La impresión de líneas que contienen una string en particular al principio es bastante molesta de manejar manualmente, por lo que podemos usar bash para diseñar un script de shell. La herramienta más versátil y poderosa para buscar patrones o líneas es usar grep , awk o sed para encontrar la solución más eficiente al problema.
Lo primero con lo que debe comenzar es el archivo en el que se buscará la string y también la string. Ambos parámetros serán ingresados por el usuario. Después de eso, podemos usar cualquiera de las tres herramientas grep, sed o awk. El concepto es el mismo, necesitamos encontrar la string solo al comienzo de una línea usando expresiones regulares e imprimir las líneas según la herramienta que se utilizará.
Entrada del usuario
Ingresaremos el nombre del archivo y la string del usuario. Usaremos el comando de lectura y pasaremos el argumento -p para indicarle al usuario un texto para mostrar lo que debe ingresar. Almacenaremos la entrada en los nombres de variable apropiados.
#!/bin/bash
read -p “Ingrese el nombre del archivo:” archivo
read -p “Ingrese la string a buscar en el archivo:” str
Búsqueda e impresión de líneas
Las siguientes son las tres herramientas que se utilizan para realizar la operación de búsqueda e impresión de líneas que tienen una string de entrada del usuario. Cualquiera puede ser utilizado según la elección y los requisitos del usuario.
Método 1: usar el comando GREP
El comando grep es bastante útil para encontrar patrones en el archivo o strings en la línea. Usaremos el comando grep simple que busca la palabra al principio del archivo usando el operador ^ e imprime la línea del archivo. Esto es bastante sencillo de entender si está familiarizado con el comando grep en Linux. El comando grep simplemente buscará la string/palabra de entrada del archivo e imprimirá la línea en la que aparece la string solo al principio. El último argumento, que es “ grep -v grep || true” solo devuelve 0 si el grep no encontró ninguna coincidencia . Esto no mostrará el molesto error de shell return 1, no imprimirá nada y el usuario entenderá que ninguna línea comenzó con esa string en el archivo.
#!/bin/bash
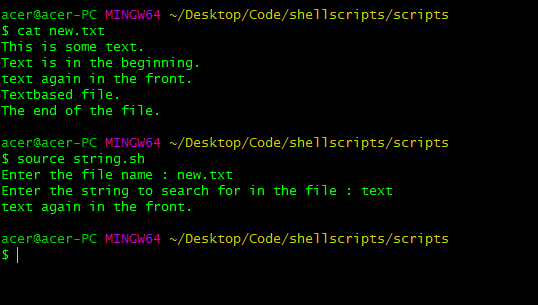
read -p "Enter the file name : " file
read -p "Enter the string to search for in the file : " str
grep "^$str" $file | { grep -v grep || true; }
usando el comando grep para buscar strings al comienzo de las líneas.
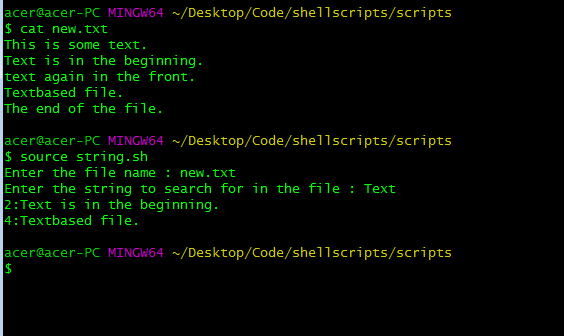
El comando grep también es un poco flexible, ya que también nos permite imprimir los números de línea. Podemos imprimir los números de línea agregando algunos argumentos al comando anterior. El argumento -n después de grep imprimirá el número de línea en el que se encuentra la string en el archivo.
#!/bin/bash
read -p "Enter the file name : " file
read -p "Enter the string to search for in the file : " str
grep -n "^$str" $file | { grep -v grep || true; }
usando el comando grep para buscar strings al comienzo de las líneas e imprimir números de línea.
Ambos casos en grep distinguirán entre mayúsculas y minúsculas. Para hacer que la búsqueda no distinga entre mayúsculas y minúsculas, puede agregar el argumento -i justo después de grep como,
grep -i "^$str" $file | { grep -v grep || true; }
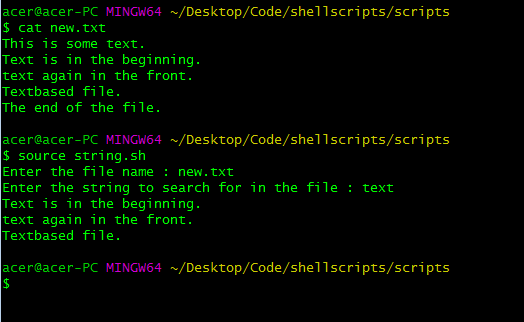
usando el comando grep para buscar strings que no distinguen entre mayúsculas y minúsculas al comienzo de las líneas.
Método 2: Uso del comando SED
El comando sed es diferente al comando grep, ya que es un editor de secuencias y no un comando para simplemente pasar argumentos. Necesitamos usar -n para que el comando no imprima todo desde el archivo provisto en el último argumento del comando a continuación. La siguiente expresión regular buscará la variable de string e imprimirá todas las líneas coincidentes. Y el resultado será una salida compacta. La expresión regular utilizada es simple y similar a grep, ya que coincide con la string solo al comienzo de la línea usando el operador ^ y las barras invertidas significan que la expresión es una expresión regular. El argumento p imprimirá las líneas que coincidan con la expresión regular. Ambos casos en grep distinguirán entre mayúsculas y minúsculas.
#!/bin/bash read -p "Enter the file name : " file read -p "Enter the string to search for in the file : " str sed -n "/^$str/p" $file
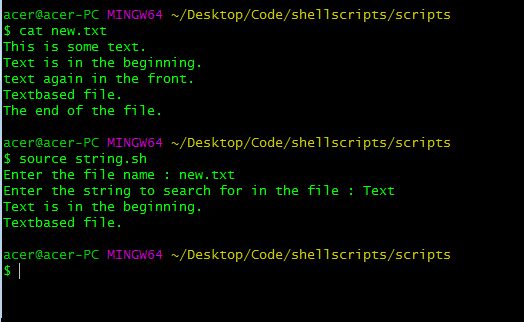
usando el comando sed para buscar strings al comienzo de las líneas.
gnu sed no admite búsquedas o coincidencias que no distingan entre mayúsculas y minúsculas. Aún así, puede usar Perl para agregar coincidencias que no distingan entre mayúsculas y minúsculas.
Método 3: usar el comando AWK
La expresión regular para el comando AWK también es la misma y hace lo mismo en su propio estilo de comando. La expresión regular es casi similar al comando sed, que busca la variable de string, al principio, usando el operador ^ y luego simplemente imprime las líneas coincidentes del comando. Ambos casos en grep distinguirán entre mayúsculas y minúsculas.
#!/bin/bash
read -p "Enter the file name : " file
read -p "Enter the string to search for in the file : " str
awk "/^$str/{print}" $file
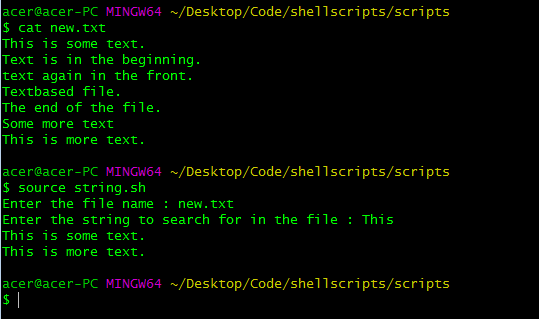
usando el comando awk para buscar strings al comienzo de las líneas.
Para que la búsqueda en awk no distinga entre mayúsculas y minúsculas, puede realizar algunos cambios en el mismo comando.
awk "BEGIN {IGNORECASE = 1} /^$str/{print}" $file
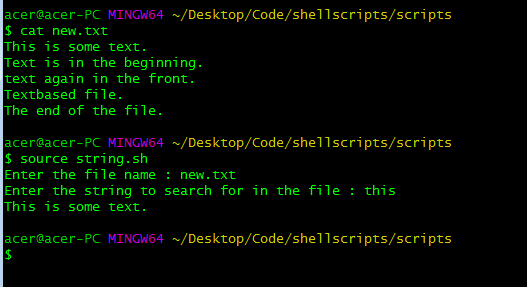
usando el comando awk para buscar strings que no distingan entre mayúsculas y minúsculas al comienzo de las líneas.
El comando awk tiene algunas funciones incorporadas que establecen los argumentos como predeterminados para distinguir entre mayúsculas y minúsculas, podemos cambiar las propiedades de los comandos awk.