El crowdsourcing tiene una amplia gama de beneficios. Ya sean reseñas de restaurantes que nos ayuden a encontrar un lugar perfecto para cenar o financiación colectiva para revivir nuestro programa de televisión favorito, estas contribuciones distribuidas se combinaron para crear algunas herramientas muy útiles.
También podemos usar ese mismo concepto para construir mejores modelos de aprendizaje automático. En este artículo, vamos a examinar un enfoque diferente del aprendizaje automático. Los enfoques estándar de aprendizaje automático requieren centralizar los datos de entrenamiento en un almacén común. Entonces, digamos que queremos entrenar un modelo de predicción de teclado basado en las interacciones del usuario. Tradicionalmente, implementamos inteligencia recopilando todos los datos en el servidor, creando un modelo y luego sirviéndolo. Todos los clientes hablan con el servidor para hacer predicciones. El modelo y los datos están todos en una ubicación central, lo que lo hace extremadamente fácil.
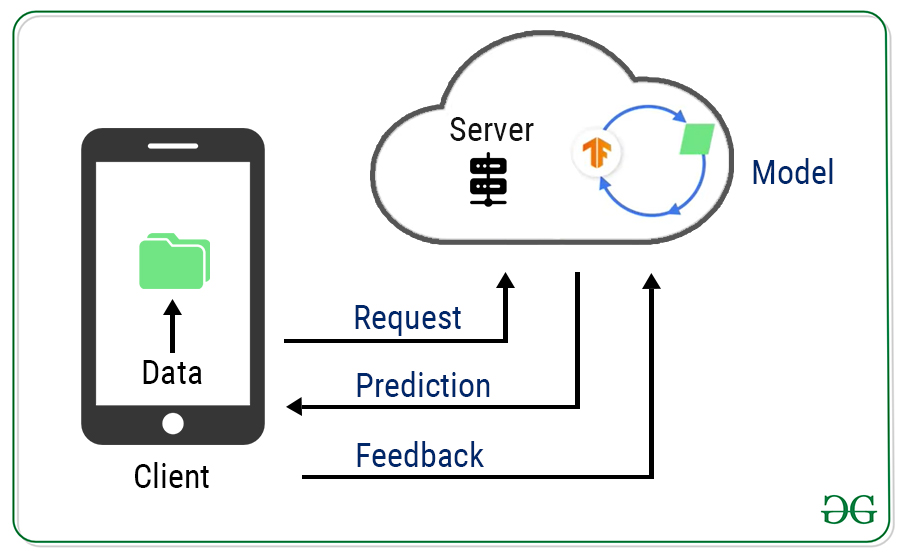
Pero la desventaja de esta configuración centralizada es que esta comunicación de ida y vuelta puede dañar la experiencia del usuario debido a la latencia de la red, la conectividad, la duración de la batería y todo tipo de problemas impredecibles.
Una forma de resolver esto es hacer que cada cliente entrene de forma independiente su propio modelo utilizando sus propios datos directamente en el dispositivo. No es necesaria ninguna comunicación.
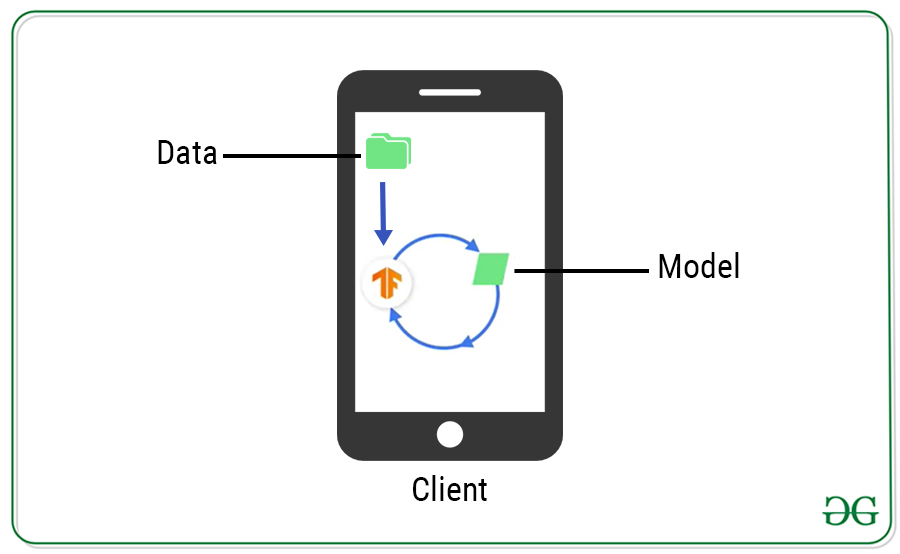
Pero esto tiene un problema ya que cada dispositivo individual no tiene suficientes datos para generar un buen modelo. Pero podría entrenar previamente el modelo en el servidor y luego implementarlo.

Pero el problema con eso es que, en nuestro ejemplo de teclado inteligente, digamos que si todos comenzaran a usar una nueva palabra de moda hoy, entonces el modelo entrenado con los datos de ayer no será tan útil.
Para utilizar la bondad de los datos descentralizados mientras se mantiene la privacidad de los usuarios, podemos hacer uso del aprendizaje federado . La idea central detrás del aprendizaje federado es el aprendizaje descentralizado , donde los datos del usuario nunca se envían a un servidor central.
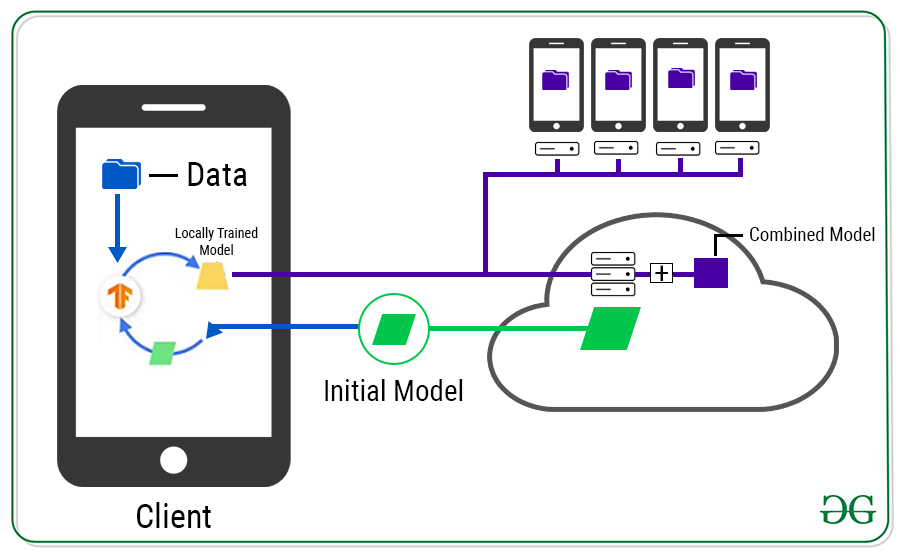
Comienza con un modelo en el servidor, lo distribuye a los clientes.
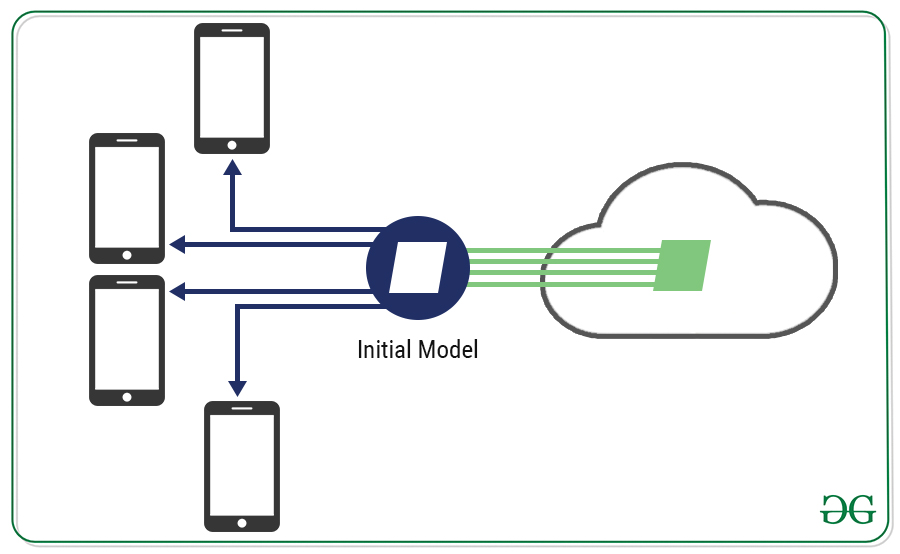
Pero no puede simplemente implementar en todos los clientes porque no desea interrumpir la experiencia del usuario. Identificará estos clientes en función de cuáles están disponibles, conectados y no en uso. Luego, averigüe también cuáles son los adecuados porque no todos los clientes tendrán datos suficientes. Una vez que haya identificado los dispositivos adecuados, podemos implementar el modelo en ellos. Ahora, cada cliente entrena el modelo localmente utilizando sus propios datos locales y produce un nuevo modelo, que se envía al servidor.
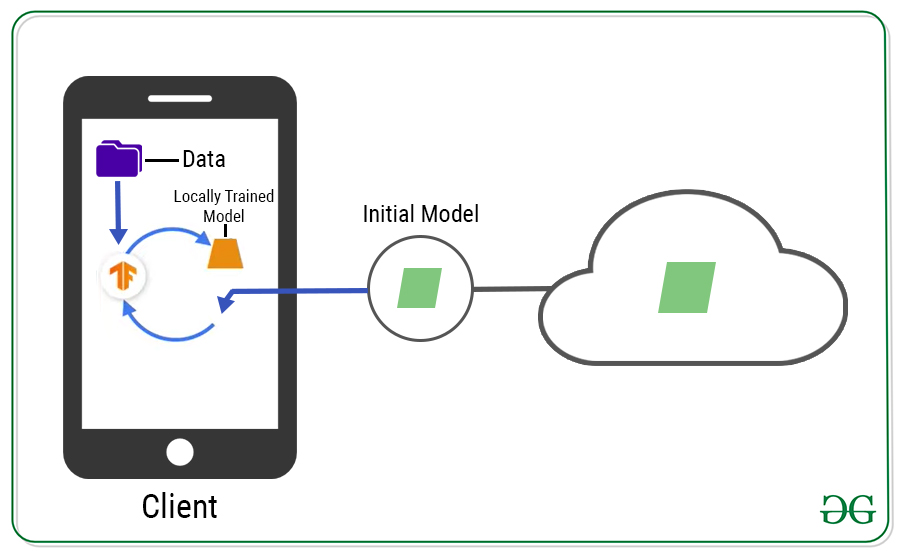
Lo que debe saber aquí es que los datos utilizados para entrenar el modelo en el dispositivo individual nunca salen del dispositivo. Solo los pesos, sesgos y otros parámetros aprendidos por el modelo salen del dispositivo.
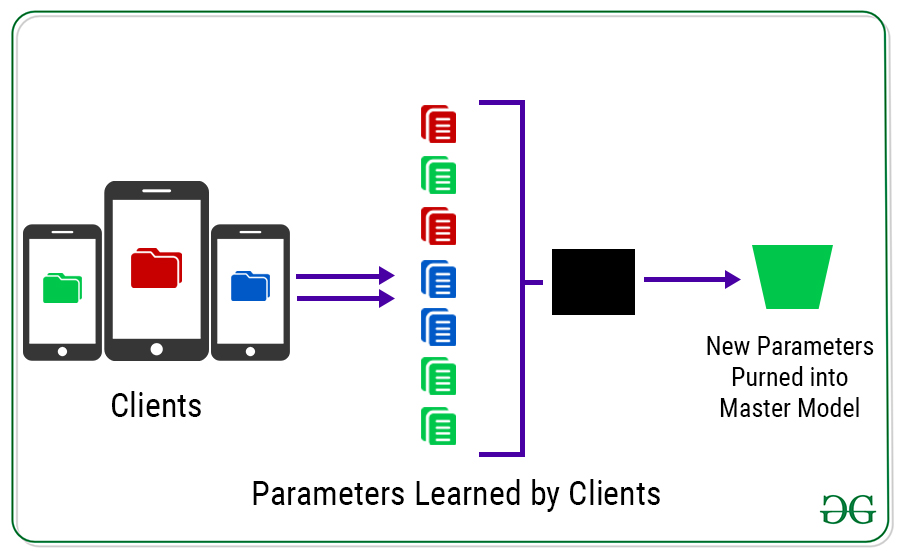
Luego, el servidor obtiene todos los modelos entrenados localmente y los promedia, creando efectivamente un nuevo modelo maestro.
Hacer esto una vez no es suficiente. Tenemos que hacerlo una y otra vez para que el modelo combinado se convierta en el modelo inicial para la próxima ronda. Y con cada ronda, el modelo combinado mejora un poco gracias a los datos de todos esos clientes.
Si usó Google Keyboard, Gboard, entonces ya vio y experimentó un caso de uso de aprendizaje federado. Gboard muestra una consulta sugerida, su teléfono almacena localmente información sobre el contexto actual y si hizo clic en la sugerencia.
El aprendizaje federado procesa ese historial en el dispositivo para sugerir mejoras para la próxima iteración del modelo de sugerencia de consulta de Gboard.
Publicación traducida automáticamente
Artículo escrito por ddeevviissaavviittaa y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA