Título del proyecto: Detección de términos de dominio y creación de conceptos jerárquicos
Introducción: Detección de términos de dominio y creación de conceptos jerárquicos en los que un conjunto dado de documentos tiene como objetivo principal identificar un término específico del dominio, lo que significa que, a partir de un gran conjunto de artículos dados, trató de extraer el dominio para cada artículo y también creó una representación jerárquica del concepto. y otros documentos de grupo bajo ese concepto. A través de esto, cualquiera puede buscar como si se encontrara que el dominio es Economía del artículo, entonces tendrá Economía como Node principal y en economía puede tener su hijo y así sucesivamente, significa que si la palabra clave buscada es Economía, entonces cuál es la palabra clave importante entonces relacionada palabra para Economía como inflación, bienes que todo viene bajo Economía como si siguiera la relación padre-hijo.
Características proporcionadas
- Extracción automática de Keywords.
- La determinación automática de cualquiera de las palabras clave extraídas es Sustantivo, Pronombre y muchos más.
- Extracción de relaciones.
- Comprobación automática de la desambiguación del sentido de las palabras.
- Un usuario puede agrupar la palabra clave en el clúster diferente.
- Mantener la estructura de árbol de la relación padre-hijo de una palabra clave.
Diagrama de flujo: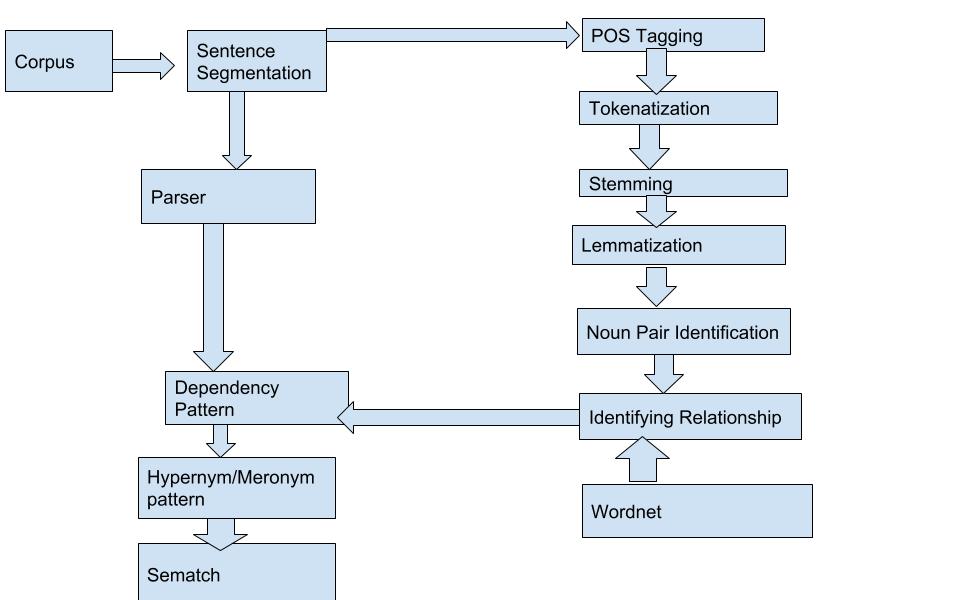
Estructuras de datos y algoritmos
- Preprocesamiento de datos: tokenización
- Para las palabras
- Extracción de entidades
- LDA (asignación latente de Dirichlet)
- LDA guiada (asignación de Laten Dirichlet)
- Derivación y Lematización.
- Extracción de características: vectorizar los datos usando TI_IDF Vectorizer (Term Frequency and Inverse Frequency Domain).
- Reducción de dimensionalidad utilizando LSA (Análisis semántico latente)
- Agrupación del vector latente.
- Clustering espacial basado en la densidad de aplicaciones con ruido (DBSCAN)
- K-significa agrupamiento.
Herramientas utilizadas: base de datos Sparql, Python, Jupyternotebook, StandfordcoreNLP,
biblioteca de visualización de datos utilizada.
- Sematch: compara la similitud de palabras. Tiene un algoritmo de similitud basado en Wordnet, DBPedia y YOGO.
- Hiperónimo y merónimo: biblioteca que se utiliza para extraer el nombre propio del texto dado.
- Pydot: se usa para crear una jerarquía descendente de la palabra clave dada como un árbol.
- Pandas: solía leer el archivo CSV.
- Marítimo.
- Biblioteca Matplot
.
Laboral.
Se aplicó NLP (procesamiento de lenguajes naturales) para este proyecto. En primer lugar, se recopilaron todos los artículos de periódicos en línea y luego se aplicaron varios algoritmos porque, como se sabe, todo el texto tomado no está estructurado y se sabe que no encajará en un modelo. de texto no estructurado, por lo que se aplicaron varios algoritmos para estructurarlo. Como sabemos, si alguien intenta encontrar en Google como Economy, también aparece la palabra clave relacionada, básicamente que sigue la relación padre-hijo en la jerarquía superior a la inferior. Entonces, el usuario puede saber fácilmente que si la palabra clave buscada es Economía, el usuario puede identificar el significado de las palabras en forma de árbol, lo cual es bastante eficiente. El usuario puede detectar fácilmente la palabra clave principal importante de un conjunto de texto determinado. Un usuario puede encontrar fácilmente la parte del discurso (pos) a partir de la palabra dada, solo proporcionará la oración y el usuario obtendrá la pos automáticamente. Un usuario puede ver fácilmente el grupo del mismo tipo de palabra. Un usuario puede almacenar la información en la base de datos SPARQL.
Punto importante Lo que encontré después del enfoque recursivo.
Después de leer mucho sobre Wordnet, noté el punto más importante de que Wordnet tiene un alcance limitado y también requiere mucho tiempo. WordNet no tiene concepto de probabilidad. WordNet almacena una lista de sus relaciones con otras palabras, pero no almacena la probabilidad de que ocurra esa relación en el uso normal.
Nota: Esta idea de proyecto es aportada por Shwetabh Shekhar para ProGeek Cup 2.0, una competencia de proyectos de GeeksforGeeks.
Publicación traducida automáticamente
Artículo escrito por GeeksforGeeks-1 y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA