La ingeniería de características es la técnica más importante utilizada en la creación de modelos de aprendizaje automático. La ingeniería de características es un término básico que se usa para cubrir muchas operaciones que se realizan en las variables (características) para encajarlas en el algoritmo. Ayuda a aumentar la precisión del modelo, por lo que mejora los resultados de las predicciones. Los modelos de aprendizaje automático con ingeniería de funciones funcionan mejor con los datos que los modelos básicos de aprendizaje automático. Los siguientes aspectos de la ingeniería de características son los siguientes:
- Escalado de características: se realiza para obtener las características en la misma escala (por ejemplo, distancia euclidiana).
- Transformación de características: se realiza para normalizar los datos (características) mediante una función.
- Construcción de funciones: se realiza para crear nuevas funciones basadas en descriptores originales para mejorar la precisión del modelo predictivo.
- Reducción de características. : Se realiza para mejorar la distribución estadística y la precisión del modelo predictivo.
Teoría
El método de construcción de características ayuda a crear nuevas características en los datos, lo que aumenta la precisión del modelo y las predicciones generales. Es de dos tipos:
- Binning: se crean contenedores para variables continuas.
- Codificación: las variables o características numéricas se forman a partir de variables categóricas.
Agrupación
El agrupamiento se realiza para crear contenedores para variables continuas donde se convierten en variables categóricas. Hay dos tipos de agrupamiento: no supervisado y supervisado .
- El agrupamiento no supervisado implica un agrupamiento automático y manual. En Automatic Binning, los bins se crean sin interferencia humana y se crean automáticamente. En Binning manual, los bins se crean con la intervención humana y especificamos dónde se crearán los bins.
- El agrupamiento supervisado implica la creación de contenedores para la variable continua mientras se tiene en cuenta también la variable de destino .
Codificación
La codificación es el proceso en el que se crean variables numéricas o características a partir de variables categóricas. Es un método ampliamente utilizado en la industria y en todos los procesos de construcción de modelos. Es de dos tipos: Codificación de etiquetas y Codificación One-hot .
- La codificación de etiquetas implica asignar a cada etiqueta un entero o valor único según el orden alfabético. Es la codificación más popular y ampliamente utilizada.
- La codificación One-hot implica la creación de funciones o variables adicionales sobre la base de valores únicos en variables categóricas, es decir, cada valor único en la categoría se agregará como una nueva función.
Implementación en R
El conjunto de datos
BigMartEl conjunto de datos consta de 1559 productos en 10 tiendas en diferentes ciudades. Se han definido ciertos atributos de cada producto y tienda. Consta de 12 características, es decir, Item_Identifier (es una identificación de producto única asignada a cada artículo distinto), Item_Weight (incluye el peso del producto), Item_Fat_Content (describe si el producto es bajo en grasa o no), Item_Visibility (menciona el porcentaje de la área de exhibición total de todos los productos en una tienda asignados a un producto en particular), Item_Type (describe la categoría de alimentos a la que pertenece el artículo), Item_MRP (Precio máximo de venta al público (precio de lista) del producto), Outlet_Identifier (ID de tienda único asignado. Consiste en una string alfanumérica de longitud 6), Outlet_Establishment_Year (menciona el año en que se estableció la tienda),
R
# Loading data
train = fread("Train_UWu5bXk.csv")
test = fread("Test_u94Q5KV.csv")
# Structure
str(train)
Producción:
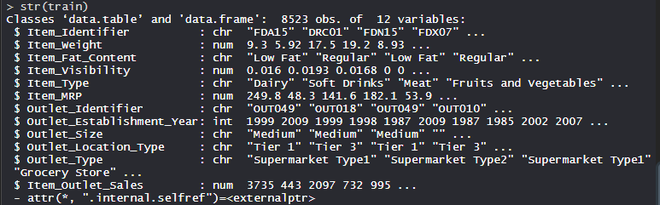
Realizar ingeniería de características en el conjunto de datos
Usando el método de construcción de funciones en el conjunto de datos que incluye 12 funciones con 1559 productos en 10 tiendas en diferentes ciudades.
R
# Loading packages
library(data.table) # used for reading and manipulation of data
library(dplyr) # used for data manipulation and joining
library(ggplot2) # used for ploting
library(caret) # used for modeling
library(e1071) # used for removing skewness
library(corrplot) # used for making correlation plot
library(xgboost) # used for building XGBoost model
library(cowplot) # used for combining multiple plots
# Importing datasets
train = fread("Train_UWu5bXk.csv")
test = fread("Test_u94Q5KV.csv")
# Structure of dataset
str(train)
# Setting test dataset
# Combining datasets
# add Item_Outlet_Sales to test data
test[, Item_Outlet_Sales := NA]
combi = rbind(train, test)
# Missing Value Treatment
missing_index = which(is.na(combi$Item_Weight))
for(i in missing_index){
item = combi$Item_Identifier[i]
combi$Item_Weight[i] = mean(combi$Item_Weight
[combi$Item_Identifier == item],
na.rm = T)
}
# Feature Engineering
# Feature Transformation
# Replacing 0 in Item_Visibility with mean
zero_index = which(combi$Item_Visibility == 0)
for(i in zero_index){
item = combi$Item_Identifier[i]
combi$Item_Visibility[i] = mean(
combi$Item_Visibility[combi$Item_Identifier == item],
na.rm = T
)
}
# Feature Construction
# Create a new feature 'Item_Type_new'
perishable = c("Breads", "Breakfast", "Dairy",
"Fruits and Vegetables", "Meat", "Seafood")
non_perishable = c("Baking Goods", "Canned", "Frozen Foods",
"Hard Drinks", "Health and Hygiene",
"Household", "Soft Drinks")
combi[,Item_Type_new := ifelse(Item_Type %in% perishable, "perishable",
ifelse(Item_Type %in% non_perishable,
"non_perishable", "not_sure"))]
combi[,Item_category := substr(combi$Item_Identifier, 1, 2)]
combi$Item_Fat_Content[combi$Item_category == "NC"] = "Non-Edible"
# Years of operation of Outlets
combi[,Outlet_Years := 2013 - Outlet_Establishment_Year]
combi$Outlet_Establishment_Year = as.factor(combi$Outlet_Establishment_Year)
# Price per unit weight
combi[,price_per_unit_wt := Item_MRP/Item_Weight]
# Label Encoding
combi[,Outlet_Size_num := ifelse(Outlet_Size == "Small", 0,
ifelse(Outlet_Size == "Medium", 1, 2))]
combi[,Outlet_Location_Type_num := ifelse(Outlet_Location_Type == "Tier 3", 0,
ifelse(Outlet_Location_Type == "Tier 2", 1, 2))]
combi[, c("Outlet_Size", "Outlet_Location_Type") := NULL]
# One-hot Encoding
ohe = dummyVars("~.", data = combi[,-c("Item_Identifier",
"Outlet_Establishment_Year",
"Item_Type")], fullRank = T)
ohe_df = data.table(predict(ohe, combi[,-c("Item_Identifier",
"Outlet_Establishment_Year",
"Item_Type")]))
combi = cbind(combi[,"Item_Identifier"], ohe_df)
# Removing Skewness
skewness(combi$Item_Visibility)
skewness(combi$price_per_unit_wt)
combi[,Item_Visibility := log(Item_Visibility + 1)]
combi[,price_per_unit_wt := log(price_per_unit_wt + 1)]
# Scaling and Centering data
# index of numeric features
num_vars = which(sapply(combi, is.numeric))
num_vars_names = names(num_vars)
combi_numeric = combi[,setdiff(num_vars_names,
"Item_Outlet_Sales"), with = F]
prep_num = preProcess(combi_numeric, method=c("center", "scale"))
combi_numeric_norm = predict(prep_num, combi_numeric)
# Transforming Features
combi[,setdiff(num_vars_names, "Item_Outlet_Sales") := NULL]
combi = cbind(combi, combi_numeric_norm)
# Splitting data
train = combi[1:nrow(train)]
test = combi[(nrow(train) + 1):nrow(combi)]
# Removing Item_Outlet_Sales
test[,Item_Outlet_Sales := NULL]
# Model Building - xgboost
para_list = list(
objective = "reg:linear",
eta=0.01,
gamma = 1,
max_depth=6,
subsample=0.8,
colsample_bytree=0.5
)
# D Matrix
d_train = xgb.DMatrix(data = as.matrix(train[,-c("Item_Identifier",
"Item_Outlet_Sales")]),
label= train$Item_Outlet_Sales)
d_test = xgb.DMatrix(data = as.matrix(test[,-c("Item_Identifier")]))
# K-fold cross validation
set.seed(123) # Setting seed
xgb_cv = xgb.cv(params = para_list,
data = d_train,
nrounds = 1000,
nfold = 5,
print_every_n = 10,
early_stopping_rounds = 30,
maximize = F)
# Training model
model_xgb = xgb.train(data = d_train,
params = para_list,
nrounds = 428)
model_xgb
# Variable Importance Plot
variable_imp = xgb.importance(feature_names = setdiff(names(train),
c("Item_Identifier", "Item_Outlet_Sales")),
model = model_xgb)
xgb.plot.importance(variable_imp)
Producción:
- Modelo modelo_xgb:
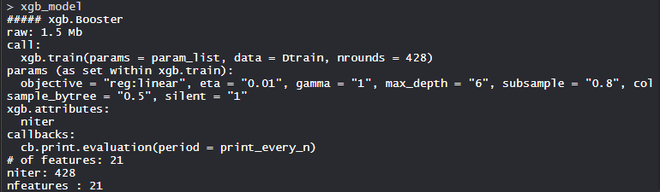
El modelo XgBoost consta de 21 funciones con el objetivo de regresión lineal, eta es 0,01, gamma es 1, max_ depth es 6, colsample_bytree = 0,5 y silent es 1.
- Gráfica de importancia variable:
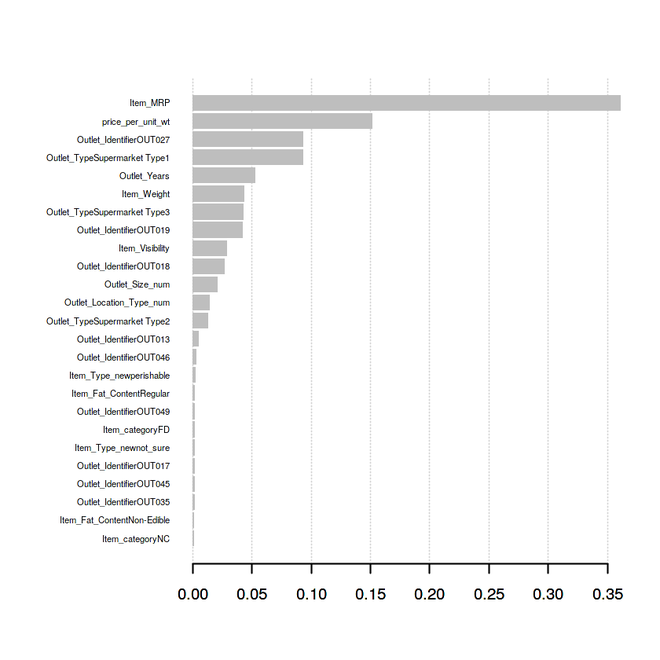
price_per_unit_wt es la segunda variable o característica más importante del modelo predictivo, seguida de Outlet_Years, que es la sexta variable o característica más importante del modelo predictivo. Las características Item_category, Item_Type_new desempeñaron un papel importante en la mejora del modelo predictivo y, por lo tanto, en la mejora de la precisión del modelo. Por lo tanto, Feature Engineering es el método más importante para construir un modelo predictivo eficiente, escalable y preciso.