La mayoría de nosotros estamos familiarizados con el término Rack . El rack es una colección física de Nodes en nuestro clúster Hadoop (quizás 30 o 40). Un gran clúster de Hadoop consta de muchos bastidores. Con la ayuda de esta información de Racks, Namenode elige el Datanode más cercano para lograr el máximo rendimiento mientras realiza la lectura/escritura de información que reduce el tráfico de red.
Un bastidor puede tener varios Nodes de datos que almacenan los bloques de archivos y sus réplicas. Hadoop en sí mismo es tan inteligente que escribirá automáticamente un bloque de archivo en particular en 2 Nodes de datos diferentes en Rack. Si desea almacenar ese bloque de datos en más de 2 bastidores, puede hacerlo. Además, como esta característica es configurable, significa que puede cambiarla manualmente.
Ejemplo de Rack en un clúster:
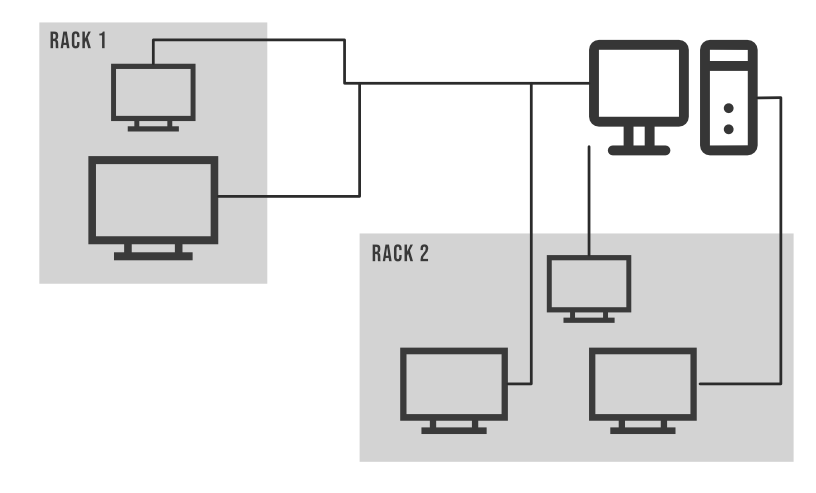
Como todos sabemos, un gran clúster de Hadoop contiene múltiples bastidores, en cada bastidor hay muchos Nodes de datos disponibles. La comunicación entre los Nodes de datos que están presentes en el mismo rack es bastante más rápida que la comunicación entre los Nodes de datos presentes en los 2 racks diferentes.
El Node de nombre tiene la función de encontrar el Node de datos más cercano para un rendimiento más rápido porque ese Node de nombre contiene las identificaciones de todos los bastidores presentes en el clúster de Hadoop. Este concepto de elegir el Node de datos más cercano para cumplir un propósito es la conciencia de rack .
Entendamos esto con un ejemplo.
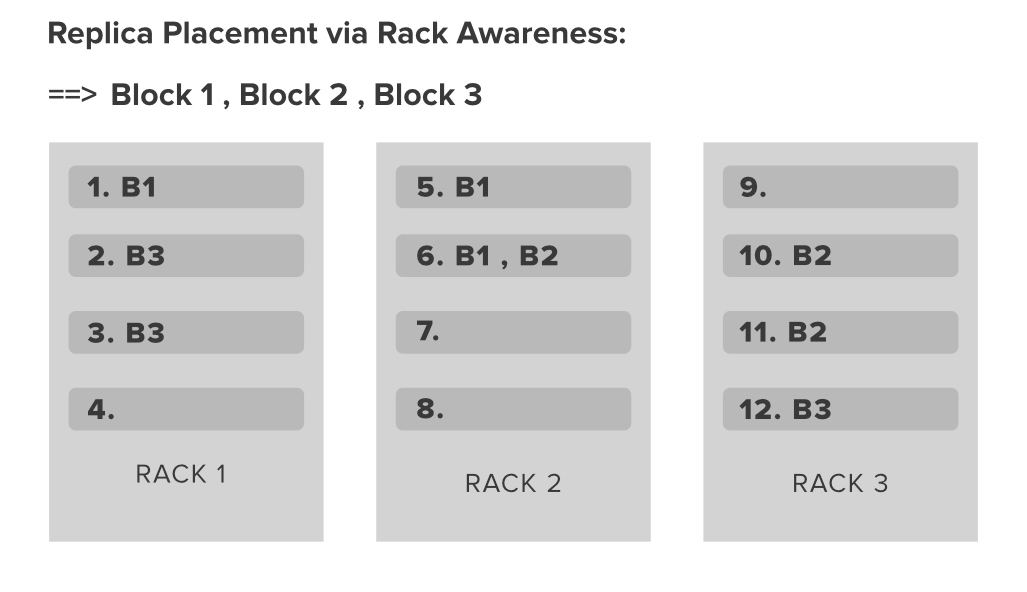
En la imagen de arriba, tenemos 3 bastidores diferentes en nuestro clúster de Hadoop, cada bastidor contiene 4 Nodes de datos. Ahora suponga que tiene 3 bloques de archivos (Bloque 1, Bloque 2, Bloque 3) que desea colocar en este Node de datos. Como todos sabemos, Hadoop tiene una función para hacer réplicas de los bloques de archivos para proporcionar alta disponibilidad y tolerancia a fallas. De forma predeterminada, el factor de replicación es 3, por lo que Hadoop es tan inteligente que colocará las réplicas de bloques en bastidores de tal manera que podamos lograr un buen ancho de banda de red. Para eso, Hadoop tiene algunas políticas de conocimiento de Rack .
- No debe haber más de 1 réplica en el mismo Datanode.
- No se permiten más de 2 réplicas de un solo bloque en el mismo estante.
- La cantidad de bastidores utilizados dentro de un clúster de Hadoop debe ser menor que la cantidad de réplicas.
Ahora continuemos con nuestro ejemplo anterior. En el diagrama, podemos encontrar fácilmente que tenemos el bloque 1 en el primer Node de datos del bastidor 1 y 2 réplicas del bloque 1 en 5 y 6 números de Nodes de datos del bastidor que suman 3. De manera similar, también tenemos una distribución de réplicas de Otros 2 bloques en diferentes Racks que siguen las políticas anteriores.
Beneficios de implementar Rack Awareness en nuestro Hadoop Cluster:
- Con la política de reconocimiento de racks, almacenamos los datos en diferentes Racks, por lo que no hay forma de perder nuestros datos.
- El conocimiento de los racks ayuda a maximizar el ancho de banda de la red porque los bloques de datos se transfieren dentro de los racks.
- También mejora el rendimiento del clúster y proporciona una alta disponibilidad de datos.
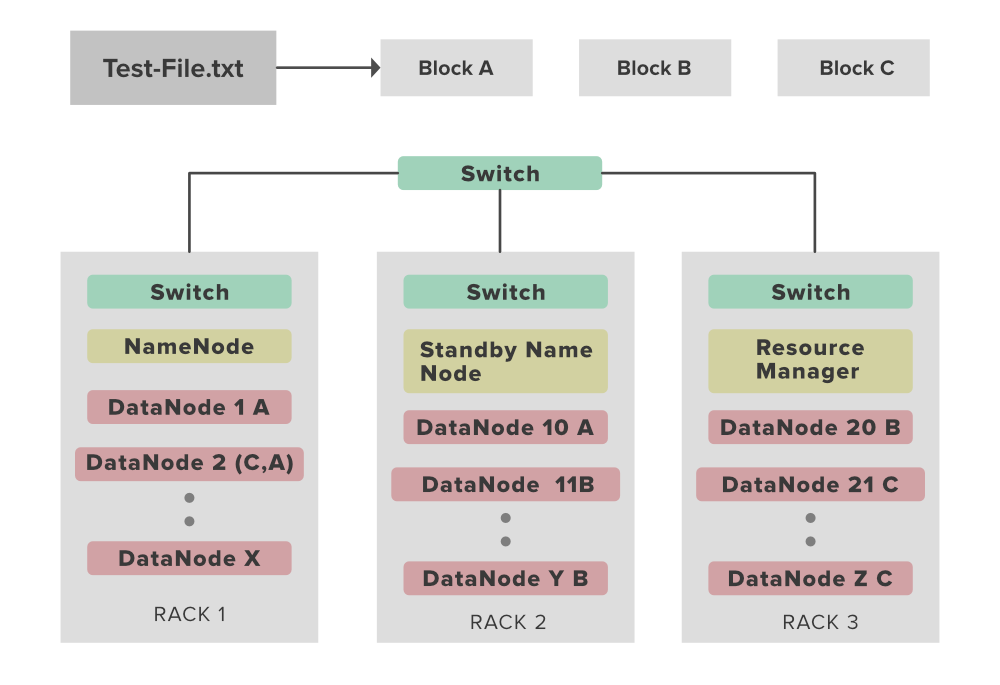
Ejemplo de reconocimiento de bastidor de HDFS:
Publicación traducida automáticamente
Artículo escrito por dikshantmalidev y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA