Density Plot es un tipo de herramienta de visualización de datos. Es una variación del histograma que utiliza el «suavizado del núcleo» al trazar los valores. Es una versión continua y suave de un histograma inferido de un dato.
Los diagramas de densidad utilizan la estimación de densidad de kernel (por lo que también se conocen como diagramas de estimación de densidad de kernel o KDE), que es una función de densidad de probabilidad. La región de la gráfica con un pico más alto es la región con puntos de datos máximos que residen entre esos valores.
Los gráficos de densidad se pueden hacer usando pandas, seaborn, etc. En este artículo, generaremos gráficos de densidad usando Pandas. Usaremos dos conjuntos de datos de la Biblioteca Seaborn, a saber: ‘car_crashes’ y ‘tips’.
Sintaxis: pandas.DataFrame.plot.density | pandas.DataFrame.plot.kde
donde pandas -> el conjunto de datos del tipo ‘pandas dataframe’
Marco de datos -> la columna para la que se dibujará el gráfico de densidad
trama -> palabra clave que dirige para dibujar una trama/gráfico para la columna dada
densidad -> para trazar un gráfico de densidad
kde -> para trazar un gráfico de densidad usando la función de Estimación de Densidad del Kernel
Ejemplo 1: dado el conjunto de datos ‘car_crashes’, averigüemos mediante el gráfico de densidad cuál es la velocidad más común debido a la cual ocurrieron la mayoría de los accidentes automovilísticos.
Python3
# importing the libraries
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
# loading the dataset
# from seaborn library
data = sns.load_dataset('car_crashes')
# viewing the dataset
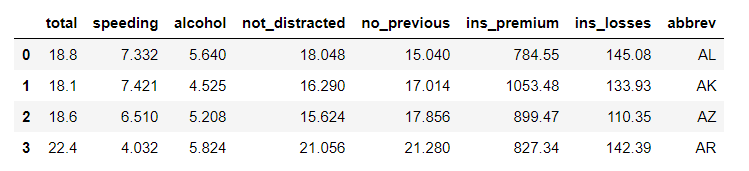
print(data.head(4))
Producción:
Trazando el gráfico:
Python3
# plotting the density plot
# for 'speeding' attribute
# using plot.density()
data.speeding.plot.density(color='green')
plt.title('Density plot for Speeding')
plt.show()
Producción:
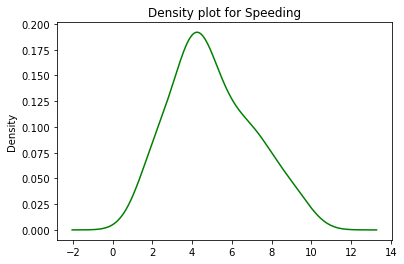
Usando un gráfico de densidad, podemos determinar que la velocidad entre 4 y 5 (kmph) fue la más común para los choques en el conjunto de datos debido a que es una región de alta densidad (pico alto).
Ejemplo 2: para otro conjunto de datos de ‘consejos’, calculemos cuál fue el consejo más común dado por un cliente.
Python3
# loading the dataset
# from seaborn library
data = sns.load_dataset('tips')
# viewing the dataset
print(data.head(4))
Producción:

conjunto de datos de ‘consejos’
Trazando el gráfico:
Python3
# density plot for 'tip'
data.tip.plot.density(color='green')
plt.title('Density Plot for Tip')
plt.show()
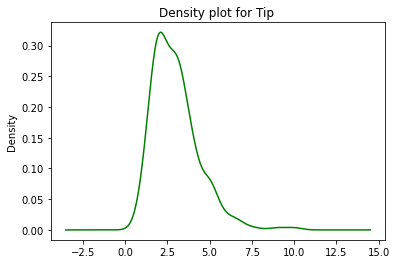
A través del gráfico de densidad anterior, podemos inferir que la propina más común que se dio estuvo en el rango de 2,5 a 3. Se encontró que el pico/densidad más alto (como se representa en el eje y) estaba en el valor de la punta de 2,5 – 3.
Trazar el gráfico anterior usando plot.kde()
KDE o Kernel Density Estimation utiliza núcleos gaussianos para estimar la función de densidad de probabilidad de una variable aleatoria. A continuación se muestra la implementación del trazado del diagrama de densidad usando kde() para los ‘consejos’ del conjunto de datos.
Python3
# for 'tip' attribute
# using plot.kde()
data.tip.plot.kde(color='green')
plt.title('KDE-Density plot for Tip')
plt.show()
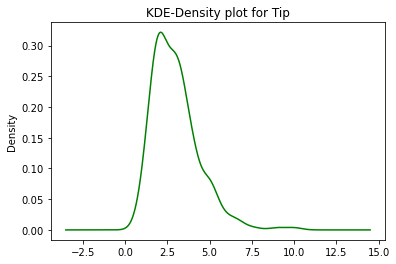
Usando esto, podemos inferir que no hay una gran diferencia entre plot.density() y plot.kde() y, por lo tanto, se pueden usar indistintamente.
Los diagramas de densidad tienen una ventaja sobre los histogramas porque determinan la forma de la distribución de manera más eficiente que los histogramas. No tienen que depender del número de contenedores utilizados a diferencia de los histogramas.
Publicación traducida automáticamente
Artículo escrito por riyaaggarwal y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA