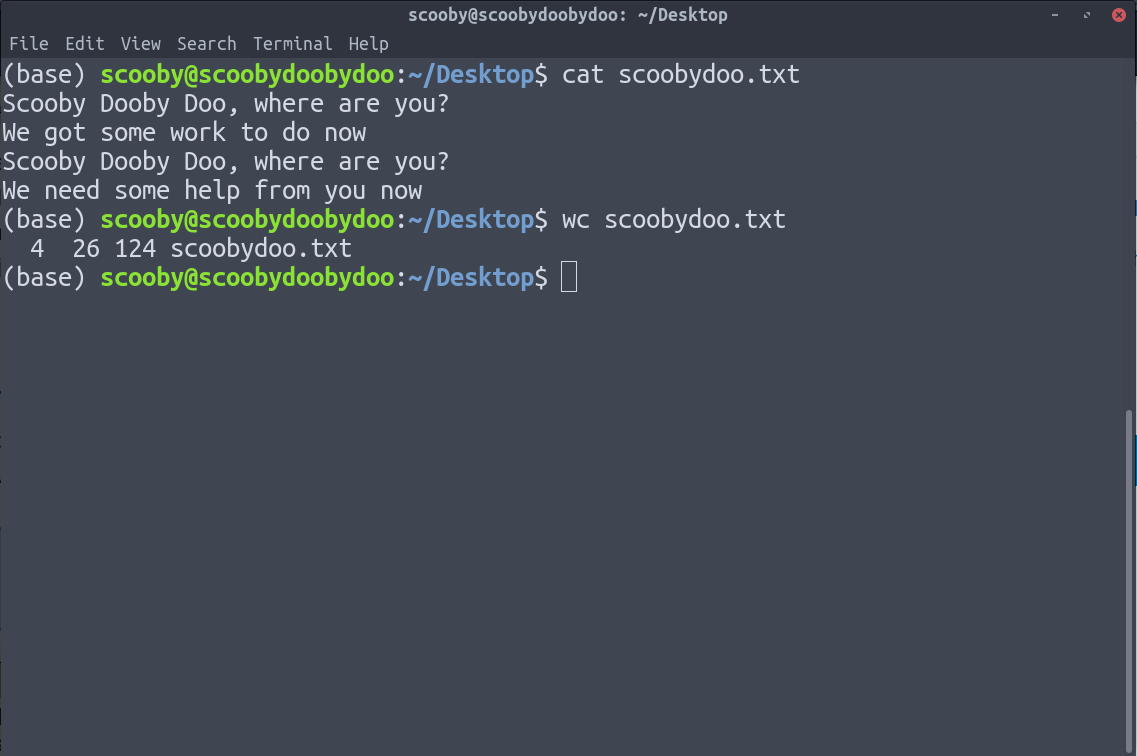
En la imagen de arriba, el wc da 4 salidas como:
- número de líneas
- número de palabras
- número de caracteres
- sendero
7. grep : grep se usa para buscar una información particular de un archivo de texto.
Sintaxis:
grep [options] pattern [path]
A continuación se muestran las dos formas en que podemos implementar grep.
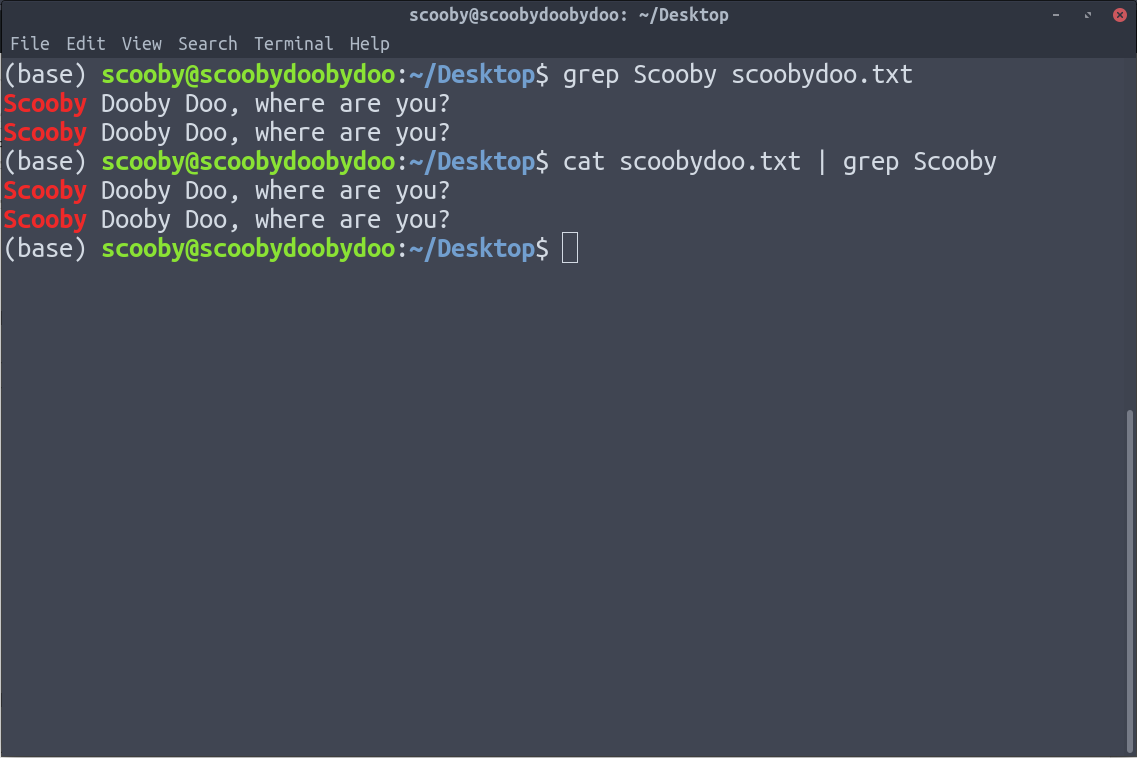
8. tac : tac es justo lo contrario de cat y funciona de la misma manera, es decir, en lugar de imprimir desde las líneas 1 a la n, imprime las líneas n a la 1. Es justo lo contrario que el comando cat.
Sintaxis:
tac [path]
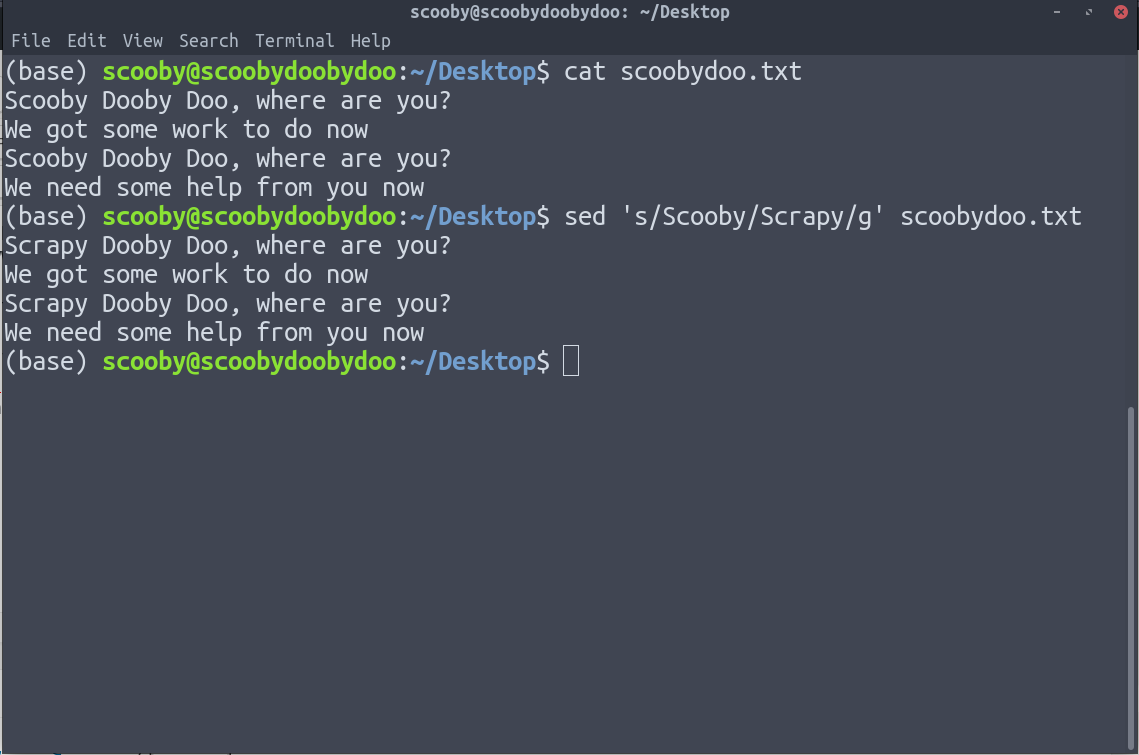
9. sed : sed significa editor de secuencias. Nos permite aplicar la operación de búsqueda y reemplazo en nuestros datos de manera efectiva. sed es un filtro bastante avanzado y todas sus opciones se pueden ver en su página de manual.
Sintaxis:
sed [path]
La expresión que hemos usado arriba es muy básica y tiene la forma ‘s/buscar/reemplazar/g’
En la imagen de arriba, podemos ver claramente que Scooby es reemplazado por Scrapy.
10. nl : nl se usa para numerar las líneas de nuestros datos de texto.
Sintaxis:
nl [-options] [path]
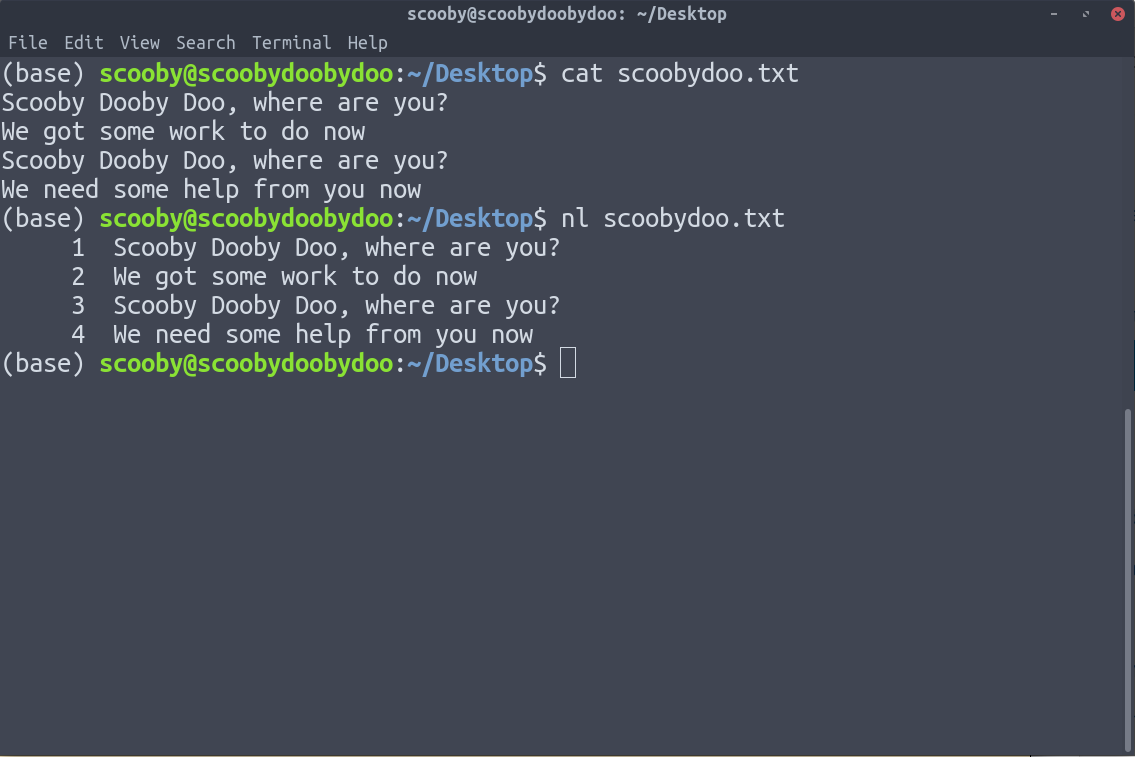
Se puede ver claramente en la imagen de arriba que las líneas han sido numeradas
Publicación traducida automáticamente
Artículo escrito por Sc00by_d00 y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA