El hashing doble es una técnica de resolución de colisiones en las tablas hash abiertas dirigidas . El hash doble utiliza la idea de aplicar una segunda función hash a la clave cuando se produce una colisión.
Ventajas del doble hash
- La ventaja de Double hashing es que es una de las mejores formas de sondeo, produciendo una distribución uniforme de registros a lo largo de una tabla hash.
- Esta técnica no produce ningún clúster.
- Es uno de los métodos efectivos para resolver colisiones.
El hashing doble se puede hacer usando:
(hash1(clave) + i * hash2(clave)) % TABLE_SIZE
Aquí hash1() y hash2() son funciones hash y TABLE_SIZE
es el tamaño de la tabla hash.
(Repetimos aumentando i cuando ocurre la colisión)
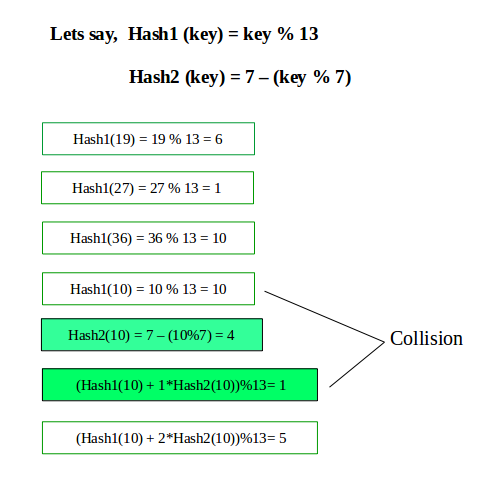
La primera función hash suele ser hash1(clave) = clave % TAMAÑO_TABLA
Una segunda función hash popular es: hash2(clave) = PRIME – (clave % PRIME) donde PRIME es un número primo más pequeño que TABLE_SIZE.
Una buena segunda función Hash es:
- Nunca debe evaluarse a cero.
- Debe asegurarse de que todas las celdas puedan ser sondeadas.
CPP
/*
** Handling of collision via open addressing
** Method for Probing: Double Hashing
*/
#include <iostream>
#include <vector>
#include <bitset>
using namespace std;
#define MAX_SIZE 10000001ll
class doubleHash {
int TABLE_SIZE, keysPresent, PRIME;
vector<int> hashTable;
bitset<MAX_SIZE> isPrime;
/* Function to set sieve of Eratosthenes. */
void __setSieve(){
isPrime[0] = isPrime[1] = 1;
for(long long i = 2; i*i <= MAX_SIZE; i++)
if(isPrime[i] == 0)
for(long long j = i*i; j <= MAX_SIZE; j += i)
isPrime[j] = 1;
}
int inline hash1(int value){
return value%TABLE_SIZE;
}
int inline hash2(int value){
return PRIME - (value%PRIME);
}
bool inline isFull(){
return (TABLE_SIZE == keysPresent);
}
public:
doubleHash(int n){
__setSieve();
TABLE_SIZE = n;
/* Find the largest prime number smaller than hash table's size. */
PRIME = TABLE_SIZE - 1;
while(isPrime[PRIME] == 1)
PRIME--;
keysPresent = 0;
/* Fill the hash table with -1 (empty entries). */
for(int i = 0; i < TABLE_SIZE; i++)
hashTable.push_back(-1);
}
void __printPrime(long long n){
for(long long i = 0; i <= n; i++)
if(isPrime[i] == 0)
cout<<i<<", ";
cout<<endl;
}
/* Function to insert value in hash table */
void insert(int value){
if(value == -1 || value == -2){
cout<<("ERROR : -1 and -2 can't be inserted in the table\n");
}
if(isFull()){
cout<<("ERROR : Hash Table Full\n");
return;
}
int probe = hash1(value), offset = hash2(value); // in linear probing offset = 1;
while(hashTable[probe] != -1){
if(-2 == hashTable[probe])
break; // insert at deleted element's location
probe = (probe+offset) % TABLE_SIZE;
}
hashTable[probe] = value;
keysPresent += 1;
}
void erase(int value){
/* Return if element is not present */
if(!search(value))
return;
int probe = hash1(value), offset = hash2(value);
while(hashTable[probe] != -1)
if(hashTable[probe] == value){
hashTable[probe] = -2; // mark element as deleted (rather than unvisited(-1)).
keysPresent--;
return;
}
else
probe = (probe + offset) % TABLE_SIZE;
}
bool search(int value){
int probe = hash1(value), offset = hash2(value), initialPos = probe;
bool firstItr = true;
while(1){
if(hashTable[probe] == -1) // Stop search if -1 is encountered.
break;
else if(hashTable[probe] == value) // Stop search after finding the element.
return true;
else if(probe == initialPos && !firstItr) // Stop search if one complete traversal of hash table is completed.
return false;
else
probe = ((probe + offset) % TABLE_SIZE); // if none of the above cases occur then update the index and check at it.
firstItr = false;
}
return false;
}
/* Function to display the hash table. */
void print(){
for(int i = 0; i < TABLE_SIZE; i++)
cout<<hashTable[i]<<", ";
cout<<"\n";
}
};
int main(){
doubleHash myHash(13); // creates an empty hash table of size 13
/* Inserts random element in the hash table */
int insertions[] = {115, 12, 87, 66, 123},
n1 = sizeof(insertions)/sizeof(insertions[0]);
for(int i = 0; i < n1; i++)
myHash.insert(insertions[i]);
cout<< "Status of hash table after initial insertions : "; myHash.print();
/*
** Searches for random element in the hash table,
** and prints them if found.
*/
int queries[] = {1, 12, 2, 3, 69, 88, 115},
n2 = sizeof(queries)/sizeof(queries[0]);
cout<<"\n"<<"Search operation after insertion : \n";
for(int i = 0; i < n2; i++)
if(myHash.search(queries[i]))
cout<<queries[i]<<" present\n";
/* Deletes random element from the hash table. */
int deletions[] = {123, 87, 66},
n3 = sizeof(deletions)/sizeof(deletions[0]);
for(int i = 0; i < n3; i++)
myHash.erase(deletions[i]);
cout<< "Status of hash table after deleting elements : "; myHash.print();
return 0;
}
Status of hash table after initial insertions : -1, 66, -1, -1, -1, -1, 123, -1, -1, 87, -1, 115, 12, Search operation after insertion : 12 present 115 present Status of hash table after deleting elements : -1, -2, -1, -1, -1, -1, -2, -1, -1, -2, -1, 115, 12,
Aquí hay una implementación fácil de Double Hashing en Python.
Nota: Está escrito en python3.
Python3
class DoubleHashing:
def __init__(self, TableSize = 1111111):
self.ts = TableSize
self.List = [None]*self.ts
self.count = 0 #to count element in list
def nearestPrime(self):
for l in range((self.ts-1),1,-1):
flag = True
for i in range(2, int(l**0.5)+1):
if l%i == 0:
flag = False
break
if flag:
return l
return 3 #default prime number
def Hx1(self,key): #HashFunction 1 or Default Hash function when there is no collision.
return key%self.ts
def Hx2(self, key): #Hash Function 2 only used when collision occurs.
return self.nearestPrime() - (key% self.nearestPrime()) #Formula: PRIME - (KEY % PRIME), Here always PRIME < TABLE_SIZE
def dHasing(self, key):
if self.count == self.ts:
print("List is Full")
return self.List
elif self.List[self.Hx1(key)] == None:
self.List[self.Hx1(key)] = key
self.count +=1
print(f"Entered key: {key} at index {self.Hx1(key)}")
else:
comp = False
i = 1
while not comp:
index = (self.Hx1(key) + i*self.Hx2(key))%self.ts # Index = ( HashFunc1 - i*HashFunc2)%TABle_SIZE
if self.List[index] == None:
self.List[index] = key
print(f"Entered key: {key} at index {index}")
comp = True
self.count +=1
else:
i +=1
return self.List
def PrintHashList(self):
for i in range(0, len(self.List)):
print(self.List[i])
def main():
tableSize = 5 #Taking 5 as size of the hash Table
DHash = DoubleHashing(tableSize)
InputElements = [4,11, 29, 1, 5]
for i in InputElements:
DHash.dHasing(i)
print('\n')
print("The Hash List After Entering Elements")
DHash.PrintHashList() #Printing the resultant HashList.
if __name__ =="__main__":
main()
Entered key: 4 at index 4 Entered key: 11 at index 1 Entered key: 29 at index 0 Entered key: 1 at index 3 Entered key: 5 at index 2 The Hash List After Entering Elements 29 11 5 1 4
Publicación traducida automáticamente
Artículo escrito por shubham_rana_77 y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA