Requisito previo: introducción a los autómatas finitos
Todos los lenguajes de programación se pueden representar como autómatas finitos. C, Paskal, Haskell, C++, todos tienen una estructura específica, gramática, que se puede representar mediante un gráfico simple. La mayoría de los gráficos son NFA o DFA. Pero NFA y DFA determinan el grupo de idiomas más simple posible: grupo de idiomas regulares [ jerarquía de Chomsky ]. Esto nos deja con una pregunta: ¿qué pasa con todos los demás tipos de lenguajes? Una de las respuestas es la máquina de Turing , pero una máquina de Turing es difícil de visualizar. Es por eso que en este artículo te hablaré de un tipo de autómata finito llamado L-grafo.
Para entender cómo funcionan los L-graphs necesitamos saber qué tipo de lenguajes determinan los L-graphs. En pocas palabras, los gráficos L representan tipos de lenguajes sensibles al contexto [y cualquier otro tipo que contenga el grupo sensible al contexto]. Si no sabe lo que significa «sensible al contexto», permítame mostrarle un ejemplo de un lenguaje que se puede representar mediante un gráfico en L y no mediante un tipo más sencillo de autómatas finitos.
Este lenguaje es  . El gráfico L correspondiente se ve así:
. El gráfico L correspondiente se ve así:
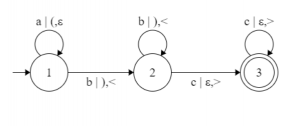
Como puede ver los corchetes después del símbolo ‘|’ controlar el número de símbolos que vienen después de los símbolos ‘a’. Esto nos lleva a las dos características que poseen todos los gráficos L: todos los gráficos L tienen hasta dos grupos de paréntesis independientes entre sí y de los símbolos de entrada, ambos grupos de paréntesis tienen que ser correctos [string de un lenguaje Dyck] para que la string de símbolos de entrada que aceptará el L-graph dado.
Puede ver que un L-graph es solo una versión de autómatas finitos con un par de grupos de corchetes adicionales. Para ayudarlo a comprender por qué los idiomas determinados por los gráficos L son sensibles al contexto, verifique qué strings debe aceptar el gráfico L que se muestra arriba.

Para concluir, me gustaría agregar otras tres definiciones que usaré en el futuro. Estas definiciones son muy importantes para la hipótesis [y su futura prueba o refutación]. Referir – Hipótesis (regularidad del lenguaje) y algoritmo (L-graph a NFA)
Llamaremos neutral a un camino en el L-graph, si ambas strings de paréntesis son correctas. Si un camino neutral T se puede representar así, T =  , donde
, donde  y
y  son ciclos y
son ciclos y  es un camino neutral ( , o puede estar vacío), T se llama nido. También podemos decir que el tres ( , , ) es un nido o que y forman un nido en el camino T.
es un camino neutral ( , o puede estar vacío), T se llama nido. También podemos decir que el tres ( , , ) es un nido o que y forman un nido en el camino T.
(  , d)-núcleo en un L-grafo G, definido como Core(G, , d), es un conjunto de ( , d)-cánones. ( , d)-canon, donde y d son números enteros positivos, es un camino que contiene como máximo m,
, d)-núcleo en un L-grafo G, definido como Core(G, , d), es un conjunto de ( , d)-cánones. ( , d)-canon, donde y d son números enteros positivos, es un camino que contiene como máximo m,  , ciclos neutros y como máximo k, k
, ciclos neutros y como máximo k, k  d, nidos que se pueden representar de esta manera:
d, nidos que se pueden representar de esta manera:  es parte del camino T,
es parte del camino T,  , i = 1 o 3,
, i = 1 o 3,  , son ciclos, cada camino
, son ciclos, cada camino  es un nido, donde
es un nido, donde  =
=  ,
,  .
.
La última definición se trata de un gráfico L libre de contexto. Un L-grafo G se llama libre de contexto si G tiene solo un grupo de corchetes (todas las reglas en el L-grafo tienen solo un aspecto de estos dos: [‘símbolo’ | ‘corchete’, ?] o [‘símbolo’ | ? , ‘soporte’]).
[Definición de una lengua de Dyck.  y
y  son alfabetos disjuntos. Existe una biyección (función que para cada elemento del 1er conjunto coincide con uno y solo un elemento del 2do conjunto)
son alfabetos disjuntos. Existe una biyección (función que para cada elemento del 1er conjunto coincide con uno y solo un elemento del 2do conjunto)  . Entonces el lenguaje definido por la gramática
. Entonces el lenguaje definido por la gramática  ,
,  lo llamaremos lenguaje de Dyck.]
lo llamaremos lenguaje de Dyck.]