Un procesador canalizado de 5 etapas tiene etapas de obtención de instrucciones (IF), decodificación de instrucciones (ID), obtención de operandos (OF), realización de operaciones (PO) y escritura de operandos (WO). Las etapas IF, ID, OF y WO toman 1 reloj ciclo cada uno para cualquier instrucción. La etapa PO toma 1 ciclo de reloj para las instrucciones ADD y SUB, 3 ciclos de reloj para la instrucción MUL y 6 ciclos de reloj para la instrucción DIV, respectivamente. necesarios para ejecutar la siguiente secuencia de instrucciones?
Instruction Meaning of instruction I0 :MUL R2 ,R0 ,R1 R2 ¬ R0 *R1 I1 :DIV R5 ,R3 ,R4 R5 ¬ R3/R4 I2 :ADD R2 ,R5 ,R2 R2 ¬ R5+R2 I3 :SUB R5 ,R2 ,R6 R5 ¬ R2-R6
(A) 13
(B) 15
(C) 17
(D) 19
Respuesta: (B)
Explicación: Reenvío de operandos: En esta técnica, el valor del operando se le da a la etapa en cuestión de la instrucción dependiente antes de que se almacene.
En la pregunta anterior, I2 depende de I0 e I1, e I3 depende de I2.
Veamos esta pregunta con un diagrama espacio-temporal.
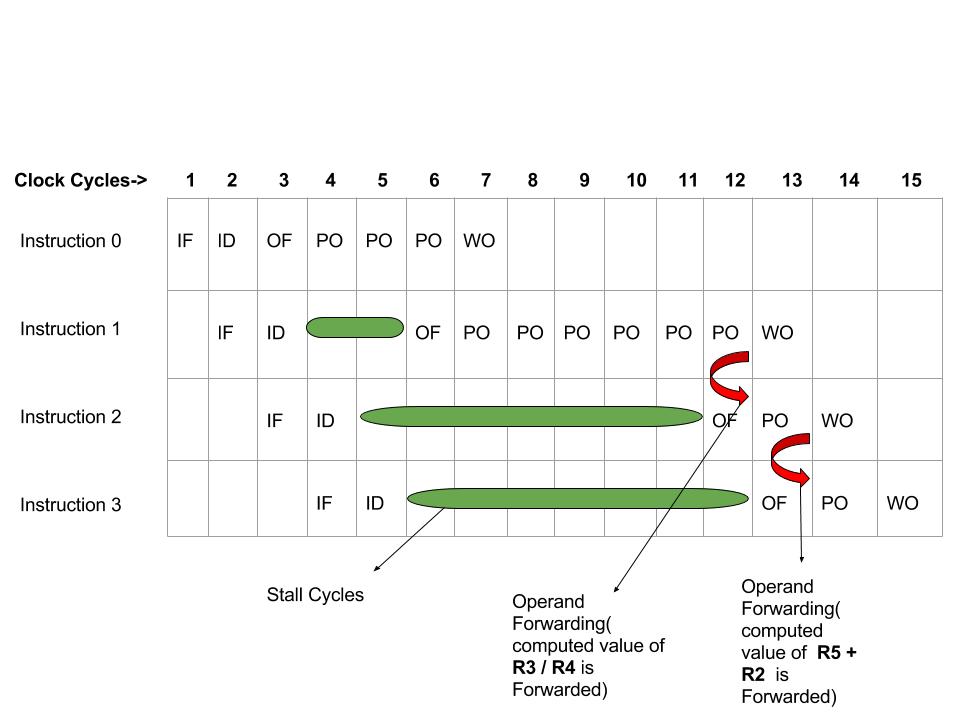
Lo anterior es un diagrama de espacio-tiempo que representa la tubería en la que se ejecutan las instrucciones.
La instrucción 0 es una operación MUL que toma 3 ciclos de reloj de CPU en la etapa PO, y en cualquier otra etapa toma solo 1 ciclo.
La instrucción 1 es una operación DIV que toma 6 ciclos de reloj de CPU en la etapa PO, y en cualquier otra etapa toma solo 1 ciclo.
Puede notarse aquí que incluso cuando la etapa OF estaba libre en el 4º ciclo de reloj, tampoco se le dio la instrucción 1. Este es un problema de diseño. Los operandos deben recuperarse solo si se van a operar o ejecutar en el próximo ciclo, de lo contrario, existe la posibilidad de corrupción de datos. Como la etapa PO no estaba libre en el siguiente ciclo, OF se retrasó y se realizó para la instrucción 1 solo justo antes de 1 ciclo de ir a la etapa PO.
La instrucción 2 es una operación SUMA que requiere 1 ciclo de reloj de la CPU en todas las etapas. Pero es una operación dependiente. necesita los operandos proporcionados por las instrucciones 0 y 1.
La instrucción 2 necesita R5 y R2 para agregar, obtiene R2 a tiempo, porque hasta el momento en que la Instrucción 2 llega a su etapa PO, R2 se habría almacenado en la memoria. Ahora también se necesita R5, pero el PO de la Instrucción 2 y el WO de la Instrucción 1 están en paralelo. Eso significa que la Instrucción 2 no puede tomar el valor de R5 antes de que la Instrucción 1 lo almacene. Así que aquí viene el concepto de reenvío de operandos. Antes de que la instrucción 1 almacene su resultado/valor, que es R5, primero puede reenviarlo al búfer de obtención y ejecución de la instrucción 2, de modo que la instrucción 2 también pueda usarlo en paralelo con la etapa WO de la instrucción. Esto ahorrará los ciclos de reloj adicionales requeridos (si no se usa el reenvío de operandos y es necesario tomar R5 de la memoria).
En la Instrucción 3, se aplica el mismo concepto de reenvío de operandos para el valor de R2 que se calcula mediante la Instrucción 2.
Por lo tanto, el reenvío de operandos ahorró 2 ciclos de reloj adicionales aquí. (1 ciclo en Instrucción 2 y 1 ciclo en Instrucción 3).
Entonces, el número total de ciclos es 15, lo que se puede ver en el diagrama, cada instancia de la etapa representa 1 ciclo de reloj. Así que total 15.
Cuestionario de esta pregunta
Publicación traducida automáticamente
Artículo escrito por GeeksforGeeks-1 y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA