A los desarrolladores les encanta la tecnología sin servidor. Prefieren centrarse en el código, la implementación y dejar que la plataforma se encargue del resto. Cloud Run , le permite ejecutar cualquier contenedor sin estado sin servidor. Con Cloud Run, puedes olvidarte de la infraestructura. Se enfoca en un escalado rápido y automático que tiene en cuenta las requests, por lo que puede escalar a cero y pagar solo cuando se usa.
Para explicar este concepto, tomemos un ejemplo. Aquí vamos a implementar un microservicio sin servidor que transforma documentos de Word en PDF. Para realizar esta transformación, necesitaremos OpenOffice . Simplemente agregaremos OpenOffice dentro de nuestro contenedor y luego lo ejecutaremos en un entorno sin servidor.
Saltemos a ello. Desde la consola, vaya a Cloud Run y abra la página de Implementación.
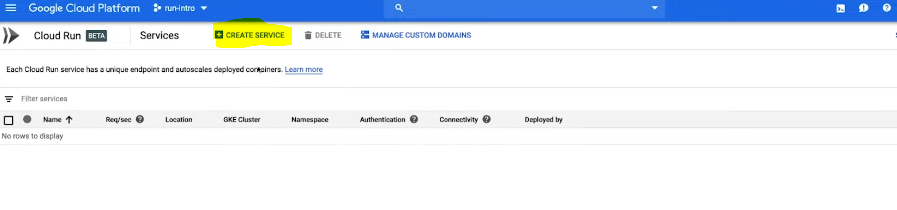
Seleccione o pegue la URL de la imagen del contenedor y haga clic en Crear .
Eso es todo lo que necesitábamos para crear un contenedor sin servidor. Sin infraestructura para aprovisionar por adelantado, sin archivo YAML y sin servidores.
Cloud Run importó nuestra imagen, se aseguró de que se inició y reunió un punto final HTTPS estable y seguro.
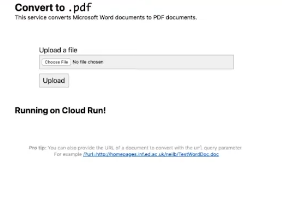
Lo que acabamos de implementar es un microservicio escalable que transforma un documento en un PDF. Veámoslo en acción dándole un documento para convertir cargando el mismo en el microservicio en ejecución.
OpenOffice no es exactamente un software moderno. Se trata de un binario de 15 años y tiene unos 200 megabytes. Y simplemente tomamos ese binario y lo implementamos como una carga de trabajo sin servidor con Cloud Run, porque Cloud Run admite contenedores Docker. Eso significa que puede ejecutar cualquier lenguaje de programación que desee o cualquier software sin servidor.
Veamos el código. Tenemos una pequeña pieza de código de Python que escucha las requests HTTP entrantes y llama a OpenOffice para convertir nuestro documento.
Python3
# python program to convert
# docs into pdf
import os
import shutil
import requests
import tempfile
from gevent.pywsgi import WSGIServer
from flask import Flask, after_this_request, render_template, request, send_file
from subprocess import call
UPLOAD_FOLDER = '/tmp'
ALLOWED_EXTENSIONS = set(['doc', 'docx', 'xls', 'xlsx'])
app = Flask(__name__)
# Convert using Libre Office
def convert_file(output_dir, input_file):
call('libreoffice --headless --convert-to pdf --outdir %s %s ' %
(output_dir, input_file), shell=True)
def allowed_file(filename):
return '.' in filename and \
filename.rsplit('.', 1)[1].lower() in ALLOWED_EXTENSIONS
@app.route('/', methods=['GET', 'POST'])
def api():
work_dir = tempfile.TemporaryDirectory()
file_name = 'document'
input_file_path = os.path.join(work_dir.name, file_name)
# Libreoffice is creating files with the same name but .pdf extension
output_file_path = os.path.join(work_dir.name, file_name + '.pdf')
if request.method == 'POST':
# check if the post request has the file part
if 'file' not in request.files:
return 'No file provided'
file = request.files['file']
if file.filename == '':
return 'No file provided'
if file and allowed_file(file.filename):
file.save(input_file_path)
if request.method == 'GET':
url = request.args.get('url', type=str)
if not url:
return render_template('index.html')
# Download from URL
response = requests.get(url, stream=True)
with open(input_file_path, 'wb') as file:
shutil.copyfileobj(response.raw, file)
del response
convert_file(work_dir.name, input_file_path)
@after_this_request
def cleanup(response):
work_dir.cleanup()
return response
return send_file(output_file_path, mimetype='application/pdf')
if __name__ == "__main__":
http_server = WSGIServer(('', int(os.environ.get('PORT', 8080))), app)
http_server.serve_forever()
Y también tenemos un archivo Docker muy pequeño . Comienza definiendo nuestra imagen base.
FROM python:3-alpine
ENV APP_HOME /app
WORKDIR $APP_HOME
RUN apk add libreoffice \
build-base \
# Install fonts
msttcorefonts-installer fontconfig && \
update-ms-fonts && \
fc-cache -f
RUN apk add --no-cache build-base libffi libffi-dev && pip install cffi
RUN pip install Flask requests gevent
COPY . $APP_HOME
# prevent libreoffice from querying ::1 (ipv6 ::1 is rejected until istio 1.1)
RUN mkdir -p /etc/cups && echo "ServerName 127.0.0.1" > /etc/cups/client.conf
CMD ["python", "to-pdf.py"]
En nuestro caso, es la imagen oficial basada en Python. Posteriormente, instalamos OpenOffice y especificamos nuestro comando de inicio. Luego, empaquetamos todo esto en una imagen de contenedor con Cloud Build y lo implementamos en Cloud Run. En Cloud Run, nuestro microservicio se puede escalar automáticamente a miles de contenedores o instancias en solo unos segundos. Simplemente tomamos una aplicación heredada y la implementamos en un entorno de microservicio sin ningún cambio en el código.
Pero a veces es posible que desee tener un poco más de control. Por ejemplo, tamaños de CPU más grandes, acceso a GPU, más memoria o tal vez ejecutarlo en un clúster de Kubernetes Engine. Con Cloud Run en GKE, usa exactamente la misma interfaz. Vamos a implementar exactamente la misma imagen de contenedor, esta vez en GKE.
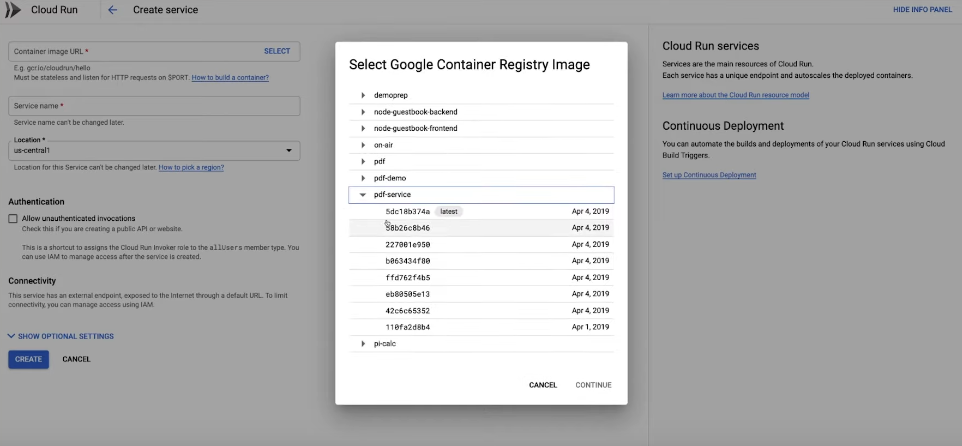
Y en lugar de una región totalmente administrada, ahora elegimos nuestro clúster de GKE. Obtenemos la misma experiencia de desarrollador de Cloud Run que antes. Obtenemos un punto final estable y seguro que escala automáticamente nuestro microservicio.
Detrás de escena, Cloud Run y Cloud Run en GKE cuentan con la tecnología de Knative, un proyecto de código abierto para ejecutar cargas de trabajo sin servidor que se lanzó el año pasado. Esto significa que podemos implementar exactamente el mismo microservicio en cualquier clúster de Kubernetes que se ejecute en Knative. Vamos a ver.
Exportamos el microservicio a un archivo, service.yaml . Luego, usando el siguiente comando, lo implementaremos en un Knative administrado en otro proveedor de nube.
kubectl apply - f service.yaml
Ingresaremos el siguiente comando para recuperar el punto final de la URL.
kubectl get ksvc
Ahora en otro proveedor de nube. Veamos el servicio que se está ejecutando ingresando el siguiente comando:
gcloud beta run services describe pdf service
Si está familiarizado con Kubernetes, estas versiones y campos de API pueden parecerle familiares.
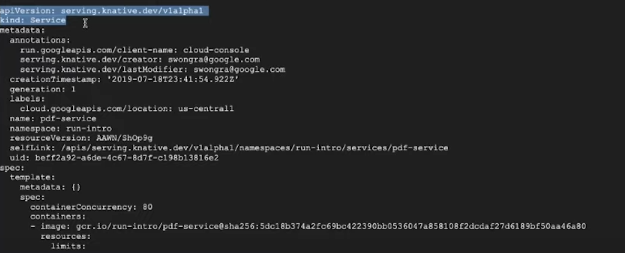
En este caso, no estamos usando Kubernetes. Pero dado que Cloud Run implementa la API de Knative, una extensión de Kubernetes, este es un objeto de API que se parece a Kubernetes. Knative permite que los servicios se ejecuten de forma portátil entre entornos sin depender de un proveedor. Cloud Run te ofrece todo lo que te gusta de la tecnología sin servidor. No hay servidores para administrar, puede permanecer en el código y hay una rápida ampliación y, lo que es más importante, una reducción a cero. No paga nada cuando no se ejecutan ciclos. Use cualquier binario o lenguaje, porque depende de la flexibilidad de los contenedores. Y te da acceso al ecosistema y las API de Google Cloud. Y obtiene una experiencia uniforme donde la desee, en un entorno totalmente administrado o en GKE.
Publicación traducida automáticamente
Artículo escrito por ddeevviissaavviittaa y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA