En este artículo, veremos cómo usar el rastreo con Scrapy y cómo exportar datos a formato JSON y CSV. Extraeremos datos de una página web, usando una araña Scrapy, y los exportaremos a dos formatos de archivo diferentes.
Aquí lo extraeremos del enlace http://quotes.toscrape.com/tag/friendship/ . Este sitio web es proporcionado por los creadores de Scrapy, para aprender sobre la biblioteca. Entendamos el enfoque anterior paso a paso:
Paso 1: Crea un proyecto scrapy
Ejecute el siguiente comando, en la terminal, para crear un proyecto Scrapy:
scrapy startproject gfg_friendshipquotes
Esto creará un nuevo directorio, llamado «gfg_friendshipquotes», en su directorio actual. Ahora cambie el directorio, a la carpeta recién creada.

La estructura de carpetas de ‘gfg_friendshipquotes’ se muestra a continuación. Mantenga el contenido de los archivos de configuración tal como están actualmente.


Paso 2: Para crear un archivo spider, usamos el comando ‘genspider’. Verifique que el comando genspider se ejecute en el mismo nivel de directorio, donde está presente el archivo scrapy.cfg. El comando es –
scrapy genspider spider_filename “url_of_page_to_scrape”
Ahora, ejecuta lo siguiente en la terminal:
scrapy genspider gfg_friendquotes «quotes.toscrape.com/tag/friendship/»
Esto debería crearse, un archivo spider Python, llamado “gfg_friendquotes.py”, en la carpeta spiders como:

El código predeterminado del archivo gfg_friendquotes.py es el siguiente:
Python
# Import the required library import scrapy # Spider class class GfgFriendquotesSpider(scrapy.Spider): # The name of the spider name = 'gfg_friendquotes' # The domain, the spider will crawl allowed_domains = ['quotes.toscrape.com/tag/friendship/'] # The URL of the webpage, data from which # will get scraped start_urls = ['http://quotes.toscrape.com/tag/friendship/'] # default start function which will hold # the code for navigating and gathering # the data from tags def parse(self, response): pass
Paso 3: Ahora, analicemos las expresiones XPath para los elementos requeridos. Si visita el enlace, http://quotes.toscrape.com/tag/friendship/ se verá de la siguiente manera:
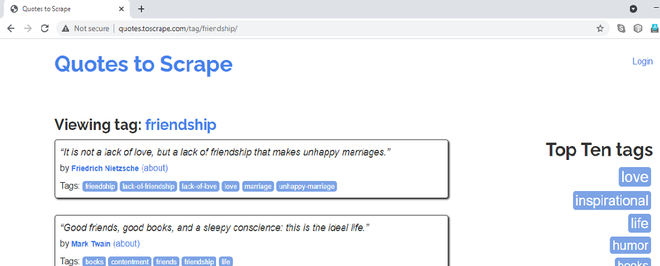
URL de la página que rasparemos
Vamos a raspar los títulos, autores y etiquetas de las citas de amistad. Cuando hace clic derecho en Cotizaciones, lo bloquea y selecciona la opción Inspeccionar, uno puede notar que pertenecen a la clase «cita». Al pasar el cursor sobre el resto de los bloques de comillas, se puede notar que todas las comillas, en la página web, tienen el atributo de clase CSS como «cita».
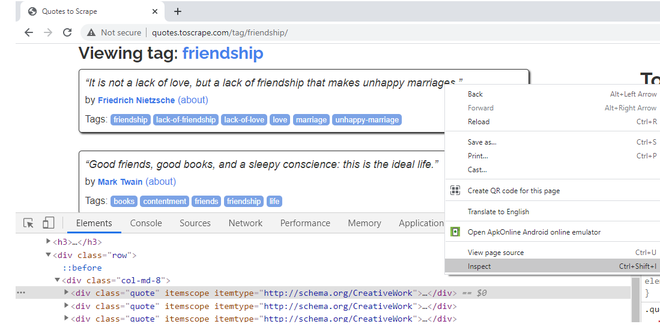
Haga clic derecho, inspeccionar, verifique los atributos CSS del primer bloque de cotización
Para extraer el texto de la cita, haga clic con el botón derecho en la primera cita y diga Inspeccionar. El título/texto de la cita, pertenece al atributo de clase CSS, “texto”.
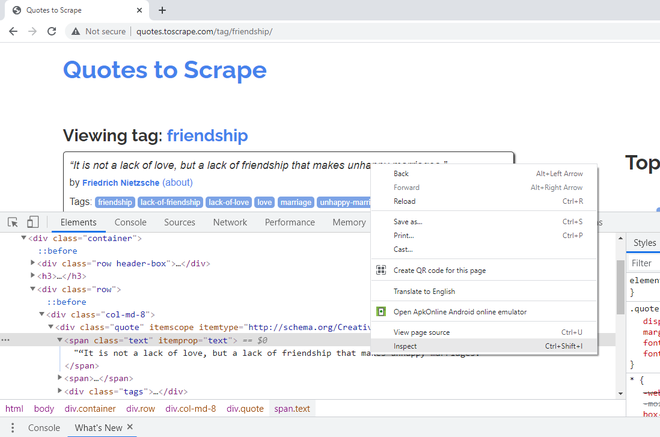
Haga clic derecho en el primer Título, Inspeccionar, verifique los atributos de clase CSS
Para extraer el nombre del autor de la cita, haga clic derecho en el nombre y diga Inspeccionar. Pertenece a la clase CSS «autor». Hay un atributo CSS itemprop, definido aquí también con el mismo nombre. Usaremos este atributo en nuestro código.
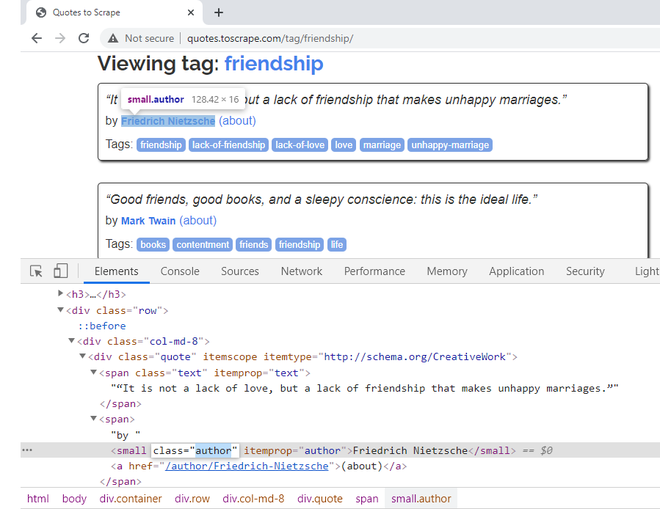
Haga clic derecho en el nombre del autor para obtener sus atributos CSS
Paso 7: para extraer las etiquetas de la cita, haga clic derecho en la primera etiqueta y diga Inspeccionar. Una sola etiqueta pertenece a la clase CSS «etiqueta». Juntos, tienen un atributo CSS de itemprop, «palabras clave» definidas. También tienen un atributo CSS de «contenido», con todas las etiquetas en una línea. Si observa, el texto real de las etiquetas está presente dentro de <a>, elementos de hipervínculo. Por lo tanto, la obtención del atributo «contenido» sería más fácil.
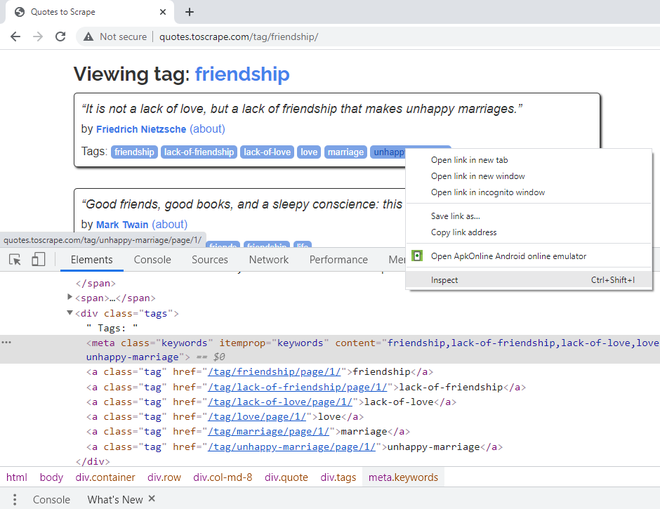
Haga clic con el botón derecho en Etiquetas para obtener sus atributos CSS
El código final, para el archivo spider, después de incluir las expresiones XPath, es el siguiente:
Python3
# Import the required libraries
import scrapy
# Default class created when we run the "genspider" command
class GfgFriendquotesSpider(scrapy.Spider):
# Name of the spider as mentioned in the "genspider" command
name = 'gfg_friendquotes'
# Domains allowed for scraping, as mentioned in the "genspider" command
allowed_domains = ['quotes.toscrape.com/tag/friendship/']
# URL(s) to scrape as mentioned in the "genspider" command
# The scrapy spider, starts making requests, to URLs mentioned here
start_urls = ['http://quotes.toscrape.com/tag/friendship/']
# Default callback method responsible for returning the scraped output and processing it.
def parse(self, response):
# XPath expression of all the Quote elements.
# All quotes belong to CSS attribute class having value 'quote'
quotes = response.xpath('//*[@class="quote"]')
# Loop through the quotes object, to get required elements data.
for quote in quotes:
# XPath expression to fetch 'title' of the Quote
# Title belong to CSS attribute class having value 'text'
title = quote.xpath('.//*[@class="text"]/text()').extract_first()
# XPath expression to fetch 'author name' of the Quote
# Author name belong to CSS attribute itemprop having value 'author'
author = quote.xpath(
'.//*[@itemprop="author"]/text()').extract_first()
# XPath expression to fetch 'tags' of the Quote
# Tags belong to CSS attribute itemprop having value 'keywords'
tags = quote.xpath(
'.//*[@itemprop="keywords"]/@content').extract_first()
# Return the output
yield {'Text': title,
'Author': author,
'Tags': tags}
Scrapy permite que los datos extraídos se almacenen en formatos como JSON, CSV, XML, etc. Este tutorial muestra dos métodos para hacerlo. Uno puede escribir el siguiente comando en la terminal:
scrapy crawl “spider_name” -o store_data_extracted_filename.file_extension
Alternativamente, uno puede exportar la salida a un archivo, mencionando FEED_FORMAT y FEED_URI en el archivo settings.py.
Crear archivo JSON
Para almacenar los datos en un archivo JSON, se puede seguir cualquiera de los métodos mencionados a continuación:
scrapy crawl gfg_friendquotes -o friendshipquotes.json
Alternativamente, podemos mencionar FEED_FORMAT y FEED_URI en el archivo settings.py. El archivo settings.py debe ser el siguiente:
Python
BOT_NAME = 'gfg_friendshipquotes' SPIDER_MODULES = ['gfg_friendshipquotes.spiders'] NEWSPIDER_MODULE = 'gfg_friendshipquotes.spiders' # Obey robots.txt rules ROBOTSTXT_OBEY = True # Desired file format FEED_FORMAT = "json" # Name of the file where # data extracted is stored FEED_URI = "friendshipfeed.json"
Producción:

Usando cualquiera de los métodos anteriores, los archivos JSON se generan en la carpeta del proyecto como:
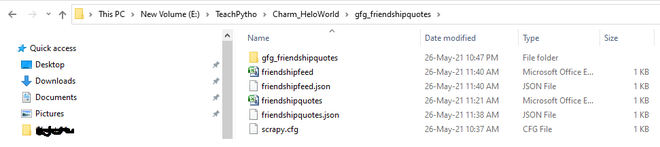
Los datos extraídos, exportados a archivos JSON
El archivo JSON esperado tiene el siguiente aspecto:
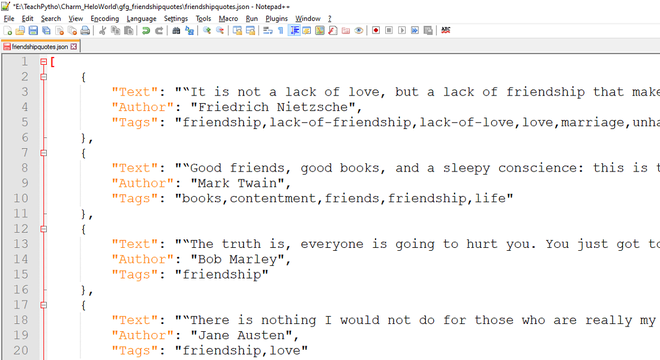
Los datos JSON exportados, rastreados por código de araña
Crear archivo CSV:
Para almacenar los datos en un archivo CSV, se puede seguir cualquiera de los métodos mencionados a continuación.
Escribe el siguiente comando en la terminal:
scrapy crawl gfg_friendquotes -o friendshipquotes.csv
Alternativamente, podemos mencionar FEED_FORMAT y FEED_URI en el archivo settings.py. El archivo settings.py debe ser el siguiente:
Python
BOT_NAME = 'gfg_friendshipquotes' SPIDER_MODULES = ['gfg_friendshipquotes.spiders'] NEWSPIDER_MODULE = 'gfg_friendshipquotes.spiders' # Obey robots.txt rules ROBOTSTXT_OBEY = True # Desired file format FEED_FORMAT = "csv" # Name of the file where data extracted is stored FEED_URI = "friendshipfeed.csv"
Producción:

Los archivos CSV se generan en la carpeta del proyecto como:
Los archivos exportados se crean en la estructura de su proyecto scrapy
El archivo CSV exportado tiene el siguiente aspecto:

Los datos CSV exportados, rastreados por código de araña
Publicación traducida automáticamente
Artículo escrito por phadnispradnya y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA