Hadoop es un marco de código abierto supervisado por Apache Software Foundation que está escrito en Java para almacenar y procesar grandes conjuntos de datos con el clúster de hardware básico. Hay principalmente dos problemas con los grandes datos. El primero es almacenar una cantidad tan grande de datos y el segundo es procesar esos datos almacenados. El enfoque tradicional como RDBMS no es suficiente debido a la heterogeneidad de los datos. Entonces, Hadoop viene como la solución al problema de los grandes datos, es decir, almacenar y procesar los grandes datos con algunas capacidades adicionales. Hay principalmente dos componentes de Hadoop, que son el Sistema de archivos distribuidos de Hadoop (HDFS) y Otro negociador de recursos más (YARN) .
Historia de Hadoop
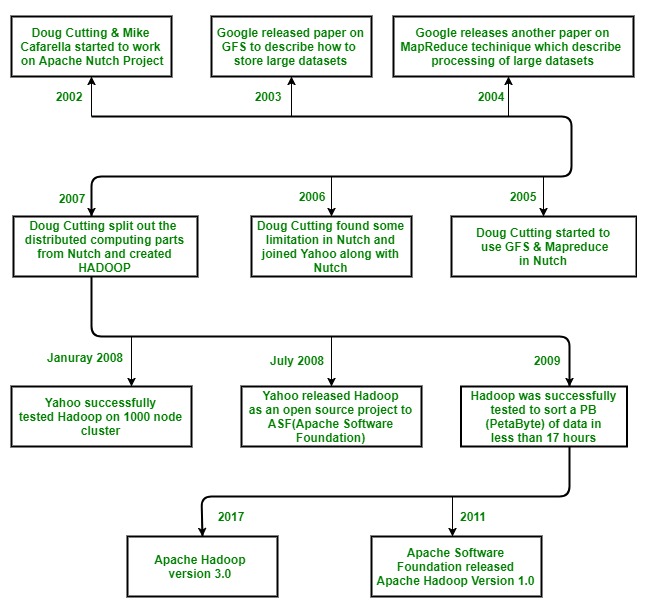
Hadoop se inició con Doug Cutting y Mike Cafarella en el año 2002 cuando ambos comenzaron a trabajar en el proyecto Apache Nutch. El proyecto Apache Nutch fue el proceso de creación de un sistema de motor de búsqueda que puede indexar mil millones de páginas. Después de mucha investigación sobre Nutch, concluyeron que dicho sistema costará alrededor de medio millón de dólares en hardware, y junto con un costo de funcionamiento mensual de $30,000 aproximadamente, lo cual es muy costoso. Entonces, se dieron cuenta de que la arquitectura de su proyecto no sería lo suficientemente capaz de solucionar miles de millones de páginas en la web. Por lo tanto, buscaban una solución factible que pudiera reducir el costo de implementación, así como el problema del almacenamiento y procesamiento de grandes conjuntos de datos.
En 2003, se encontraron con un artículo que describía la arquitectura del sistema de archivos distribuido de Google, llamado GFS (Google File System) que fue publicado por Google, para almacenar grandes conjuntos de datos. Ahora se dan cuenta de que este documento puede resolver su problema de almacenar archivos muy grandes que se generaban debido a los procesos de indexación y rastreo web. Pero este documento era solo la solución a medias a su problema.
En 2004, Google publicó un artículo más sobre la técnica MapReduce , que era la solución para procesar esos grandes conjuntos de datos. Ahora bien, este papel fue otra media solución para Doug Cutting y Mike Cafarella para su proyecto Nutch. Estas dos técnicas (GFS y MapReduce) solo estaban en papel blanco en Google. Google no implementó estas dos técnicas. Doug Cutting sabía por su trabajo en Apache Lucene (es una biblioteca de software de recuperación de información gratuita y de código abierto, escrita originalmente en Java por Doug Cutting en 1999) que el código abierto es una excelente manera de difundir la tecnología a más personas. Entonces, junto con Mike Cafarella, comenzó a implementar las técnicas de Google (GFS y MapReduce) como código abierto en el proyecto Apache Nutch.
En 2005, Cutting descubrió que Nutch está limitado a solo grupos de 20 a 40 Nodes. Pronto se dio cuenta de dos problemas:
(a) Nutch no alcanzaría su potencial hasta que se ejecutara de manera confiable en los clústeres más grandes
(b) Y eso parecía imposible con solo dos personas (Doug Cutting y Mike Cafarella).
La tarea de ingeniería en el proyecto Nutch era mucho más grande de lo que pensaba. Así que comenzó a buscar trabajo en una empresa que esté interesada en invertir en sus esfuerzos. Y encontró a Yahoo!. Yahoo tenía un gran equipo de ingenieros ansiosos por trabajar en este proyecto.
Entonces , en 2006, Doug Cutting se unió a Yahoo junto con el proyecto Nutch. Quería brindarle al mundo un marco informático escalable, confiable y de código abierto, con la ayuda de Yahoo. Primero, en Yahoo, separó las partes informáticas distribuidas de Nutch y formó un nuevo proyecto Hadoop (le dio el nombre Hadoop, era el nombre de un elefante de juguete amarillo que era propiedad del hijo de Doug Cutting, y era fácil de pronunciar y era la palabra única. ) Ahora quería hacer Hadoop de tal manera que pudiera funcionar bien en miles de Nodes. Entonces, con GFS y MapReduce, comenzó a trabajar en Hadoop.
En 2007, Yahoo probó con éxito Hadoop en un clúster de 1000 Nodes y comenzó a usarlo.
En enero de 2008, Yahoo lanzó Hadoop como un proyecto de código abierto para ASF (Apache Software Foundation) . Y en julio de 2008, Apache Software Foundation probó con éxito un clúster de 4000 Nodes con Hadoop.
En 2009, Hadoop se probó con éxito para ordenar un PB (PetaByte) de datos en menos de 17 horas para manejar miles de millones de búsquedas e indexar millones de páginas web. Y Doug Cutting dejó Yahoo y se unió a Cloudera para cumplir con el desafío de llevar Hadoop a otras industrias.
En diciembre de 2011, Apache Software Foundation lanzó Apache Hadoop versión 1.0.
Y más tarde, en agosto de 2013, estuvo disponible la versión 2.0.6 .
Y actualmente, tenemos Apache Hadoop versión 3.0 que se lanzó en diciembre de 2017 .
Resumamos la historia anterior:
Publicación traducida automáticamente
Artículo escrito por Anshul_Aggarwal y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA