Como todos sabemos, Hadoop es un marco de código abierto que se utiliza principalmente con fines de almacenamiento y mantenimiento y análisis de una gran cantidad de datos o conjuntos de datos en los clústeres de hardware básico, lo que significa que en realidad es una herramienta de gestión de datos. Hadoop también posee una propiedad de almacenamiento escalable, lo que significa que podemos escalar hacia arriba o hacia abajo la cantidad de Nodes según sea un requisito en el futuro, lo cual es realmente una característica interesante.
Hadoop funciona principalmente en 3 modos diferentes:
- Modo independiente
- Modo pseudodistribuido
- Modo totalmente distribuido
1. Modo independiente
En el modo independiente , ninguno de los Daemon se ejecutará, es decir, Namenode, Datanode, Node de nombre secundario, Job Tracker y Task Tracker. Utilizamos el rastreador de trabajos y el rastreador de tareas para fines de procesamiento en Hadoop1. Para Hadoop2 usamos Resource Manager y Node Manager. El modo independiente también significa que estamos instalando Hadoop solo en un solo sistema. De forma predeterminada, Hadoop está diseñado para ejecutarse en este modo independiente o también podemos llamarlo modo local . Principalmente usamos Hadoop en este modo con el propósito de aprender, probar y depurar.
Hadoop funciona mucho más rápido en este modo entre todos estos 3 modos. Como todos sabemos, HDFS (sistema de archivos distribuido de Hadoop) es uno de los principales componentes de Hadoop que se utiliza para el almacenamiento. El permiso no se utiliza en este modo. Puede pensar en HDFS como similar al sistema de archivos disponible para Windows, es decir, NTFS (Sistema de archivos de nueva tecnología) y FAT32 (Tabla de asignación de archivos que almacena los datos en bloques de 32 bits). cuando su Hadoop funciona en este modo, no es necesario configurar los archivos: hdfs-site.xml , mapred-site.xml , core-site.xml para el entorno de Hadoop. En este modo, todos sus procesos se ejecutarán en una sola JVM (máquina virtual Java) y este modo solo se puede usar para pequeños propósitos de desarrollo.
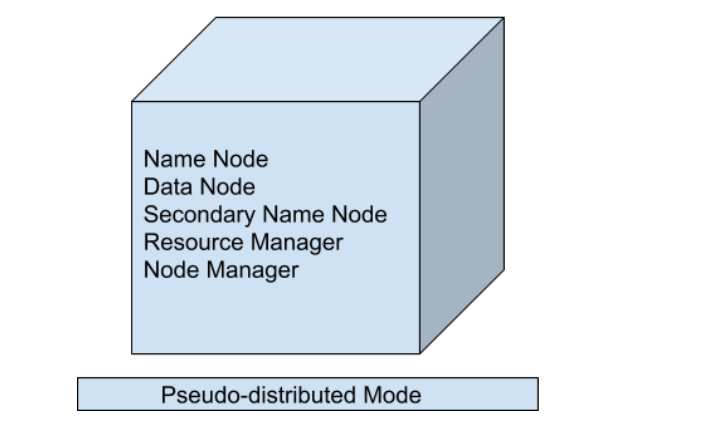
2. Modo pseudo distribuido (clúster de un solo Node)
En el modo pseudodistribuido, también usamos un solo Node, pero lo principal es que se simula el clúster, lo que significa que todos los procesos dentro del clúster se ejecutarán de forma independiente entre sí. Todos los demonios que son Namenode, Datanode, Node de nombre secundario, Administrador de recursos, Administrador de Nodes, etc. se ejecutarán como un proceso separado en JVM (Máquina virtual Java) separada o podemos decir que se ejecutan en diferentes procesos Java, por eso es llamado Pseudo-distribuido.
Una cosa que debemos recordar es que, dado que estamos utilizando solo la configuración de un solo Node, todos los procesos Maestro y Esclavo son manejados por un solo sistema. Namenode y Resource Manager se usan como maestros y Datanode y Node Manager se usan como esclavos. Un Node de nombre secundario también se utiliza como maestro. El propósito del Node Nombre secundario es simplemente mantener la copia de seguridad basada en horas del Node Nombre. En este Modo,
- Hadoop se utiliza tanto para el desarrollo como para la depuración.
- Nuestro HDFS (Sistema de archivos distribuidos de Hadoop) se utiliza para administrar los procesos de entrada y salida.
- Necesitamos cambiar los archivos de configuración mapred-site.xml , core-site.xml , hdfs-site.xml para configurar el entorno.
3. Modo totalmente distribuido (clúster de varios Nodes)
Este es el más importante en el que se utilizan múltiples Nodes, algunos de ellos ejecutan los Master Daemon que son Namenode y Resource Manager y el resto ejecuta Slave Daemon que son DataNode y Node Manager. Aquí, Hadoop se ejecutará en los clústeres de máquinas o Nodes. Aquí, los datos que se utilizan se distribuyen en diferentes Nodes. Este es en realidad el modo de producción de Hadoop. Aclaremos o entendamos este modo de una mejor manera en la terminología física.
Una vez que descargue Hadoop en un formato de archivo tar o formato de archivo zip, lo instala en su sistema y ejecuta todos los procesos en un solo sistema, pero aquí, en el modo completamente distribuido, estamos extrayendo este archivo tar o zip a cada uno de los Nodes en el clúster de Hadoop y luego estamos usando un Node particular para un proceso particular. Una vez que distribuya el proceso entre los Nodes, definirá qué Nodes funcionan como maestro o cuál de ellos funciona como esclavo.
Publicación traducida automáticamente
Artículo escrito por dikshantmalidev y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA