Numpy es un acrónimo de ‘Numerical Python’. Es una biblioteca en python para admitir arrays n-dimensionales. Pero, ¿alguna vez se ha preguntado acerca de cargar datos en NumPy desde archivos de texto? No se preocupe, discutiremos lo mismo en este artículo. Para importar archivos de texto en Numpy Arrays, tenemos dos funciones en Numpy:
- numpy.loadtxt() : se usa para cargar datos de archivos de texto
- numpy.genfromtxt( ) : se utiliza para cargar datos de un archivo de texto, y los valores faltantes se manejan según lo definido.
Nota: numpy.loadtxt() es una función equivalente a numpy.genfromtxt() cuando no faltan datos.
Método 1: numpy.loadtxt()
Sintaxis:
numpy.loadtxt(fname, dtype = float, comments=’#’, delimitador=Ninguno, convertidores=Ninguno, skiprows=0, usecols=Ninguno, unpack=False, ndmin=0, encoding=’bytes’, max_rows=Ninguno, *, me gusta = Ninguno)
El parámetro de tipo de datos predeterminado (dtype) para numpy.loadtxt() es float.
Ejemplo 1: Importación de archivos de texto en arrays Numpy
En este ejemplo se considera el siguiente archivo de texto ‘example1.txt’.
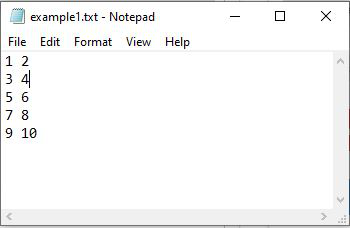
Python3
import numpy as np
# Text file data converted to integer data type
File_data = np.loadtxt("example1.txt", dtype=int)
print(File_data)
Producción :
[[ 1 2] [ 3 4] [ 5 6] [ 7 8] [ 9 10]]
Ejemplo 2: importar un archivo de texto a la array NumPy omitiendo la primera fila
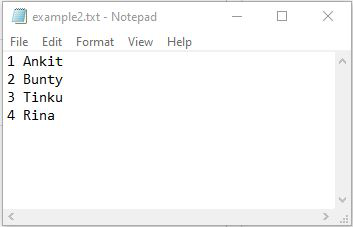
Python3
import numpy as np
# skipping first row
# converting file data to string
data = np.loadtxt("example2.txt", skiprows=1, dtype='str')
print(data)
Producción :
[['2' 'Bunty'] ['3' 'Tinku'] ['4' 'Rina']]
Ejemplo 3: importar solo la primera columna (Nombres) del archivo de texto en arrays numpy
La indexación en arrays NumPy comienza desde 0. Por lo tanto, la columna Roll en el archivo de texto es la columna 0 , la columna Names es la 1 st columna y Marks es la 2 nd columna en el archivo de texto ‘example3.txt’.
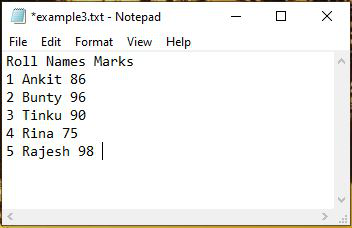
Python3
import numpy as np
# only column1 data is imported into numpy
# array from text file
data = np.loadtxt("example3.txt", usecols=1, skiprows=1, dtype='str')
for each in data:
print(each)
Producción :
Ankit Bunty Tinku Rina Rajesh
Método 2: numpy.genfromtxt()
Sintaxis:
numpy.genfromtxt(fname, dtype=float, comments=’#’, delimitador=Ninguno, skip_header=0, skip_footer=0, converters=Ninguno, valores_faltantes=Ninguno, valores_de_llenado=Ninguno, usecols=Ninguno, nombres=Ninguno,excludelist= Ninguno, deletechars=” !#$%&'()*+, -./:;<=>?@[\\]^{|}~”, replace_space=’_’, autostrip=False, case_Sensible=True , defaultfmt=’f%i’, unpack=Ninguno, usemask=False, loose=True, invalid_raise=True, max_rows=Ninguno, encoding=’bytes’, *, like=Ninguno)
Excepto fname(nombre de archivo) en numpy.genfromtxt(), todos los demás parámetros son opcionales.
Ejemplo 1:
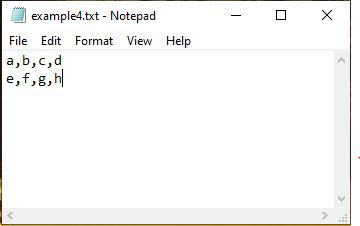
Python3
import numpy as np
Data = np.genfromtxt("example4.txt", dtype=str,
encoding=None, delimiter=",")
print(Data)
Producción :
[['a' 'b' 'c' 'd'] ['e' 'f' 'g' 'h']]
Ejemplo 2: importar un archivo de texto en arrays numpy omitiendo la última fila
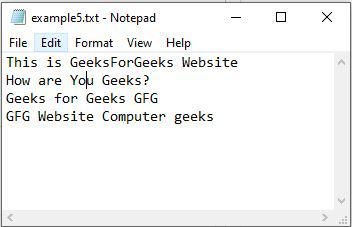
Python3
import numpy as np
# skipping last line in the file
Data = np.genfromtxt("example5.txt", dtype=str,
encoding=None, skip_footer=1)
print(Data)
Producción :
[['This' 'is' 'GeeksForGeeks' 'Website'] ['How' 'are' 'You' 'Geeks?'] ['Geeks' 'for' 'Geeks' 'GFG']]
Publicación traducida automáticamente
Artículo escrito por greeshmanalla y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA