Título del proyecto: myVision
Objetivo: La idea detrás de este proyecto es crear una aplicación que ayude a las personas con discapacidad visual a analizar su entorno.
Descripción: Para analizar lo que los rodea, todo lo que tienen que hacer es tomar una foto con su teléfono móvil y la aplicación aprenderá automáticamente los contenidos/objetos en la foto y brindará asistencia de voz sobre los tipos de objetos cercanos.
Pero puede haber un problema en cuanto a cómo las personas con discapacidad visual operarán esta aplicación. Bueno, todo lo que tienen que hacer es abrir esta aplicación con la ayuda de cualquier asistencia virtual en sus dispositivos móviles y luego, para tomar la foto, pueden usar cualquiera de las teclas de volumen o el botón de la cámara.
Luego, esa imagen capturada se ingresará en la red neuronal convolucional (CNN) previamente entrenada y todos los objetos detectados en esa imagen se etiquetarán. Esas etiquetas luego se pasarán al motor de texto a voz que, al analizar y procesar el texto mediante el procesamiento de lenguaje natural (NLP), convierte el texto en voz.
Un punto a favor de esta idea es que no se limita solo a una aplicación móvil. En un nivel avanzado, se puede implementar esta idea para construir algún dispositivo que funcione de manera similar, pero en lugar de tomar fotografías manualmente, puede tomar imágenes en vivo de los alrededores (como en los autos sin conductor) y brindar asistencia de voz a personas con problemas de visión. las personas no solo sobre los tipos de objetos cercanos, sino también sobre la distancia aproximada de esos objetos, mediante el uso de diferentes tipos de sensores.
Diagrama de flujo: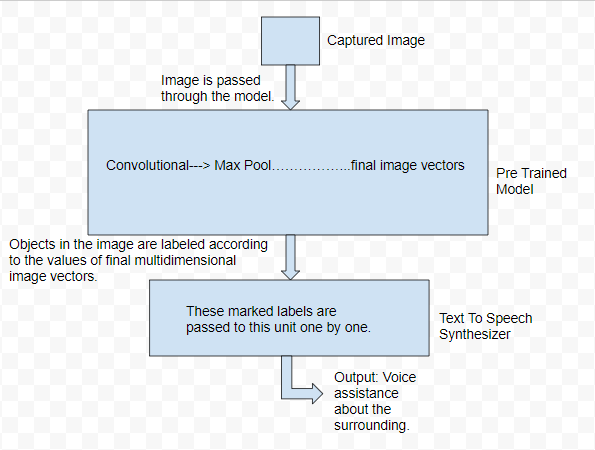
Herramientas utilizadas:
- Para el punto de vista del hardware:
- Dispositivo móvil con cámara de buena calidad.
- Buen poder de procesamiento para aprender los pesos del modelo.
- Para el punto de vista del software:
- Base de fuego de Google.
- Servicios de la nube de Google.
- Estudio Android/Visual.
- Python, Java, JavaScript.
Nota: El algoritmo utilizado para la detección de objetos es el algoritmo YOLO y para la conversión de texto a voz se utilizan los servicios de Google Cloud .
Características y aplicación:
- Proporcionar asistencia de voz a personas con discapacidad visual.
- Conveniente de usar, ya que se puede hacer clic en las imágenes simplemente presionando las teclas de volumen.
- La idea no se limita a una simple aplicación móvil, ya que un sistema puede integrarse con varios otros
dispositivos que pueden trabajar con una técnica de captura de imágenes en vivo capturando imágenes manualmente, en lugar de tomar imágenes
manualmente una y otra vez. - Con el uso de diferentes tipos de sensores, la función y la calidad del sistema pueden incrementarse en gran medida, ya que este
sistema puede implementarse para generar la distancia aproximada a los objetos y también otras características similares.
Enlaces importantes:
Sitio web de Yolo: https://pjreddie.com/darknet/yolo/
Entrenando tu propio modelo desde cero: https://timebutt.github.io/static/how-to-train-yolov2-to-detect-custom-objects/
Motor de texto a voz: https://cloud.google.com/text-to-speech/docs/
¡Gracias!
Nota: esta idea de proyecto es una contribución para ProGeek Cup 2.0: una competencia de proyectos de GeeksforGeeks .
Publicación traducida automáticamente
Artículo escrito por sanjal_katiyar y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA