Plotly es una biblioteca de Python que se utiliza para diseñar gráficos, especialmente gráficos interactivos. Puede trazar varios gráficos y cuadros como histograma, diagrama de barras, diagrama de caja, diagrama de dispersión y muchos más. Se utiliza principalmente en el análisis de datos, así como en el análisis financiero. plotly es una biblioteca de visualización interactiva.
Gráfico circular
Un gráfico circular es un gráfico analítico circular, que se divide en regiones para simbolizar un porcentaje numérico. En px.pie, datos anticipados por los sectores del pastel para fijar los valores. Todos los sectores se clasifican en nombres. El gráfico circular se usa generalmente para mostrar el porcentaje con la siguiente porción correspondiente del pastel. El gráfico circular ayuda a comprender bien debido a sus diferentes porciones y códigos de colores.
Sintaxis: plotly.express.pie(data_frame=Ninguno, nombres=Ninguno, valores=Ninguno, color=Ninguno, color_discrete_sequence=Ninguno, color_discrete_map={}, hover_name=Ninguno, hover_data=Ninguno, custom_data=Ninguno, etiquetas={}, título=Ninguno, plantilla=Ninguno, ancho=Ninguno, alto=Ninguno, opacidad=Ninguno, agujero=Ninguno)
Parámetros:
| Nombre | Valor | Descripción |
|---|---|---|
| marco de datos | DataFrame o tipo array o dict | Este argumento debe pasarse para que se utilicen los nombres de las columnas (y no los nombres de las palabras clave). Array-like y dict se transforman internamente en un DataFrame de pandas. Opcional: si falta, un DataFrame se construye debajo del capó usando los otros argumentos |
| nombres | str o int o Serie o tipo array | Ya sea un nombre de una columna en data_frame, o una serie de pandas o un objeto similar a una array. Los valores de esta columna o array_like se utilizan como etiquetas para los sectores. |
| valores | str o int o Serie o tipo array | Ya sea un nombre de una columna en data_frame, o una serie de pandas o un objeto similar a una array. Los valores de esta columna o array_like se utilizan para establecer valores asociados a sectores. |
| color | str o int o Serie o tipo array | Ya sea un nombre de una columna en data_frame, o una serie de pandas o un objeto similar a una array. Los valores de esta columna o array_like se utilizan para asignar color a las marcas. |
Ejemplo:
Python3
import plotly.express as px import numpy # Random Data random_x = [100, 2000, 550] names = ['A', 'B', 'C'] fig = px.pie(values=random_x, names=names) fig.show()
Producción:
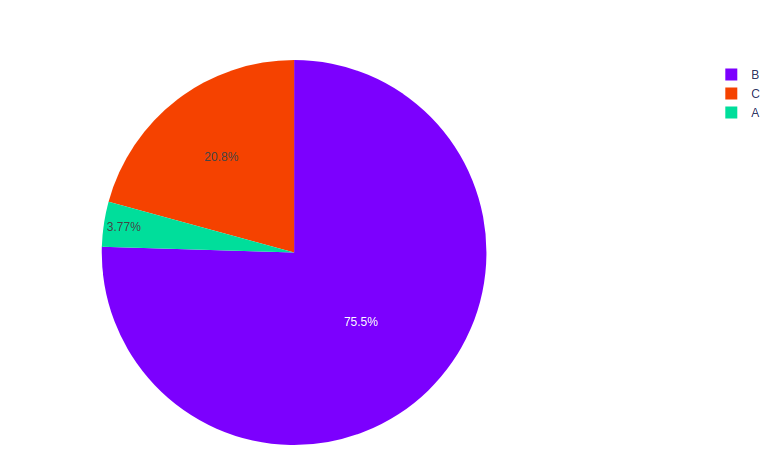
Agrupación de datos
El mismo valor para el parámetro de nombres se agrupan juntos. Las etiquetas repetidas agrupan visualmente filas o columnas para que los datos sean más fáciles de entender. Veamos un ejemplo dado a continuación.
Ejemplo: el conjunto de datos del iris contiene muchas filas pero solo 3 especies, por lo que los datos se agrupan según la especie.
Python3
import plotly.express as px # Loading the iris dataset df = px.data.iris() fig = px.pie(df, values="sepal_width", names="species") fig.show()
Producción:
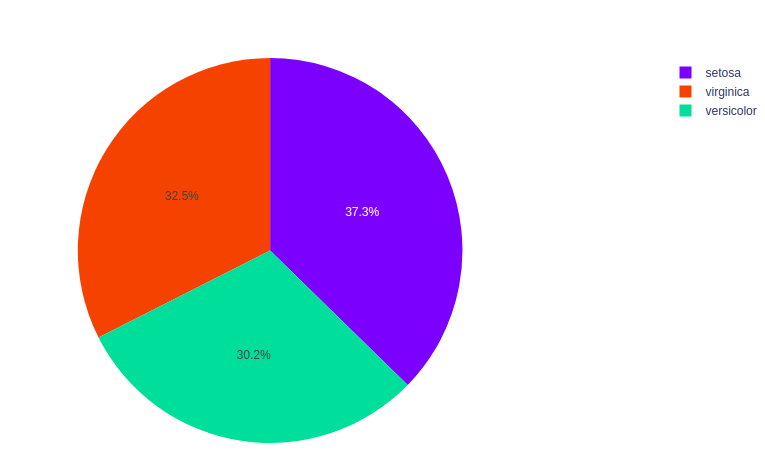
Personalización del gráfico circular
El gráfico circular se puede personalizar usando px.pie, usando algunos de sus parámetros, como hover_data y etiquetas. Veamos el siguiente ejemplo para una mejor comprensión.
Ejemplo:
Python3
import plotly.express as px # Loading the iris dataset df = px.data.iris() fig = px.pie(df, values="sepal_width", names="species", title='Iris Dataset', hover_data=['sepal_length']) fig.show()
Producción:
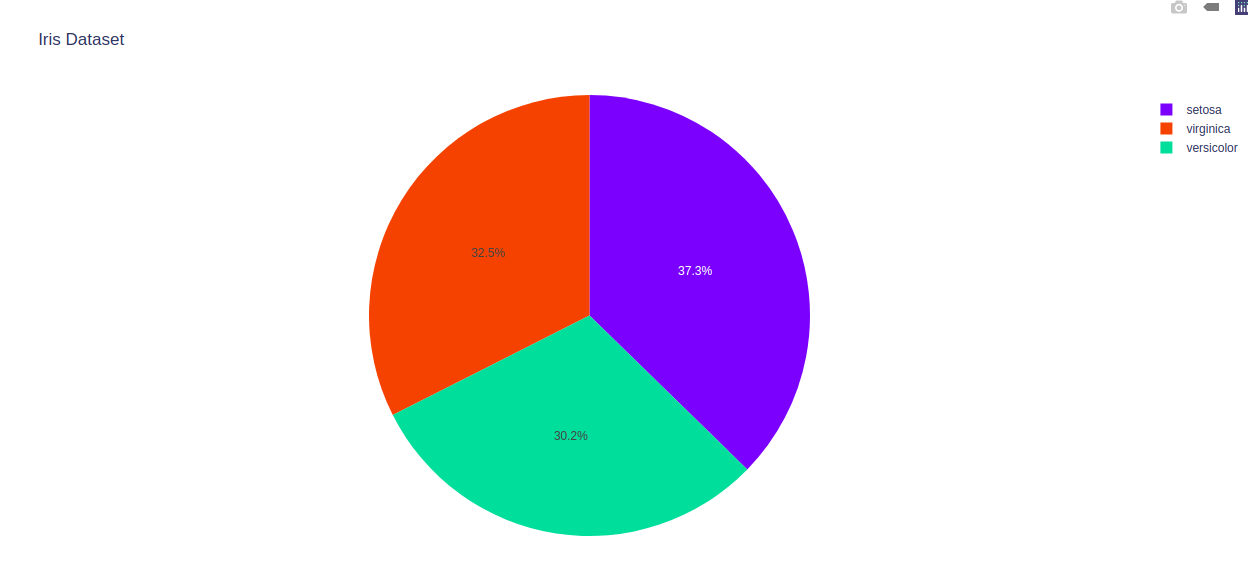
Configuración de colores
El color del pastel se puede cambiar en el módulo plotly. Los diferentes colores ayudan a distinguir los datos entre sí, lo que ayuda a comprender los datos de manera más eficiente.
Ejemplo:
Python3
import plotly.express as px # Loading the iris dataset df = px.data.iris() fig = px.pie(df, values="sepal_width", names="species", color_discrete_sequence=px.colors.sequential.RdBu) fig.show()
Producción:
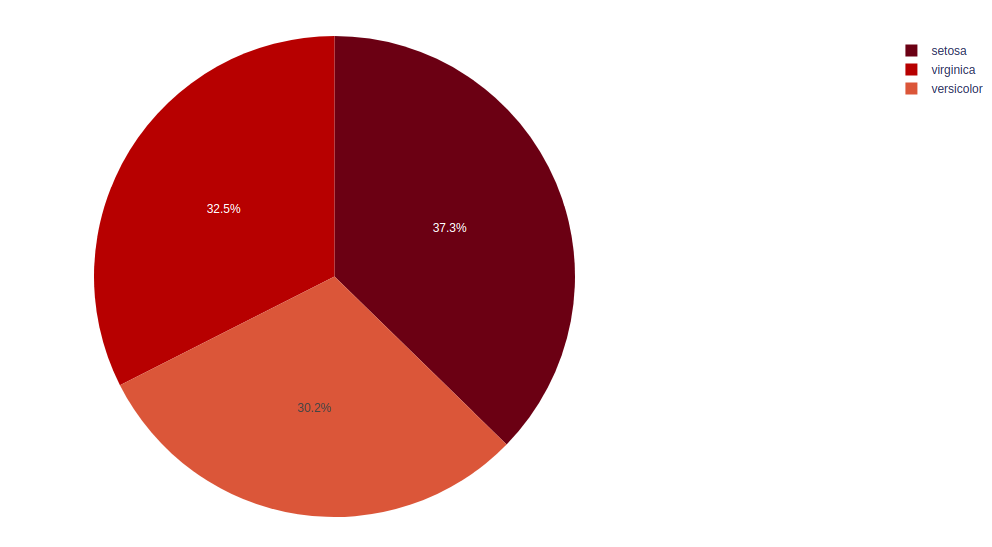
Publicación traducida automáticamente
Artículo escrito por nishantsundriyal98 y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA