Python es un excelente lenguaje para realizar análisis de datos, principalmente debido al fantástico ecosistema de paquetes de Python centrados en datos. Pandas es uno de esos paquetes y facilita mucho la importación y el análisis de datos. En este artículo, estamos usando nba.csvel archivo “ ” para descargar el CSV, haga clic aquí.
Transmitir un objeto pandas a un tipo de d especificado
La función DataFrame.astype() se usa para convertir un objeto pandas a un tipo de d especificado. astype()La función también proporciona la capacidad de convertir cualquier columna existente adecuada a tipo categórico.
Código #1: Convierta el tipo de datos de la columna Peso.
# importing pandas as pd
import pandas as pd
# Making data frame from the csv file
df = pd.read_csv("nba.csv")
# Printing the first 10 rows of
# the data frame for visualization
df[:10]
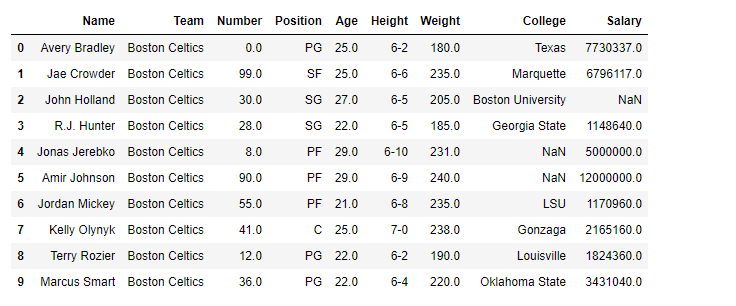
Como los datos tienen algunos valores «nan», para evitar cualquier error, descartaremos todas las filas que contengan cualquier nan valor.
# drop all those rows which # have any 'nan' value in it. df.dropna(inplace = True)
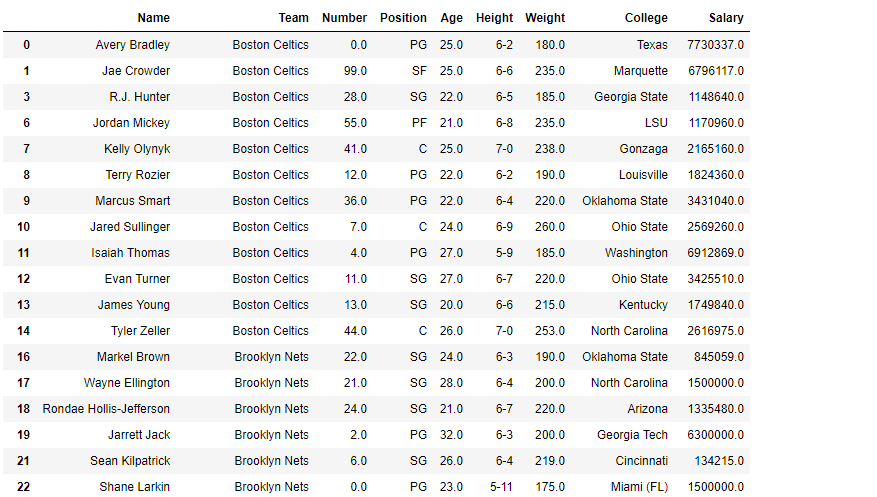
# let's find out the data type of Weight column
before = type(df.Weight[0])
# Now we will convert it into 'int64' type.
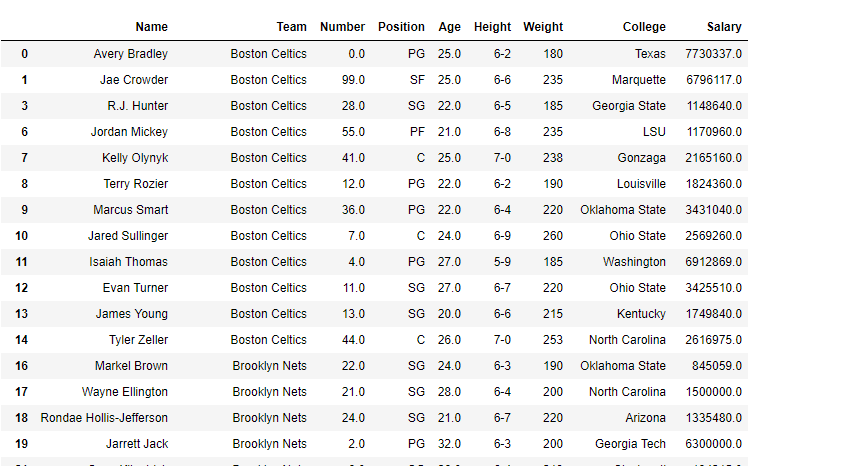
df.Weight = df.We<strong>ight.astype('int64')
# let's find out the data type after casting
after = type(df.Weight[0])
# print the value of before
before
# print the value of after
after
Producción:

# print the data frame and see # what it looks like after the change df
Inferir un mejor tipo de datos para la columna del objeto de entrada
La función DataFrame.infer_objects() intenta inferir un mejor tipo de datos para la columna del objeto de entrada. Esta función intenta la conversión suave de columnas con tipo de objeto, dejando sin cambios las columnas que no son objetos y las que no se pueden convertir. Las reglas de inferencia son las mismas que durante la construcción normal de Series/DataFrame.
Código n. ° 1: use infer_objects()la función para inferir un mejor tipo de datos.
# importing pandas as pd
import pandas as pd
# Creating the dataframe
df = pd.DataFrame({"A":["sofia", 5, 8, 11, 100],
"B":[2, 8, 77, 4, 11],
"C":["amy", 11, 4, 6, 9]})
# Print the dataframe
print(df)
Producción :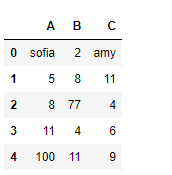
Veamos el dtype (tipo de datos) de cada columna en el marco de datos.
# to print the basic info df.info()
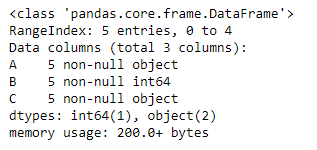
Como podemos ver en la salida, la primera y la tercera columna son de objecttipo. mientras que la segunda columna es de int64tipo. Ahora corte el marco de datos y cree un nuevo marco de datos a partir de él.
# slice from the 1st row till end df_new = df[1:] # Let's print the new data frame df_new # Now let's print the data type of the columns df_new.info()
Producción :
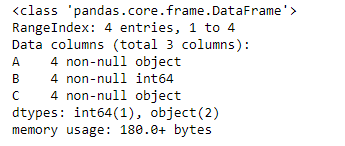
Como podemos ver en la salida, las columnas «A» y «C» son de tipo objeto aunque contienen un valor entero. Entonces, probemos la infer_objects()función.
# applying infer_objects() function. df_new = df_new.infer_objects() # Print the dtype after applying the function df_new.info()
Salida:
ahora, si observamos el tipo de cada columna, podemos ver que la columna «A» y «C» ahora son de int64tipo.
Detectar valores faltantes
La función DataFrame.isna() se usa para detectar valores faltantes. Devuelve un objeto booleano del mismo tamaño que indica si los valores son NA. Los valores NA, como Ninguno o numpy.NaN, se asignan a valores Verdaderos. Todo lo demás se asigna a valores falsos. Los caracteres como strings vacías «o numpy.inf no se consideran valores NA (a menos que configure pandas.options.mode.use_inf_as_na = True).
Código n. ° 1: use isna()la función para detectar los valores faltantes en un marco de datos.
# importing pandas as pd
import pandas as pd
# Creating the dataframe
df = pd.read_csv("nba.csv")
# Print the dataframe
df
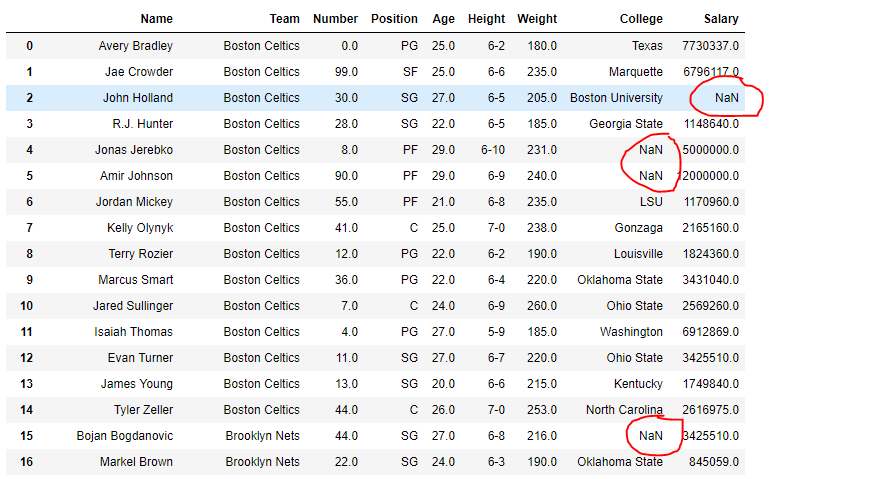
Usemos la isna()función para detectar los valores faltantes.
# detect the missing values df.isna()
Salida: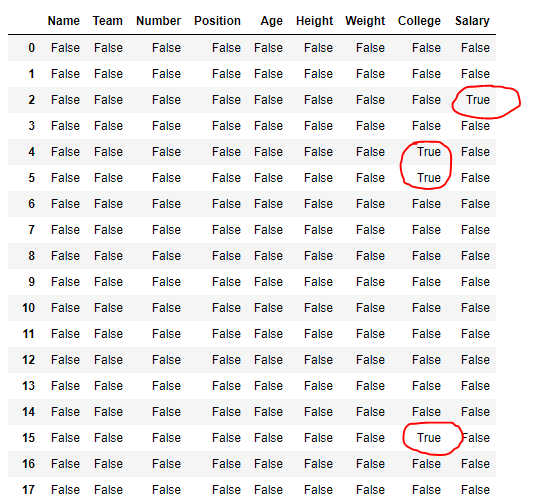
en la salida, las celdas correspondientes a los valores faltantes contienen el valor verdadero o falso.
Detección de valores existentes/no perdidos
La función DataFrame.notna() detecta valores existentes/que no faltan en el marco de datos. La función devuelve un objeto booleano que tiene el mismo tamaño que el objeto sobre el que se aplica, indicando si cada valor individual es un valor na o no. Todos los valores que no faltan se asignan a verdadero y los valores que faltan se asignan a falso.
Código n. ° 1: use notna()la función para encontrar todos los valores que no faltan en el marco de datos.
# importing pandas as pd
import pandas as pd
# Creating the first dataframe
df = pd.DataFrame({"A":[14, 4, 5, 4, 1],
"B":[5, 2, 54, 3, 2],
"C":[20, 20, 7, 3, 8],
"D":[14, 3, 6, 2, 6]})
# Print the dataframe
print(df)
Usemos la dataframe.notna()función para encontrar todos los valores que no faltan en el marco de datos.
# find non-na values df.notna()
Salida:
como podemos ver en la salida, todos los valores que no faltan en el marco de datos se han asignado a verdaderos. No hay ningún valor falso ya que no falta ningún valor en el marco de datos.
Métodos de conversión en DataFrame
| Función | Descripción |
|---|---|
| Marco de datos.convert_objects() | Intente inferir un mejor dtype para las columnas de objetos. |
| Marco de datos.copia() | Devuelve una copia de los índices y datos de este objeto. |
| Marco de datos.bool() | Devuelve el bool de un solo elemento PandasObject. |
Publicación traducida automáticamente
Artículo escrito por GeeksforGeeks-1 y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA