En este artículo, fusionaremos dos marcos de datos desiguales y luego reemplazaremos los valores NA en el marco de datos resultante con 0 usando el lenguaje de programación R.
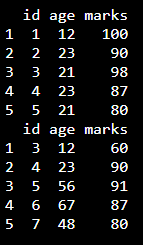
Marcos de datos en uso:
Fusionando los marcos de datos
Podemos fusionar los dos marcos de datos usando la función merge().
Sintaxis:
fusionar (marco de datos1, marco de datos2, por = «columna», todo = VERDADERO)
dónde,
- dataframe1 es el primer marco de datos
- dataframe2 es el segundo marco de datos
- columna es el nombre de la columna que se fusionará en función de esta columna
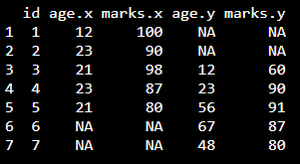
Ejemplo: programa R para fusionar los marcos de datos por columna de identificación
R
# create dataframe1 with 3 columns data1 = data.frame(id=c(1, 2, 3, 4, 5), age=c(12, 23, 21, 23, 21), marks=c(100, 90, 98, 87, 80)) # create dataframe2 with 3 columns data2 = data.frame(id=c(3, 4, 5, 6, 7), age=c(12, 23, 56, 67, 48), marks=c(60, 90, 91, 87, 80)) # merge the dataframes by id column data = merge(data1, data2, by='id', all=TRUE) # display merged dataframe print(data)
Producción:
Reemplazar NA con 0 en el marco de datos
Podemos reemplazar NA usando la función is.na(). Al configurar los datos en 0 dentro del índice, el trabajo se puede hacer fácilmente.
Sintaxis:
datos[es.na(datos)] = 0
Donde, data es el marco de datos fusionado con valores NA
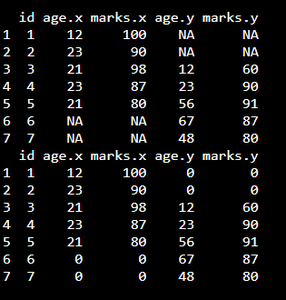
Ejemplo: programa R para reemplazar NA con 0
R
# create dataframe1 with 3 columns data1 = data.frame(id=c(1, 2, 3, 4, 5), age=c(12, 23, 21, 23, 21), marks=c(100, 90, 98, 87, 80)) # create dataframe2 with 3 columns data2 = data.frame(id=c(3, 4, 5, 6, 7), age=c(12, 23, 56, 67, 48), marks=c(60, 90, 91, 87, 80)) # merge the dataframes by id column data = merge(data1, data2, by='id', all=TRUE) # display merged dataframe print(data) # Replace NA with 0 data[is.na(data)] = 0 print(data)
Producción:
Publicación traducida automáticamente
Artículo escrito por gottumukkalabobby y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA