En este artículo, veremos la API de Kubernetes y cómo facilita el modelado del ciclo de vida de la aplicación. Repasemos los conceptos que hacen que Kubernetes sea usable, escalable y simplemente increíble.
Cuando se trata de lo que necesitan las aplicaciones escalables, hemos hablado de contenedores y Nodes, pero eso es solo la punta del iceberg. Hay mucho más que necesitamos para ejecutar una aplicación totalmente escalable. Ahí es donde entra en juego la API de Kubernetes. Ofrece algunas primitivas realmente convenientes que facilitan mucho la administración de aplicaciones nativas de la nube. Algunos objetos de API son pods y Nodes , implementaciones , secretos y muchos más.
Tomemos una aplicación de ejemplo. Establecimos que los contenedores son el primer paso para usar Kubernetes, así que comencemos con el contenedor que creamos para ejecutar una aplicación Hello. Esta aplicación es realmente simple. Simplemente devuelve «Hola» cada vez que alguien hace ping en su IP local en el puerto 8080.
Lo primero que tenemos que hacer es crear algunas máquinas, o Nodes, para ejecutar nuestra aplicación. Aquí usaremos Google Kubernetes Engine para comenzar rápidamente. Simplemente podemos usar la herramienta de línea de comandos de Gcloud para aprovisionar un clúster de Kubernetes usando el siguiente comando:
$ gcloud container cluster create hello-cluster
Después de unos minutos, tendremos un grupo. Por defecto, viene con tres Nodes.
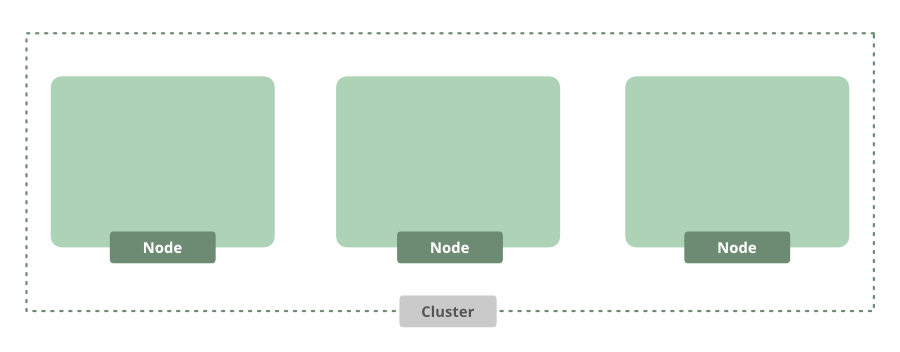
Este es un excelente punto de partida, pero ahora necesitamos ejecutar nuestra aplicación. Como estamos usando la línea de comandos, podemos usar una herramienta útil llamada kubectl para ayudar a interactuar con la API de Kubernetes usando el siguiente comando:
$ kubectl create deployment dbd --image \ mydb/example-db:1.0.0 --record
Este comando en realidad va a crear un objeto API de Kubernetes llamado implementación. Una implementación es una abstracción que gestiona el ciclo de vida de una aplicación. Podemos establecer la cantidad deseada de instancias de aplicaciones para que la implementación las administre, y luego se asegurará de que se esté ejecutando la cantidad correcta de instancias o réplicas.
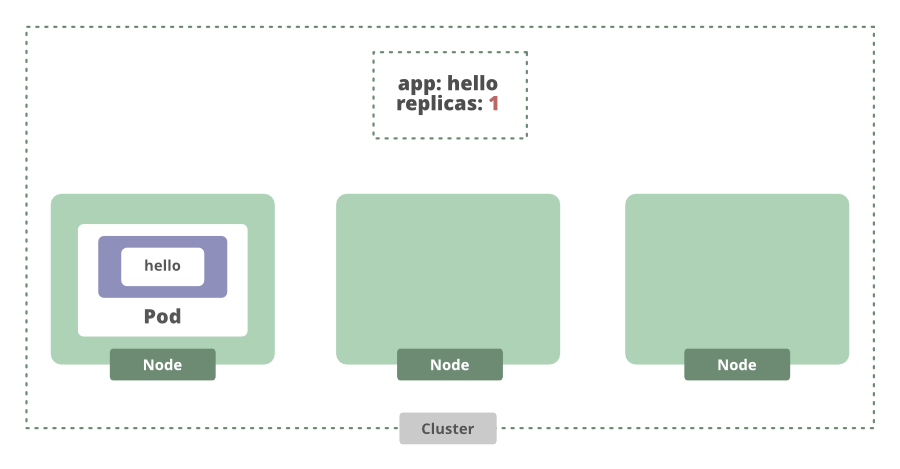
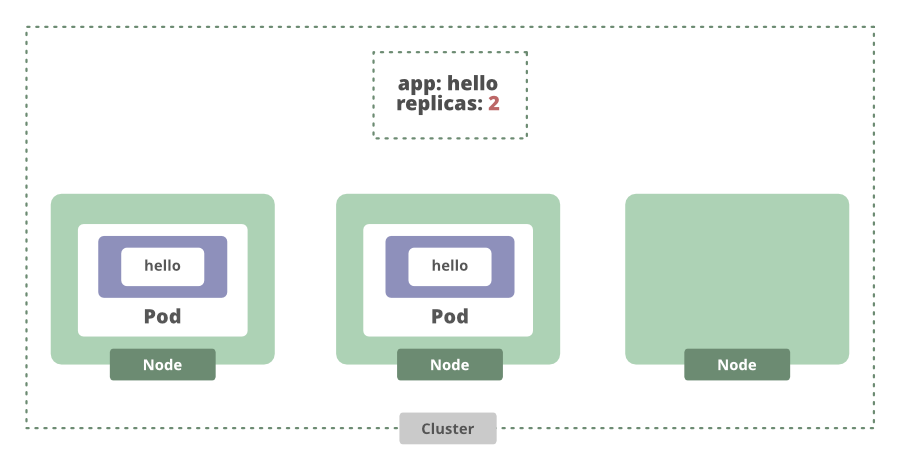
Si aumentamos la cantidad de réplicas que queremos, la implementación verá que actualmente no hay suficientes réplicas y generará otra.
Eso incluso funciona cuando un Node falla. Si el Node deja de funcionar, el estado actual vuelve a ser diferente del estado deseado y Kubernetes programará otra réplica para nosotros.
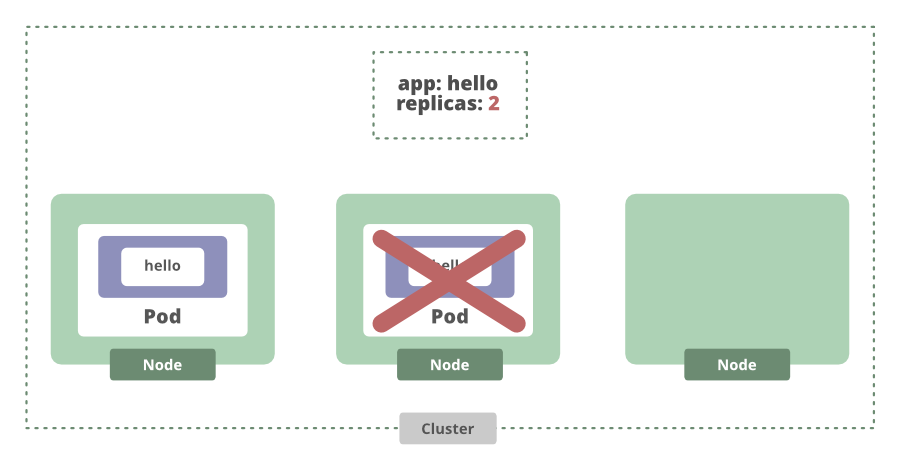
Ahora sabemos que nuestra aplicación se ejecuta en estos Nodes. Para acceder a él tendremos que crear un servicio usando el siguiente comando:
$ kubectl expose deployment dbd \ --port 80 --type Loadbalancer
Esto crea un punto final que podemos usar para acceder a las instancias de la aplicación en ejecución. En este caso, tenemos múltiples instancias de aplicaciones. Por lo tanto, este servicio equilibrará la carga de las requests entrantes entre los dos pods en ejecución. Para cualquier contenedor dentro del clúster, pueden conectarse a nuestro servicio utilizando el nombre del servicio. De cualquier manera, el servicio realiza un seguimiento de dónde se ejecuta el pod.
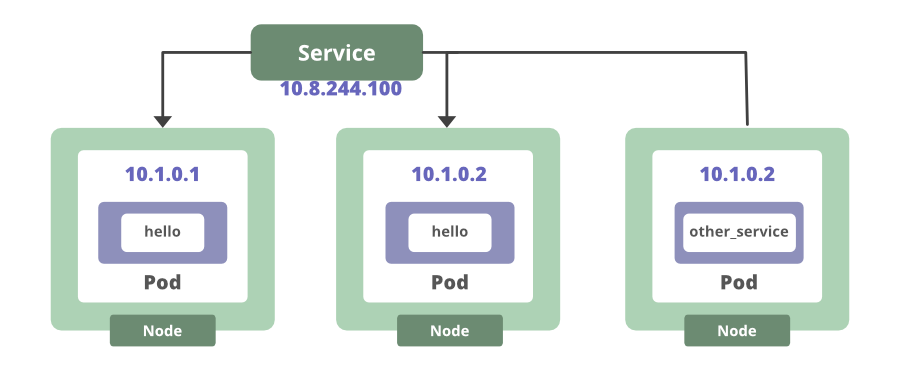
Ese es otro ejemplo de cómo Kubernetes elimina la necesidad de realizar un seguimiento manual de dónde se ejecutan sus contenedores. Incluso si un pod dejara de funcionar, una vez que uno nuevo vuelva a estar en línea, el servicio actualizará automáticamente su lista de puntos finales para apuntar al nuevo pod.
Los objetos de Kubernetes, como las implementaciones y los servicios, garantizan automáticamente que tengamos la cantidad correcta de instancias de aplicaciones ejecutándose en los pods y que siempre podamos acceder a ellas. Las características que solían tener que codificarse manualmente ahora se vuelven ideas de última hora cuando se usa Kubernetes. Por ejemplo, las implementaciones hacen que cosas como las actualizaciones continuas sean realmente simples. Podemos editar la implementación y ver cómo cambia la versión de las aplicaciones gradualmente. Entonces, digamos que tenemos tres réplicas y queremos sacar una nueva versión de nuestra aplicación que devuelva «Adiós» en lugar de «Hola». Podemos actualizar nuestro contenedor de aplicaciones, ver cómo se implementa gradualmente la nueva versión y la implementación generará nuevas instancias de aplicaciones y comenzará a redirigir el tráfico hacia ellas. Luego, una vez que el número deseado de instancias nuevas está en línea, las instancias de la aplicación anterior se desconectan.
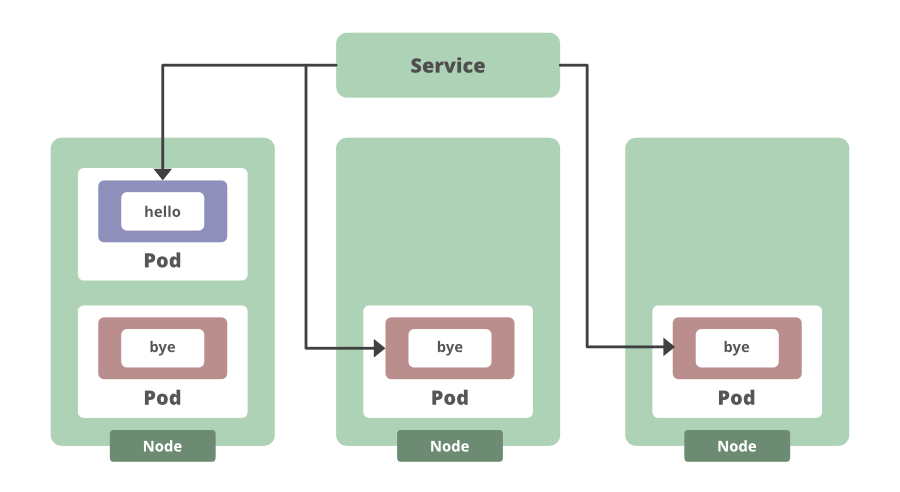
Esto significaría que este enfoque tiene cero tiempo de inactividad. Dado que Kubernetes está actualizando de forma incremental las instancias de pod antiguas con otras nuevas. Y una característica como esa, además de la capacidad de retroceder rápidamente si es necesario, y realizar un seguimiento de los historiales de implementación y más, todo eso está integrado en Kubernetes.
Eso es en gran parte lo que la convierte en una gran herramienta para construir otros sistemas y aplicaciones. La API de Kubernetes realmente facilita la gestión del ciclo de vida de la aplicación. Los pods, el servicio, las implementaciones de las primitivas básicas y algunas más permiten que los administradores de sistemas y los desarrolladores se concentren en la aplicación sin tener que preocuparse por administrarla a escala. Utilizamos un enfoque imperativo. Creamos comandos manuales, en lugar de utilizar un enfoque declarativo, que es uno de los grandes atractivos de Kubernetes.
Publicación traducida automáticamente
Artículo escrito por ddeevviissaavviittaa y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA