La definición de una persona poderosa ha cambiado en este mundo. Un poderoso es aquel que tiene acceso a los datos. Esto se debe a que los datos aumentan a un ritmo tremendo. Supongamos que estamos viviendo en un mundo 100% de datos. Entonces el 90% de los datos se produce en los últimos 2 a 4 años. Esto se debe a que ahora cuando un niño nace, antes que su madre, primero se enfrenta al flash de la cámara. Todas estas imágenes y videos no son más que datos. Del mismo modo, hay datos de correos electrónicos, varias aplicaciones de teléfonos inteligentes, datos estadísticos, etc. Todos estos datos tienen el enorme poder de afectar varios incidentes y tendencias. Estos datos no solo los utilizan las empresas para afectar a sus consumidores, sino también los políticos para influir en las elecciones. Esta gran cantidad de datos se conoce como Big Data. En un mundo así, donde los datos se producen a un ritmo tan exponencial, es necesario mantenerlos, analizarlos y abordarlos. Aquí es donde entra Hadoop.
Hadoop es un marco del conjunto de herramientas de código abierto distribuido bajo la licencia Apache. Se utiliza para administrar datos, almacenar datos y procesar datos para varias aplicaciones de big data que se ejecutan en sistemas agrupados. En los años anteriores, Big Data se definía por las » 3V «, pero ahora hay » 5V » de Big Data, que también se denominan como las características de Big Data.
- Volumen: con una dependencia cada vez mayor de la tecnología, los datos se producen a un gran volumen. Ejemplos comunes son los datos producidos por varios sitios de redes sociales, sensores, escáneres, aerolíneas y otras organizaciones.
- Velocidad: Se genera una gran cantidad de datos por segundo. Se estima que para fines de 2020, cada individuo producirá 3 mb de datos por segundo. Este gran volumen de datos se está generando a gran velocidad.
- Variedad: Los datos que se producen por diferentes medios son de tres tipos:
- Datos estructurados: Son los datos relacionales que se almacenan en forma de filas y columnas.
- Datos no estructurados: textos, imágenes, videos, etc. son ejemplos de datos no estructurados que no se pueden almacenar en forma de filas y columnas.
- Datos semiestructurados: los archivos de registro son ejemplos de este tipo de datos.
- Veracidad: El término Veracidad se acuña para los datos inconsistentes o incompletos que resultan en la generación de Información dudosa o incierta. A menudo, la inconsistencia de los datos surge debido al volumen o la cantidad de datos, por ejemplo, los datos a granel pueden crear confusión, mientras que una menor cantidad de datos podría transmitir información parcial o incompleta.
- Valor: Después de tener en cuenta las 4 V, viene una V más que significa ¡Valor!. La gran cantidad de datos que no tienen valor no es bueno para la empresa, a menos que los convierta en algo útil. Los datos en sí mismos no tienen ningún uso ni importancia, pero deben convertirse en algo valioso para extraer información. Por lo tanto, puede establecer ese Valor! es el V más importante de todos los 5V
Evolución de Hadoop:Hadoop fue diseñado por Doug Cutting y Michael Cafarella en 2005. El diseño de Hadoop está inspirado en Google. Hadoop almacena la gran cantidad de datos a través de un sistema llamado Hadoop Distributed File System (HDFS) y procesa estos datos con la tecnología de Map Reduce. Los diseños de HDFS y Map Reduce están inspirados en Google File System (GFS) y Map Reduce. En el año 2000, Google superó repentinamente a todos los motores de búsqueda existentes y se convirtió en el motor de búsqueda más popular y rentable. El éxito de Google se atribuyó a su exclusivo sistema de archivos de Google y Map Reduce. Nadie, excepto Google, sabía sobre esto, hasta ese momento. Entonces, en el año 2003, Google publicó algunos documentos sobre GFS. Pero no fue suficiente para comprender el funcionamiento general de Google. Entonces, en 2004, Google volvió a publicar los documentos restantes. Los dos entusiastas Doug Cutting y Michael Cafarella estudiaron esos documentos y diseñaron lo que se llama Hadoop en el año 2005. El hijo de Doug tenía un elefante de juguete cuyo nombre era Hadoop y así Doug y Michael dieron su nueva creación, el nombre «Hadoop» y de ahí el símbolo “elefante de juguete”. Así evolucionó Hadoop. Por lo tanto, los diseños de HDFS y Map Reduced fueron creados por Doug Cutting y Michael Cafarella, pero originalmente están inspirados en Google. Para obtener más detalles sobre la evolución de Hadoop, puede consultar Por lo tanto, los diseños de HDFS y Map Reduced fueron creados por Doug Cutting y Michael Cafarella, pero originalmente están inspirados en Google. Para obtener más detalles sobre la evolución de Hadoop, puede consultar Por lo tanto, los diseños de HDFS y Map Reduced fueron creados por Doug Cutting y Michael Cafarella, pero originalmente están inspirados en Google. Para obtener más detalles sobre la evolución de Hadoop, puede consultarHadoop | Historia o Evolución .
Enfoque tradicional: Supongamos que queremos procesar un dato. En el enfoque tradicional, solíamos almacenar datos en máquinas locales. Estos datos fueron luego procesados. Ahora que los datos comenzaron a aumentar, las máquinas o computadoras locales no tenían la capacidad suficiente para almacenar este enorme conjunto de datos. Entonces, los datos comenzaron a almacenarse en servidores remotos. Ahora supongamos que necesitamos procesar esos datos. Entonces, en el enfoque tradicional, estos datos deben obtenerse de los servidores y luego procesarse. Supongamos que estos datos son de 500 GB. Ahora, prácticamente es muy complejo y costoso obtener estos datos. Este enfoque también se denomina enfoque empresarial.
En el nuevo enfoque de Hadoop, en lugar de buscar los datos en las máquinas locales, enviamos la consulta a los datos. Obviamente, la consulta para procesar los datos no será tan grande como los propios datos. Además, en el servidor, la consulta se divide en varias partes. Todas estas partes procesan los datos simultáneamente. Esto se denomina ejecución paralela y es posible gracias a Map Reduce. Por lo tanto, ahora no solo no es necesario obtener los datos, sino que el procesamiento lleva menos tiempo. El resultado de la consulta se envía al usuario. Por lo tanto, Hadoop hace que el almacenamiento, el procesamiento y el análisis de datos sean mucho más fáciles que su enfoque tradicional.
Componentes de Hadoop: Hadoop tiene tres componentes:
- HDFS: Hadoop Distributed File System es un sistema de archivos dedicado para almacenar big data con un grupo de hardware básico o hardware más económico con un patrón de acceso de transmisión. Permite que los datos se almacenen en múltiples Nodes en el clúster, lo que garantiza la seguridad de los datos y la tolerancia a fallas.
- Map Reduce: los datos que una vez se almacenaron en el HDFS también deben procesarse. Ahora suponga que se envía una consulta para procesar un conjunto de datos en el HDFS. Ahora, Hadoop identifica dónde se almacenan estos datos, esto se llama Mapeo. Ahora la consulta se divide en varias partes y los resultados de todas estas partes múltiples se combinan y el resultado general se devuelve al usuario. Esto se llama proceso de reducción. Por lo tanto, mientras que HDFS se usa para almacenar los datos, Map Reduce se usa para procesar los datos.
- YARN: YARN significa Otro Negociador de Recursos . Es un sistema operativo dedicado para Hadoop que administra los recursos del clúster y también funciona como un marco para la programación de trabajos en Hadoop. Los distintos tipos de programación son por orden de llegada, programador de reparto justo y programador de capacidad, etc. La programación por orden de llegada se establece de forma predeterminada en YARN.
¿Cómo los componentes de Hadoop lo convierten en una solución para Big Data?
- Sistema de archivos distribuidos de Hadoop: en nuestra PC local, el tamaño de bloque predeterminado en el disco duro es de 4 KB . Cuando instalamos Hadoop, el HDFS por defecto cambia el tamaño del bloque a 64 MB . Ya que se utiliza para almacenar grandes datos. También podemos cambiar el tamaño del bloque a 128 MB . Ahora HDFS funciona con Node de datos y Node de nombre. Si bien Name Node es un servicio maestro y mantiene los metadatos en cuanto al hardware básico en el que residen los datos, Data Node almacena los datos reales. Ahora, dado que el tamaño del bloque es de 64 MB, el almacenamiento requerido para almacenar metadatos se reduce, lo que mejora HDFS. Además, Hadoop almacena tres copias de cada conjunto de datos en tres ubicaciones diferentes. Esto asegura que Hadoop no sea propenso a un punto único de falla.
- Map Reduce: de la manera más simple, se puede entender que MapReduce divide una consulta en varias partes y ahora cada parte procesa los datos de manera coherente. Esta ejecución paralela ayuda a ejecutar una consulta más rápido y convierte a Hadoop en una opción adecuada y óptima para manejar Big Data.
- YARN: Como sabemos, Yet Another Resource Negotiator funciona como un sistema operativo para Hadoop y como los sistemas operativos son administradores de recursos, YARN administra los recursos de Hadoop para que Hadoop sirva big data de una mejor manera.
Versiones de Hadoop: Hasta ahora hay tres versiones de Hadoop de la siguiente manera.
- Hadoop 1: Esta es la primera y más básica versión de Hadoop. Incluye Hadoop Common, Hadoop Distributed File System (HDFS) y Map Reduce.
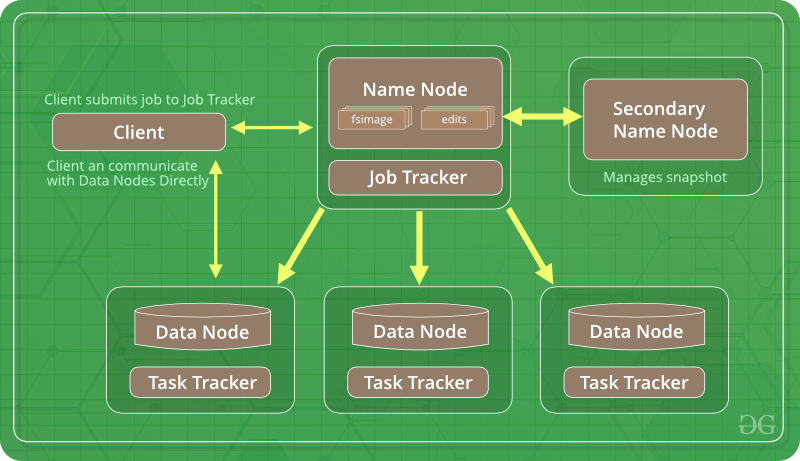
- Hadoop 2: la única diferencia entre Hadoop 1 y Hadoop 2 es que Hadoop 2 también contiene YARN (Yet Another Resource Negotiator). YARN ayuda en la gestión de recursos y la programación de tareas a través de sus dos demonios, a saber, el seguimiento de trabajos y la supervisión del progreso.
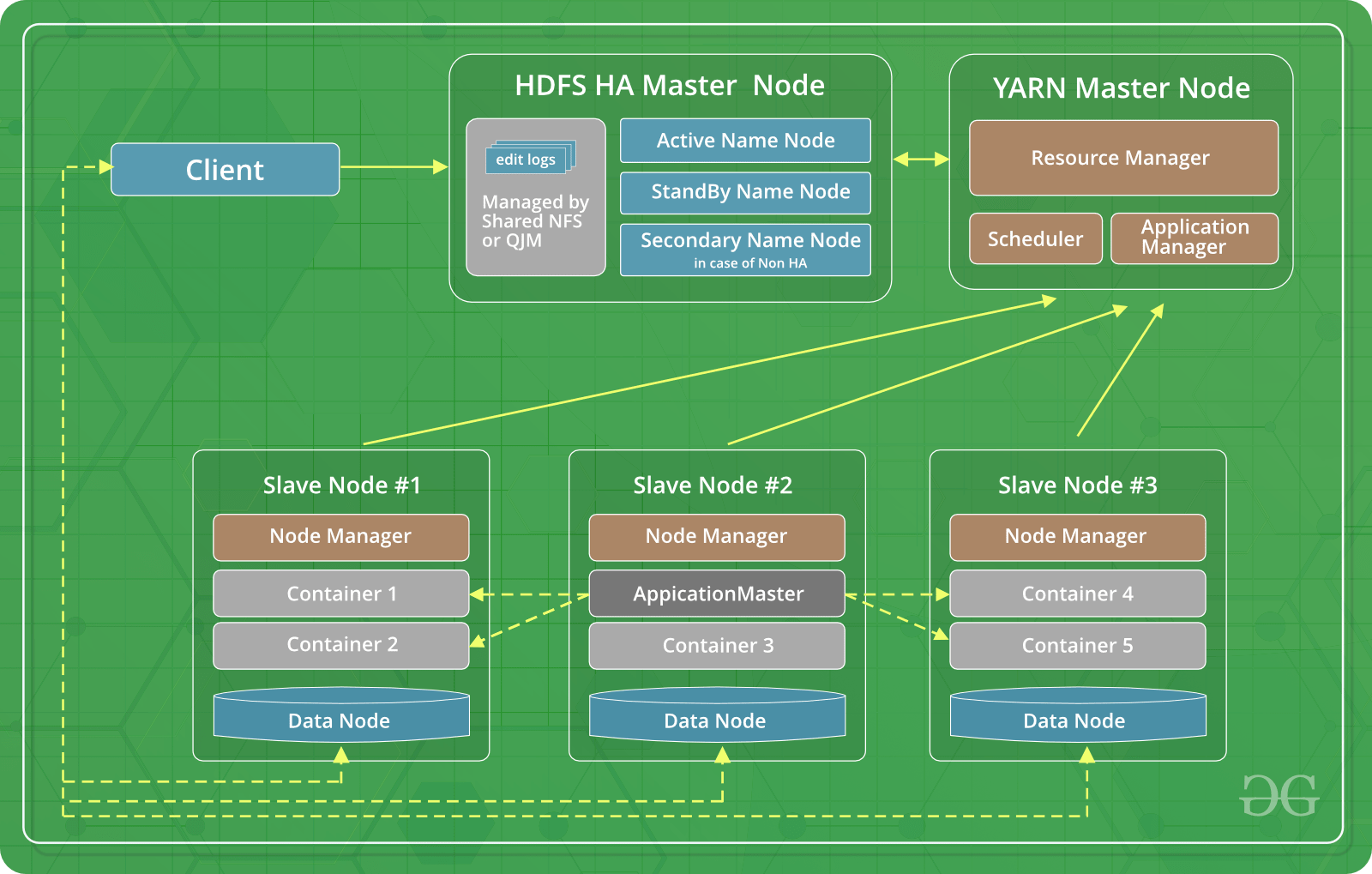
- Hadoop 3: Esta es la versión más reciente de Hadoop. Junto con los méritos de las dos primeras versiones, Hadoop 3 tiene un mérito más importante. Ha resuelto el problema de la falla de un solo punto al tener múltiples Nodes de nombre. Varias otras ventajas, como la codificación de borrado, el uso de hardware GPU y Dockers, lo hacen superior a las versiones anteriores de Hadoop.
- Económicamente factible: es más barato almacenar datos y procesarlos que en el enfoque tradicional. Dado que las máquinas reales utilizadas para almacenar datos son solo hardware básico.
- Fácil de usar: los proyectos o conjunto de herramientas proporcionados por Apache Hadoop son fáciles de usar para analizar conjuntos de datos complejos.
- Código abierto: dado que Hadoop se distribuye como un software de código abierto bajo la licencia de Apache, no es necesario pagar por él, simplemente descárguelo y utilícelo.
- Tolerancia a fallas: dado que Hadoop almacena tres copias de datos, incluso si se pierde una copia debido a una falla del hardware básico, los datos están seguros. Además, como la versión 3 de Hadoop tiene varios Nodes de nombre, también se eliminó el único punto de falla de Hadoop.
- Escalabilidad: Hadoop es altamente escalable por naturaleza. Si se necesita ampliar o reducir el clúster, solo se necesita cambiar la cantidad de hardware básico en el clúster.
- Procesamiento distribuido: HDFS y Map Reduce garantizan el almacenamiento y el procesamiento distribuidos de los datos.
- Localidad de los datos: esta es una de las características más atractivas y prometedoras de Hadoop. En Hadoop, para procesar una consulta sobre un conjunto de datos, en lugar de llevar los datos a la computadora local, enviamos la consulta al servidor y buscamos el resultado final desde allí. Esto se llama localidad de datos.