Deep Convolutional GAN (DCGAN) fue propuesto por un investigador del MIT y Facebook AI research. Es ampliamente utilizado en muchas técnicas basadas en generación basadas en convolución. El enfoque de este documento fue hacer que los GAN de entrenamiento fueran estables. Por lo tanto, propusieron algunos cambios arquitectónicos en los problemas de visión por computadora. En este artículo, usaremos DCGAN en el conjunto de datos MNIST de moda para generar imágenes relacionadas con la ropa.
Necesidad de DCGAN:
Los DCGAN se introducen para reducir el problema del colapso del modo. El colapso del modo ocurre cuando el generador se sesga hacia unas pocas salidas y no puede producir salidas de cada variación del conjunto de datos. Por ejemplo, tome el caso del conjunto de datos de dígitos mnist (dígitos del 0 al 9), queremos que el generador genere todo tipo de dígitos, pero a veces nuestro generador se sesgó hacia dos o tres dígitos y solo los produjo. Debido a eso, el discriminador también se optimizó solo hacia esos dígitos en particular, y este estado se conoce como colapso de modo. Pero este problema se puede superar mediante el uso de DCGAN.
Arquitectura :
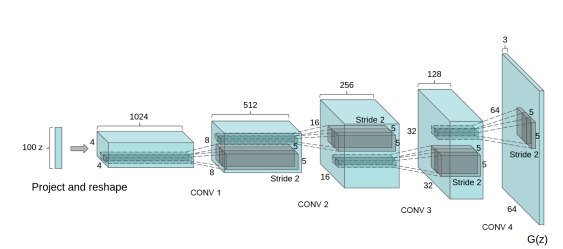
El generador de la arquitectura DCGAN toma 100 valores uniformes generados usando distribución normal como entrada. Primero, cambia la dimensión a 4x4x1024 y realiza una convolución fraccionalmente zancada 4 veces con una zancada de 1/2 (esto significa que cada vez que se aplica, duplica la dimensión de la imagen y reduce el número de canales de salida). La salida generada tiene dimensiones de (64, 64, 3). Hay algunos cambios arquitectónicos propuestos en el generador, como la eliminación de todas las capas completamente conectadas y el uso de Normalización por lotes que ayuda a estabilizar el entrenamiento. En este documento, los autores utilizan la función de activación de ReLU en todas las capas del generador, excepto en las capas de salida. Implementaremos el generador con pautas similares pero no completamente con la misma arquitectura.
El papel del discriminador aquí es determinar que la imagen proviene de un conjunto de datos real o de un generador. El discriminador puede diseñarse simplemente de forma similar a una red neuronal de convolución que realiza una tarea de clasificación de imágenes. Sin embargo, los autores de este artículo sugirieron algunos cambios en la arquitectura del discriminador. En lugar de capas completamente conectadas, usaron solo circunvoluciones estriadas con LeakyReLU como función de activación, la entrada del generador es una sola imagen del conjunto de datos o imagen generada y la salida es una puntuación que determina si la imagen es real o generada .
Implementación:
En esta sección, discutiremos la implementación de DCGAN en Keras, ya que nuestro conjunto de datos en el conjunto de datos Fashion MNIST, este conjunto de datos contiene imágenes de tamaño (28, 28) de 1 canal de color en lugar de (64, 64) de 3 canales de color. Entonces, necesitamos hacer algunos cambios en la arquitectura, discutiremos estos cambios a medida que avanzamos.
En el primer paso, debemos importar las clases necesarias, como TensorFlow, Keras, matplotlib, etc. Usaremos la versión 2 de TensorFlow. Esta versión de TensorFlow brinda soporte incorporado para la biblioteca Keras como su API de alto nivel predeterminada.
python3
# code % matplotlib inline
import tensorflow as tf
from tensorflow import keras
import numpy as np
import matplotlib.pyplot as plt
from tqdm import tqdm
from IPython import display
# Check tensorflow version
print('Tensorflow version:', tf.__version__)
Ahora cargamos el conjunto de datos fashion-MNIST, lo bueno es que el conjunto de datos se puede importar desde la API tf.keras.datasets. Por lo tanto, no necesitamos cargar conjuntos de datos manualmente copiando archivos. Este conjunto de datos contiene 60 000 imágenes de entrenamiento y 10 000 imágenes de prueba para cada dimensión (28, 28, 1). Como el valor de cada píxel está en el rango (0, 255), dividimos estos valores por 255 para normalizarlo.
python3
(x_train, y_train), (x_test, y_test) = tf.keras.datasets.fashion_mnist.load_data() x_train = x_train.astype(np.float32) / 255.0 x_test = x_test.astype(np.float32) / 255.0 x_train.shape, x_test.shape
((60000, 28, 28), (10000, 28, 28))
Ahora, en el siguiente paso, visualizaremos algunas de las imágenes del conjunto de fechas Fashion-MNIST, usamos la biblioteca matplotlib para eso.
python3
# We plot first 25 images of training dataset plt.figure(figsize =(10, 10)) for i in range(25): plt.subplot(5, 5, i + 1) plt.xticks([]) plt.yticks([]) plt.grid(False) plt.imshow(x_train[i], cmap = plt.cm.binary) plt.show()

Imágenes originales del MNIST de moda
Ahora, definimos parámetros de entrenamiento como el tamaño del lote y dividimos el conjunto de datos en lotes, y llenamos esos lotes muestreando aleatoriamente los datos de entrenamiento.
python3
# code batch_size = 32 # This dataset fills a buffer with buffer_size elements, # then randomly samples elements from this buffer, # replacing the selected elements with new elements. def create_batch(x_train): dataset = tf.data.Dataset.from_tensor_slices(x_train).shuffle(1000) # Combines consecutive elements of this dataset into batches. dataset = dataset.batch(batch_size, drop_remainder = True).prefetch(1) # Creates a Dataset that prefetches elements from this dataset return dataset
Ahora, definimos la arquitectura del generador, esta arquitectura del generador toma un vector de tamaño 100 y primero lo remodela en un vector (7, 7, 128) y luego aplica la convolución de transposición en esa imagen remodelada en combinación con la normalización por lotes. La salida de este generador es una imagen entrenada de dimensión (28, 28, 1).
python3
# code num_features = 100 generator = keras.models.Sequential([ keras.layers.Dense(7 * 7 * 128, input_shape =[num_features]), keras.layers.Reshape([7, 7, 128]), keras.layers.BatchNormalization(), keras.layers.Conv2DTranspose( 64, (5, 5), (2, 2), padding ="same", activation ="selu"), keras.layers.BatchNormalization(), keras.layers.Conv2DTranspose( 1, (5, 5), (2, 2), padding ="same", activation ="tanh"), ]) generator.summary()
Model: "sequential" _________________________________________________________________ Layer (type) Output Shape Param # ================================================================= dense (Dense) (None, 6272) 633472 _________________________________________________________________ reshape (Reshape) (None, 7, 7, 128) 0 _________________________________________________________________ batch_normalization (BatchNo (None, 7, 7, 128) 512 _________________________________________________________________ conv2d_transpose (Conv2DTran (None, 14, 14, 64) 204864 _________________________________________________________________ batch_normalization_1 (Batch (None, 14, 14, 64) 256 _________________________________________________________________ conv2d_transpose_1 (Conv2DTr (None, 28, 28, 1) 1601 ================================================================= Total params: 840, 705 Trainable params: 840, 321 Non-trainable params: 384 _________________________________________________________________
Ahora, definimos la arquitectura del discriminador, el discriminador toma una imagen de tamaño 28*28 con 1 canal de color y genera un valor escalar que representa una imagen del conjunto de datos o de la imagen generada.
python3
discriminator = keras.models.Sequential([ keras.layers.Conv2D(64, (5, 5), (2, 2), padding ="same", input_shape =[28, 28, 1]), keras.layers.LeakyReLU(0.2), keras.layers.Dropout(0.3), keras.layers.Conv2D(128, (5, 5), (2, 2), padding ="same"), keras.layers.LeakyReLU(0.2), keras.layers.Dropout(0.3), keras.layers.Flatten(), keras.layers.Dense(1, activation ='sigmoid') ]) discriminator.summary()
Model: "sequential_1" _________________________________________________________________ Layer (type) Output Shape Param # ================================================================= conv2d (Conv2D) (None, 14, 14, 64) 1664 _________________________________________________________________ leaky_re_lu (LeakyReLU) (None, 14, 14, 64) 0 _________________________________________________________________ dropout (Dropout) (None, 14, 14, 64) 0 _________________________________________________________________ conv2d_1 (Conv2D) (None, 7, 7, 128) 204928 _________________________________________________________________ leaky_re_lu_1 (LeakyReLU) (None, 7, 7, 128) 0 _________________________________________________________________ dropout_1 (Dropout) (None, 7, 7, 128) 0 _________________________________________________________________ flatten (Flatten) (None, 6272) 0 _________________________________________________________________ dense_1 (Dense) (None, 1) 6273 ================================================================= Total params: 212, 865 Trainable params: 212, 865 Non-trainable params: 0 _________________________________________________________________
Ahora necesitamos compilar nuestro modelo DCGAN (combinación de generador y discriminador), primero compilaremos el discriminador y estableceremos su entrenamiento en Falso, porque primero queremos entrenar el generador.
python3
# compile discriminator using binary cross entropy loss and adam optimizer discriminator.compile(loss ="binary_crossentropy", optimizer ="adam") # make discriminator no-trainable as of now discriminator.trainable = False # Combine both generator and discriminator gan = keras.models.Sequential([generator, discriminator]) # compile generator using binary cross entropy loss and adam optimizer gan.compile(loss ="binary_crossentropy", optimizer ="adam")
Ahora, definimos el procedimiento de entrenamiento para este modelo GAN, usaremos el paquete tqdm que hemos importado anteriormente. Este paquete ayuda a visualizar el entrenamiento.
python3
seed = tf.random.normal(shape =[batch_size, 100])
def train_dcgan(gan, dataset, batch_size, num_features, epochs = 5):
generator, discriminator = gan.layers
for epoch in tqdm(range(epochs)):
print()
print("Epoch {}/{}".format(epoch + 1, epochs))
for X_batch in dataset:
# create a random noise of sizebatch_size * 100
# to passit into the generator
noise = tf.random.normal(shape =[batch_size, num_features])
generated_images = generator(noise)
# take batch of generated image and real image and
# use them to train the discriminator
X_fake_and_real = tf.concat([generated_images, X_batch], axis = 0)
y1 = tf.constant([[0.]] * batch_size + [[1.]] * batch_size)
discriminator.trainable = True
discriminator.train_on_batch(X_fake_and_real, y1)
# Here we will be training our GAN model, in this step
# we pass noise that uses generatortogenerate the image
# and pass it with labels as [1] So, it can fool the discriminator
noise = tf.random.normal(shape =[batch_size, num_features])
y2 = tf.constant([[1.]] * batch_size)
discriminator.trainable = False
gan.train_on_batch(noise, y2)
# generate images for the GIF as we go
generate_and_save_images(generator, epoch + 1, seed)
generate_and_save_images(generator, epochs, seed)
Ahora definimos una función que genera y guarda imágenes del generador (durante el entrenamiento). Usaremos estas imágenes generadas para trazar el GIF más adelante.
python3
# code
def generate_and_save_images(model, epoch, test_input):
predictions = model(test_input, training = False)
fig = plt.figure(figsize =(10, 10))
for i in range(25):
plt.subplot(5, 5, i + 1)
plt.imshow(predictions[i, :, :, 0] * 127.5 + 127.5, cmap ='binary')
plt.axis('off')
plt.savefig('image_epoch_{:04d}.png'.format(epoch))
Ahora, necesitamos entrenar el modelo, pero antes de eso, también necesitamos crear lotes de datos de entrenamiento y agregar una dimensión que represente la cantidad de mapas de color.
python3
# reshape to add a color map x_train_dcgan = x_train.reshape(-1, 28, 28, 1) * 2. - 1. # create batches dataset = create_batch(x_train_dcgan) # callthe training function with 10 epochs and record time %% time train_dcgan(gan, dataset, batch_size, num_features, epochs = 10)
0%| | 0/10 [00:00<?, ?it/s] Epoch 1/10 10%|? | 1/10 [01:04<09:39, 64.37s/it] Epoch 2/10 20%|?? | 2/10 [02:10<08:39, 64.99s/it] Epoch 3/10 30%|??? | 3/10 [03:14<07:33, 64.74s/it] Epoch 4/10 40%|???? | 4/10 [04:19<06:27, 64.62s/it] Epoch 5/10 50%|????? | 5/10 [05:23<05:22, 64.58s/it] Epoch 6/10 60%|?????? | 6/10 [06:27<04:17, 64.47s/it] Epoch 7/10 70%|??????? | 7/10 [07:32<03:13, 64.55s/it] Epoch 8/10 80%|???????? | 8/10 [08:37<02:08, 64.48s/it] Epoch 9/10 90%|????????? | 9/10 [09:41<01:04, 64.54s/it] Epoch 10/10 100%|??????????| 10/10 [10:46<00:00, 64.61s/it] CPU times: user 7min 4s, sys: 33.3 s, total: 7min 37s Wall time: 10min 46s
Ahora definiremos una función que toma las imágenes guardadas y las convierte en GIF. Usamos esta función desde aquí
python3
import imageio
import glob
anim_file = 'dcgan_results.gif'
with imageio.get_writer(anim_file, mode ='I') as writer:
filenames = glob.glob('image*.png')
filenames = sorted(filenames)
last = -1
for i, filename in enumerate(filenames):
frame = 2*(i)
if round(frame) > round(last):
last = frame
else:
continue
image = imageio.imread(filename)
writer.append_data(image)
image = imageio.imread(filename)
writer.append_data(image)
display.Image(filename = anim_file)

Resultados de imágenes generadas
Resultados y Conclusión:
Para evaluar la calidad de las representaciones aprendidas por DCGAN para tareas supervisadas, los autores entrenan el modelo en ImageNet-1k y luego usan las funciones de convolución del discriminador de todas las capas, agrupando al máximo la representación de cada capa para producir una cuadrícula espacial de 4 × 4. Estas características luego se aplanan y se concatenan para formar un vector de 28672 dimensiones y un clasificador L2-SVM lineal regularizado se entrena sobre ellas. Este modelo luego se evalúa en el conjunto de datos CIFAR-10 pero no se entrena en él. El modelo reportó una precisión del 82 % que también muestra la robustez del modelo.
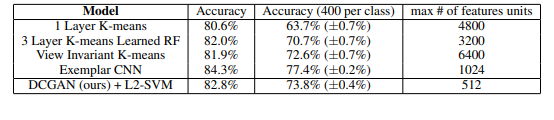
En el conjunto de datos Número de vivienda de Street View, logró una pérdida de validación del 22 %, que es la nueva arquitectura de discriminación uniforme de última generación cuando se supervisa y entrena como un modelo CNN tiene más pérdida de validación que ella.