Los metadatos pueden consistir en información confidencial. La esteganografía es la técnica en la que los datos confidenciales se ocultan en archivos pdf, png o, a veces, en archivos de video. Entonces, para obtener estos metadatos, podemos usar varias herramientas automatizadas. La herramienta Goblyn es una herramienta basada en el lenguaje Python que puede extraer varios tipos de archivos de dominios de destino como .pdf, .xml y también mostrar su información como tamaño, permisos, codificación, tipo MIME y mucho más. A veces, esta información puede brindar datos confidenciales, como nombres de usuario y contraseñas. Esta herramienta también está disponible en la plataforma GitHub de forma gratuita.
Nota : asegúrese de tener Python instalado en su sistema, ya que esta es una herramienta basada en Python. Haga clic para verificar el proceso de instalación: Pasos de instalación de Python en Linux
Instalación de la herramienta Goblyn en el sistema operativo Kali Linux
Paso 1 : use el siguiente comando para instalar la herramienta en su sistema operativo Kali Linux.
git clone https://github.com/loseys/Goblyn.git
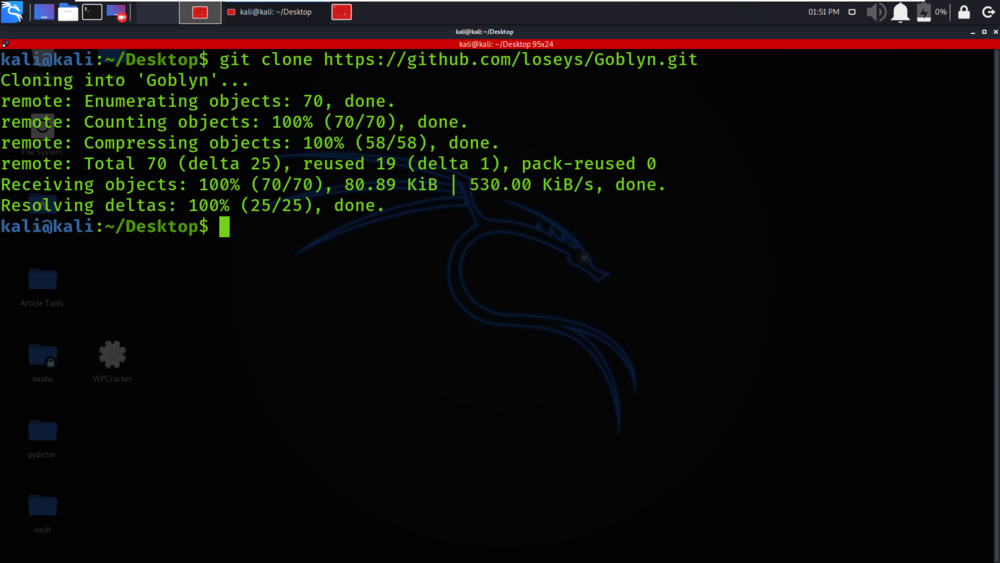
Paso 2 : ahora use el siguiente comando para moverse al directorio de la herramienta. Tienes que moverte en el directorio para ejecutar la herramienta.
cd Goblyn
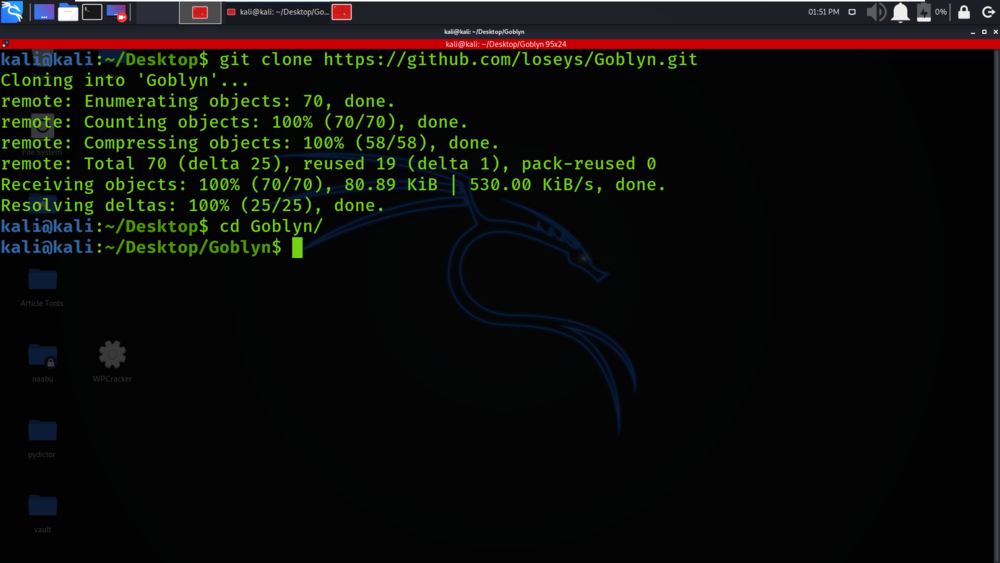
Paso 3 : Estás en el directorio de Goblyn. Ahora debe instalar la herramienta Goblyn usando el siguiente comando.
sudo python3 setup.py install
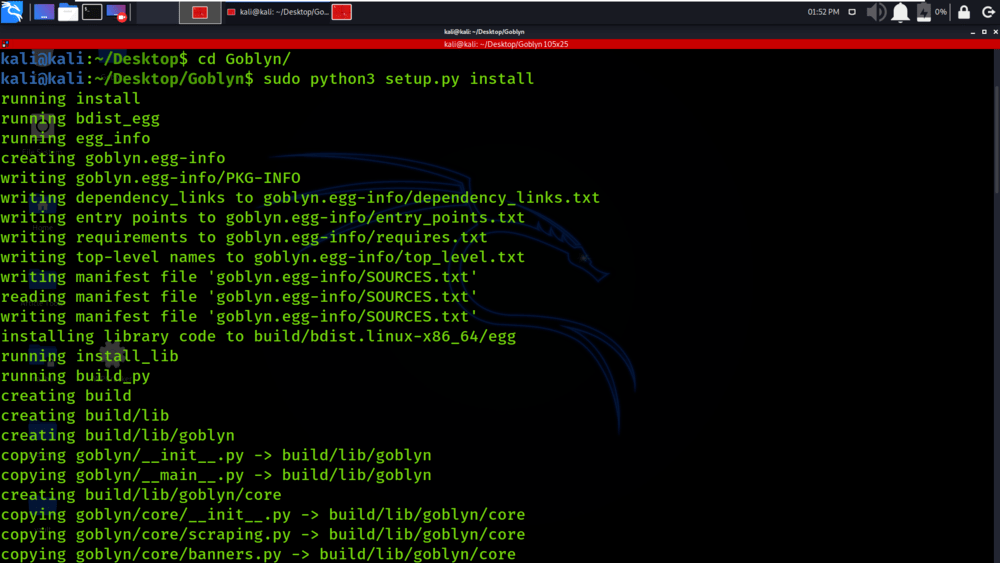
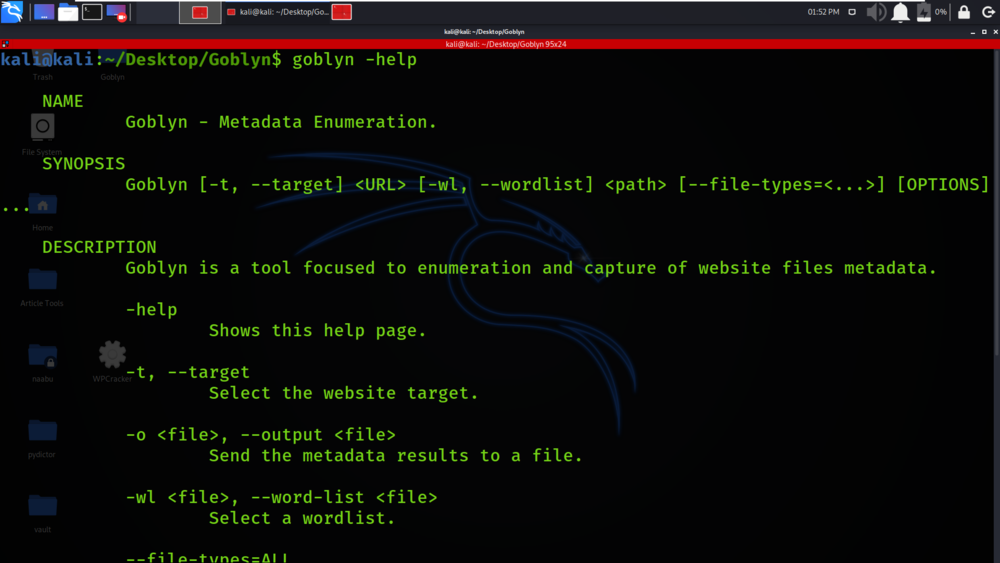
Paso 4 : todas las dependencias se han instalado en su sistema operativo Kali Linux. Ahora use el siguiente comando para ejecutar la herramienta y verifique la sección de ayuda.
goblyn -help
Trabajar con la herramienta Goblyn en el sistema operativo Kali Linux
Ejemplo: extracción de metadatos de geeksforgeeks.org.
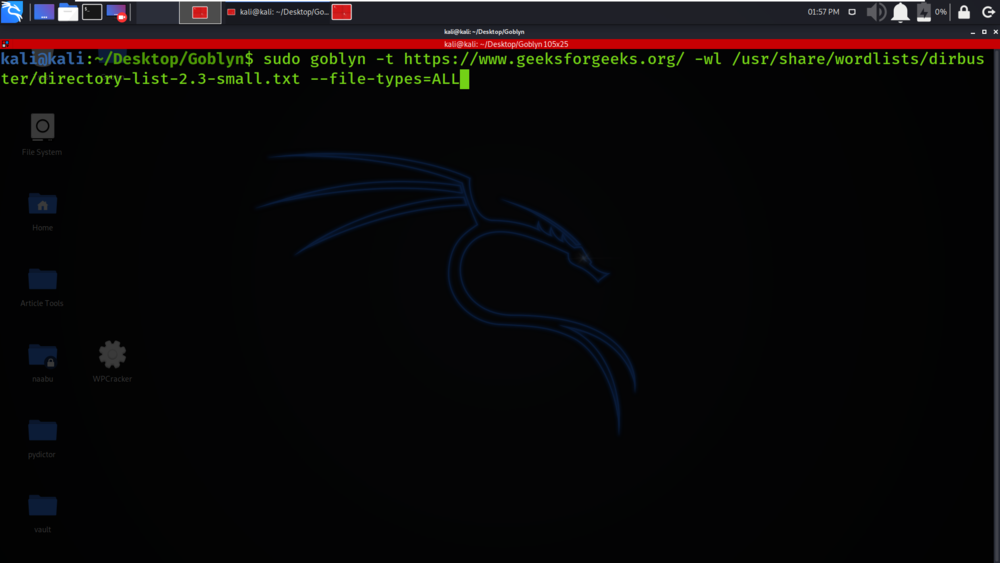
sudo goblyn -t https://www.geeksforgeeks.org/ -wl /usr/share/wordlists/dirbuster/directory-list-2.3-small.txt –file-types=ALL
Hemos mostrado el contenido de las listas de palabras que se enumerarán para encontrar directorios y archivos.
Hemos dado el comando en el que hemos especificado el objetivo como https://www.geeksforgeeks.org/, hemos dado la ruta absoluta de la lista de palabras y hemos dado el tipo de archivo como TODOS. También puede especificar el tipo de archivo como .pdf, .png y muchos más.
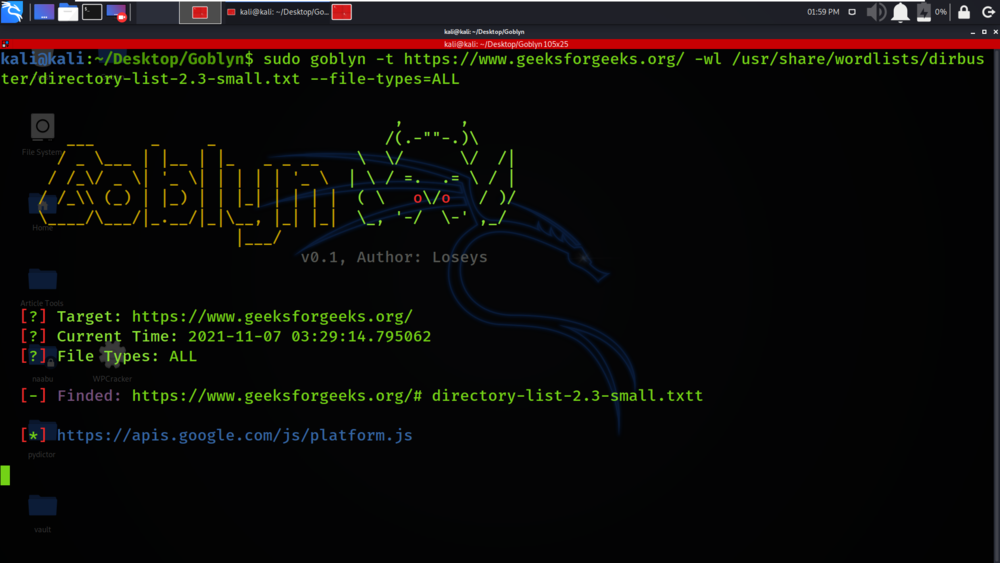
La herramienta ha iniciado el proceso de extracción de metadatos.
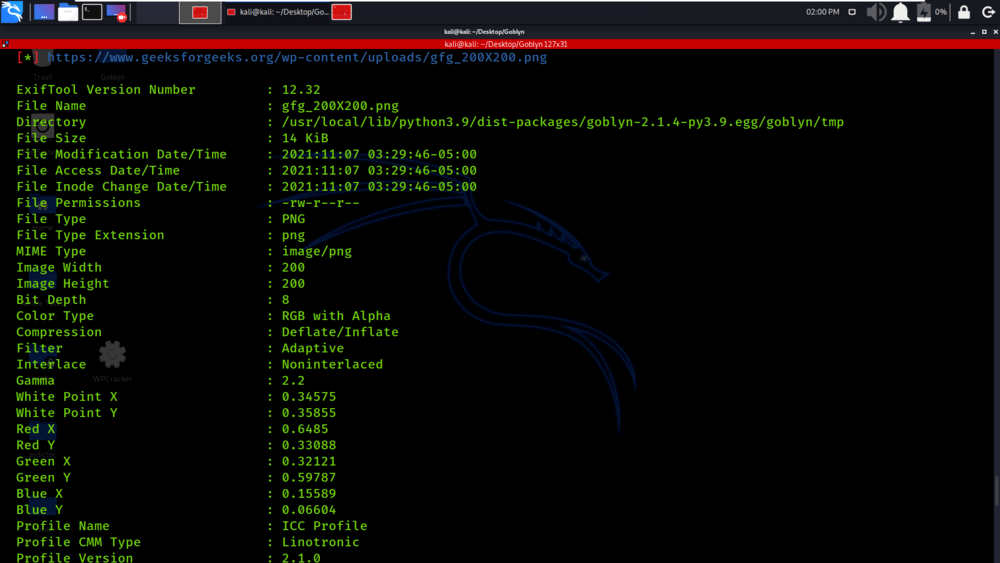
Tenemos el enlace del archivo y los detalles de ese archivo.
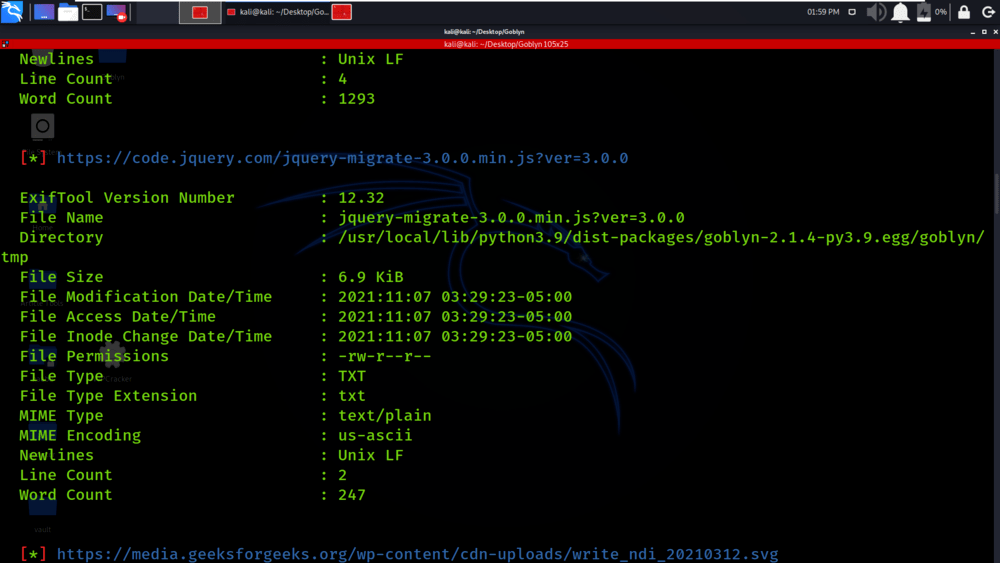
Puede ver que se muestra información detallada sobre el archivo en la siguiente captura de pantalla.
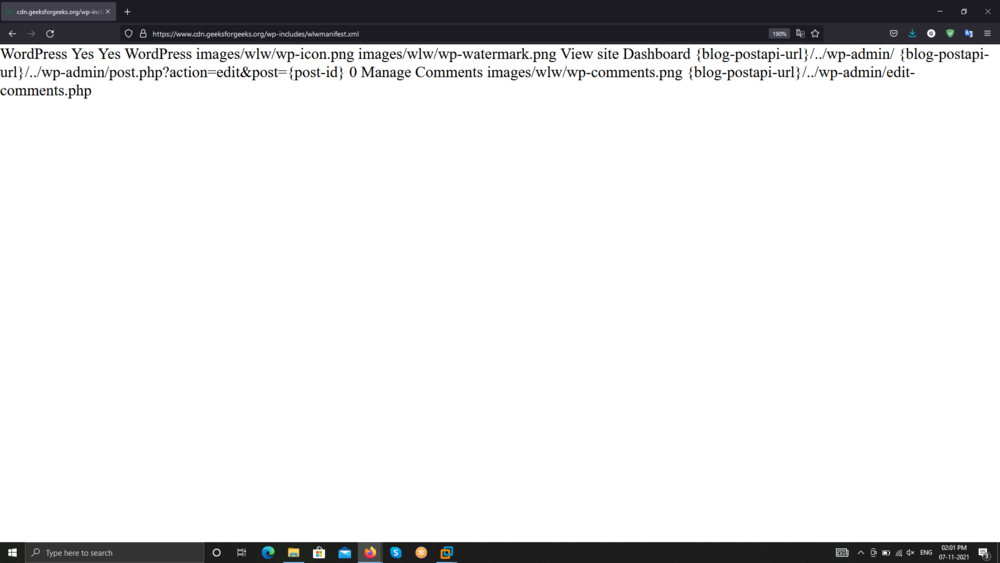
Hemos abierto uno de los archivos en el navegador web que es un archivo XML.
Publicación traducida automáticamente
Artículo escrito por gauravgandal y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA