Hadoop Distributed File System, es decir, HDFS se utiliza en Hadoop para almacenar los datos, lo que significa que todos nuestros datos se almacenan en HDFS. Hadoop también es conocido por su técnica de almacenamiento eficiente y confiable. Entonces, ¿alguna vez se preguntó cómo Hadoop hace que su almacenamiento sea tan eficiente y confiable? Sí, aquí se introduce el concepto de bloques de archivos. El factor de replicación no es más que un proceso de replicación o duplicación de datos, así que analicémoslos uno por uno con el ejemplo para una mejor comprensión.
Bloques de archivos en Hadoop
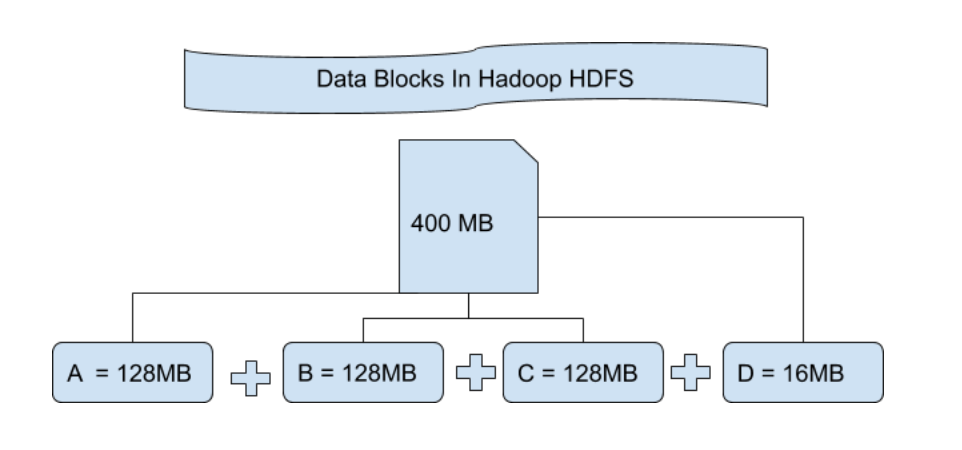
Lo que sucede es que cada vez que importa un archivo a su sistema de archivos distribuidos de Hadoop, ese archivo se divide en bloques de cierto tamaño y luego estos bloques de datos se almacenan en varios Nodes esclavos. Esto es algo normal que sucede en casi todos los tipos de sistemas de archivos. De forma predeterminada en Hadoop1, estos bloques tienen un tamaño de 64 MB, y en Hadoop2 estos bloques tienen un tamaño de 128 MB, lo que significa que todos los bloques que se obtienen después de dividir un archivo deben tener un tamaño de 64 MB o 128 MB. Puede cambiar manualmente el tamaño del bloque de archivos en el archivo hdfs-site.xml .

Entendamos este concepto de dividir un archivo en bloques con un ejemplo. Suponga que ha subido un archivo de 400 MB a su HDFS, entonces lo que sucede es que este archivo se dividió en bloques de 128 MB + 128 MB + 128 MB + 16 MB = 400 MB de tamaño. Significa que se crean 4 bloques cada uno de 128 MB excepto el último.
Hadoop no sabe o no le importa qué datos se almacenan en estos bloques, por lo que considera los bloques de archivos finales como un registro parcial. En el sistema de archivos de Linux, el tamaño de un bloque de archivos es de aproximadamente 4 KB, que es mucho menor que el tamaño predeterminado de los bloques de archivos en el sistema de archivos de Hadoop. Como todos sabemos, Hadoop está configurado principalmente para almacenar datos de gran tamaño en petabytes, esto es lo que hace que el sistema de archivos de Hadoop sea diferente de otros sistemas de archivos, ya que se puede escalar, hoy en día se consideran bloques de archivos de 128 MB a 256 MB en Hadoop.
Ahora comprendamos por qué estos bloques son tan grandes. Hay principalmente 2 razones como se explica a continuación:
- Los bloques de archivos Hadoop son más grandes porque si los bloques de archivos son más pequeños, en ese caso habrá tantos bloques en nuestro sistema de archivos Hadoop, es decir, en HDFS. El almacenamiento de muchos metadatos en estos bloques de archivos de tamaño pequeño en una cantidad muy grande se vuelve complicado, lo que puede causar tráfico en la red.
- Los bloques se hacen más grandes para que podamos minimizar el costo de buscar o encontrar. Porque a veces el tiempo necesario para transferir los datos desde el disco puede ser mayor que el tiempo necesario para iniciar estos bloques.
Ventajas de los bloques de archivos:
- Fácil de mantener ya que el tamaño puede ser mayor que cualquiera de los discos individuales presentes en nuestro clúster.
- No necesitamos ocuparnos de los metadatos como ninguno de los permisos, ya que pueden manejarse en diferentes sistemas. Por lo tanto, no es necesario almacenar estos metadatos con los bloques de archivos.
- Hacer réplicas de estos datos es bastante fácil, lo que nos brinda tolerancia a fallas y alta disponibilidad en nuestro clúster de Hadoop.
- Como los bloques tienen un tamaño configurado fijo, podemos mantener fácilmente su registro.
Replicación y factor de replicación
La replicación asegura la disponibilidad de los datos. La replicación no es más que hacer una copia de algo y la cantidad de veces que hace una copia de esa cosa en particular se puede expresar como su factor de replicación. Como hemos visto en Bloques de archivos, HDFS almacena los datos en forma de varios bloques al mismo tiempo, Hadoop también está configurado para hacer una copia de esos bloques de archivos. De forma predeterminada, el factor de replicación para Hadoop se establece en 3, lo que se puede configurar, lo que significa que puede cambiarlo manualmente según sus requisitos, como en el ejemplo anterior, hemos creado 4 bloques de archivos, lo que significa que se realizan 3 réplicas o copias de cada bloque de archivos, lo que significa un total de 4×3 = 12 bloques se hacen para el propósito de respaldo.
Ahora, es posible que tenga dudas de por qué necesitamos esta replicación para nuestros bloques de archivos porque para ejecutar Hadoop estamos usando hardware básico (hardware de sistema económico) que puede colapsar en cualquier momento. No estamos usando una supercomputadora para nuestra configuración de Hadoop. Es por eso que necesitamos una función de este tipo en HDFS que pueda hacer copias de esos bloques de archivos con fines de respaldo, esto se conoce como tolerancia a fallas .
Ahora, una cosa que también debemos notar es que después de hacer tantas réplicas de nuestros bloques de archivos, estamos desperdiciando gran parte de nuestro almacenamiento, pero para la organización de grandes marcas, los datos son mucho más importantes que el almacenamiento. Así que a nadie le importa este almacenamiento adicional.
Puede configurar el factor de replicación en su archivo hdfs-site.xml .
Aquí, hemos establecido el factor de replicación en uno, ya que solo tenemos un único sistema para trabajar con Hadoop, es decir, una sola computadora portátil, ya que no tenemos ningún clúster con muchos de los Nodes. Simplemente debe cambiar el valor en la propiedad dfs.replication según sus necesidades.

¿Cómo funciona la replicación?
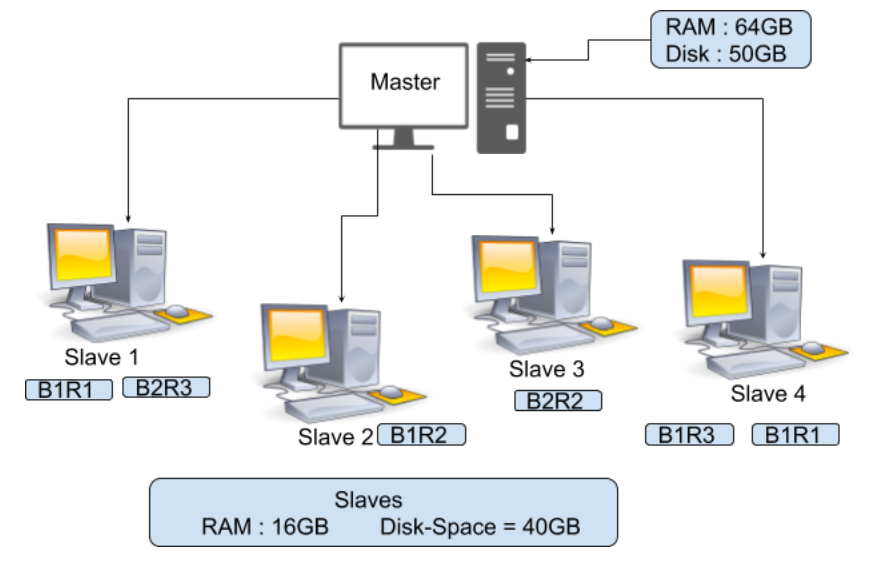
En la imagen de arriba, puede ver que hay un maestro con RAM = 64 GB y espacio en disco = 50 GB y 4 esclavos con RAM = 16 GB y espacio en disco = 40 GB. Aquí puedes observar que RAM para Master es más. Debe mantenerse más porque su Maestro es quien guiará a este esclavo, por lo que su Maestro tiene que procesar rápido. Ahora suponga que tiene un archivo de 150 MB de tamaño, entonces el total de bloques de archivos será 2 como se muestra a continuación.
128MB = Block 1 22MB = Block 2
Como el factor de replicación predeterminado es 3, tenemos 3 copias de este bloque de archivos
FileBlock1-Replica1(B1R1) FileBlock2-Replica1(B2R1) FileBlock1-Replica2(B1R2) FileBlock2-Replica2(B2R2) FileBlock1-Replica3(B1R3) FileBlock2-Replica3(B2R3)
Estos bloques se almacenarán en nuestro Esclavo como se muestra en el diagrama anterior, lo que significa que si su Esclavo 1 falla, en ese caso B1R1 y B2R3 se perderán. Pero puede recuperar el B1 y el B2 de otros esclavos ya que la réplica de estos bloques de archivos ya está presente en otros esclavos, de manera similar, si algún otro esclavo se bloqueó, entonces podemos obtener ese bloque de archivos en otro esclavo. La replicación aumentará nuestro almacenamiento, pero los datos son más necesarios para nosotros.
Publicación traducida automáticamente
Artículo escrito por dikshantmalidev y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA