La ingesta de datos es el proceso de transferencia de datos, desde diversas fuentes a un enfoque, donde un establecimiento puede analizarlos, archivarlos o utilizarlos. Los pasos habituales involucrados en este proceso son extraer datos de su ubicación actual, convertirlos y, finalmente, cargarlos en una ubicación para una investigación eficiente. Python proporciona muchas herramientas de este tipo y marcos para la ingesta de datos. Estos incluyen Bonobo, Beautiful Soup4, Airflow, Pandas, etc. En este artículo, aprenderemos sobre la ingesta de datos con la biblioteca Pandas.
Ingestión de datos con Pandas:
La ingesta de datos con Pandas es el proceso de cambiar datos, desde una variedad de fuentes, a la estructura de Pandas DataFrame. La fuente de datos puede ser de varios formatos de archivo, como datos separados por comas, JSON, tabla de página web HTML, Excel. En este artículo, aprenderemos a transferir datos, desde dichos formatos, al destino, que es un objeto de marco de datos de Pandas.
Acercarse:
El enfoque básico, para transferir dichos datos a un objeto de marco de datos, es el siguiente:
- Prepare sus datos de origen.
- Los datos pueden estar presentes en cualquier servidor remoto o en una máquina local. Necesitamos saber la URL del archivo si está en un servidor remoto. Se requiere la ruta del archivo, en la máquina local, si los datos están presentes localmente.
- Utilice el método Pandas ‘read_x’
- Pandas proporciona métodos ‘read_x’, para cargar y convertir los datos, en un objeto Dataframe.
- Dependiendo del formato de datos, use el método de ‘lectura’.
- Imprimir datos del objeto DataFrame.
- Imprima el objeto del marco de datos para verificar que la conversión se realizó sin problemas.
Formatos de archivo para ingesta:
En este artículo, convertiremos los datos presentes en los siguientes archivos en estructuras de tramas de datos:
- Leer datos del archivo CSV
- Leer datos de un archivo de Excel
- Leer datos del archivo JSON
- Leer datos del Portapapeles
- Leer datos de la tabla HTML de la página web
- Leer datos de la tabla SQLite
Leer datos del archivo CSV
Para cargar los datos presentes en un archivo separado por comas (CSV), seguiremos los pasos a continuación:
- Prepare su conjunto de datos de muestra. Aquí tenemos un archivo CSV que contiene información sobre las ciudades metropolitanas de la India. Describe si la ciudad es una ciudad Tier1 o Tier2, su ubicación geográfica, estado al que pertenece y si es una ciudad costera.
- Utilice el método de Pandas ‘read_csv’
- Método utilizado: read_csv (file_path)
- Parámetro: formato de string que contiene la ruta del archivo y su nombre, o URL cuando está presente en el servidor remoto. Lee los datos del archivo y los convierte en un objeto de marco de datos bidimensional válido. Este método se puede utilizar para leer datos, presentes en formatos de archivo «.csv» y «.txt».
El contenido del archivo es el siguiente:
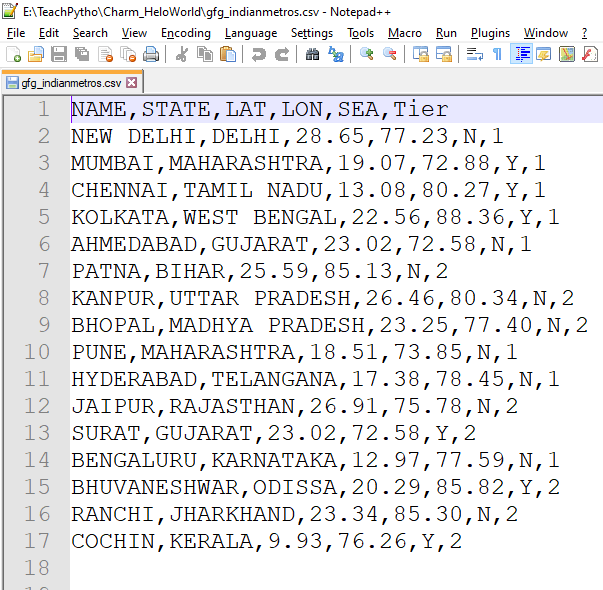
El contenido del archivo “gfg_indianmetros.csv”
El código para obtener los datos en un marco de datos de Pandas es:
Python
# Import the Pandas library
import pandas
# Load data from Comma separated file
# Use method - read_csv(filepath)
# Parameter - the path/URL of the CSV/TXT file
dfIndianMetros = pandas.read_csv("gfg_indianmetros.csv")
# print the dataframe object
print(dfIndianMetros)
Producción:
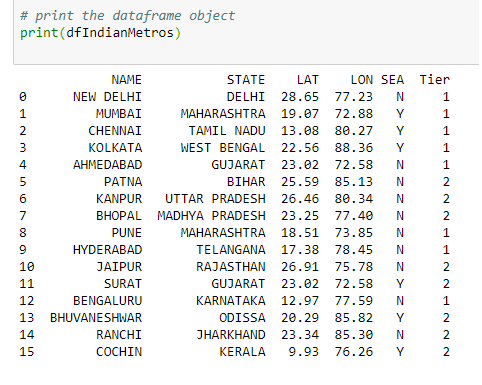
Los datos CSV, en objeto de marco de datos
Leer datos de un archivo de Excel
Para cargar datos presentes en un archivo de Excel (.xlsx, .xls), seguiremos los pasos a continuación:
- Prepare su conjunto de datos de muestra. Aquí tenemos un archivo de Excel que contiene información sobre Bakery y sus sucursales. Describe el número de empleados, dirección de sucursales de la panadería.
- Utilice el método de Pandas ‘read_excel’.
- Método utilizado: read_excel (file_path)
- Parámetro – El método acepta, la ruta del archivo y su nombre, en formato de string como parámetro. El archivo puede estar en un servidor remoto o en una máquina local. Lee los datos del archivo y los convierte en un objeto de marco de datos bidimensional válido. Este método se puede utilizar para leer datos presentes en formatos de archivo «.xlsx» y «.xls».
El contenido del archivo es el siguiente:
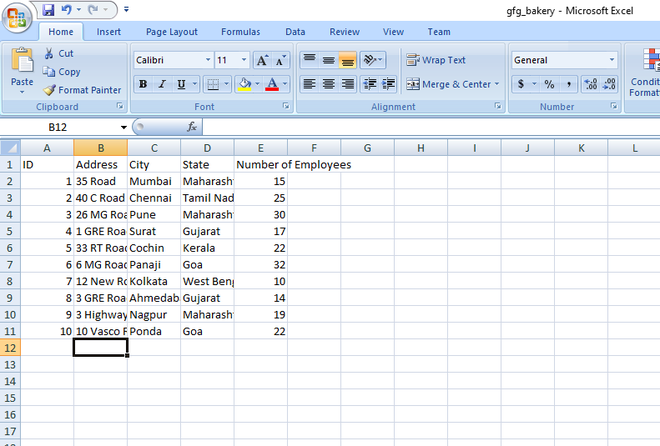
El contenido del archivo «gfg_bakery.xlsx»
El código para obtener los datos en un Pandas DataFrame es:
Python
# Import the Pandas library
import pandas
# Load data from an Excel file
# Use method - read_excel(filepath)
# Method parameter - The file location(URL/path) and name
dfBakery = pandas.read_excel("gfg_bakery.xlsx")
# print the dataframe object
print(dfBakery)
Producción:
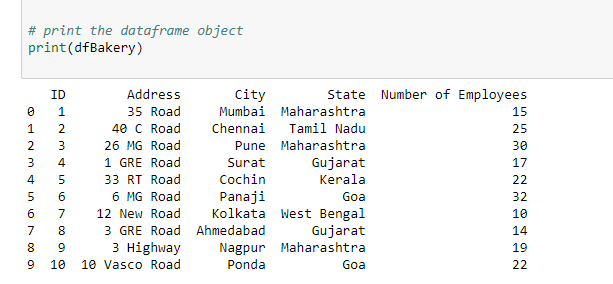
Los datos de Excel, en objeto de marco de datos
Leer datos de un archivo JSON
Para cargar datos presentes en un archivo de notación de objetos de JavaScript (.json), seguiremos los pasos a continuación:
- Prepare su conjunto de datos de muestra. Aquí tenemos un archivo JSON que contiene información sobre los países y su código de marcación.
- Use el método Pandas ‘read_json’.
- Método utilizado: read_json (file_path)
- Parámetro: este método acepta la ruta del archivo y su nombre, en formato de string, como parámetro. Lee los datos del archivo y los convierte en un objeto de marco de datos bidimensional válido.
El contenido del archivo es el siguiente:
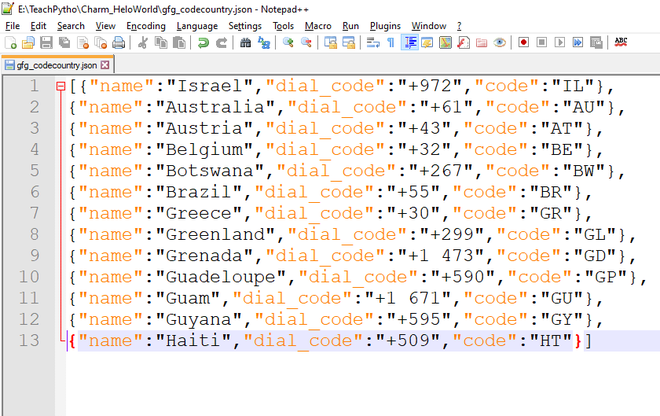
El contenido del archivo «gfg_codecountry.json»
El código para obtener los datos en un Pandas DataFrame es:
Python
# Import the Pandas library
import pandas
# Load data from a JSON file
# Use method - read_json(filepath)
# Method parameter - The file location(URL/path) and name
dfCodeCountry = pandas.read_json("gfg_codecountry.json")
# print the dataframe object
print(dfCodeCountry)
Producción:
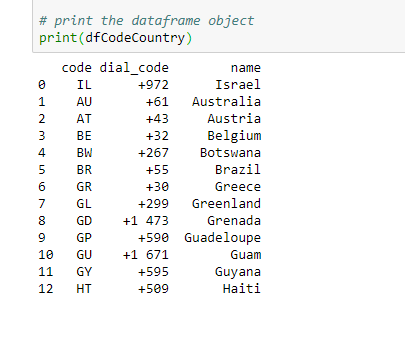
Los datos JSON, en objetos de marco de datos
Leer datos del Portapapeles
También podemos transferir datos presentes en el Portapapeles a un objeto de marco de datos. Un portapapeles es una parte de la memoria de acceso aleatorio (RAM), donde están presentes los datos copiados. Siempre que copiamos cualquier archivo, texto, imagen o cualquier tipo de dato, mediante el comando ‘Copiar’, se almacena en el Portapapeles. Para convertir los datos presentes aquí, siga los pasos que se mencionan a continuación:
- Seleccione todo el contenido del archivo. El archivo debe ser un archivo CSV. También puede ser un archivo ‘.txt’, que contiene valores separados por comas, como se muestra en el ejemplo. Tenga en cuenta que si el contenido del archivo no está en un formato favorable, puede obtener un error del analizador en tiempo de ejecución.
- Derecha, haga clic y diga Copiar. Ahora, estos datos se transfieren al Portapapeles de la computadora.
- Use el método de Pandas ‘read_clipboard’ .
- Método utilizado – read_clipboard
- Parámetro – El método, no acepta ningún parámetro. Lee los últimos datos copiados como presentes en el portapapeles y los convierte en un objeto de marco de datos bidimensional válido.
El contenido del archivo seleccionado es el siguiente:
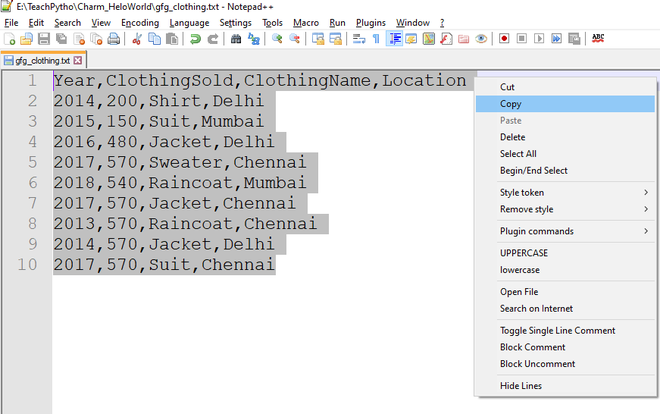
El contenido del archivo “gfg_clothing.txt”
El código para obtener los datos en un Pandas DataFrame es:
Python
# Import the required library import pandas # Copy file contents which are in proper format # Whatever data you have copied will # get transferred to dataframe object # Method does not accept any parameter pdCopiedData = pd.read_clipboard() # Print the data frame object print(pdCopiedData)
Producción:
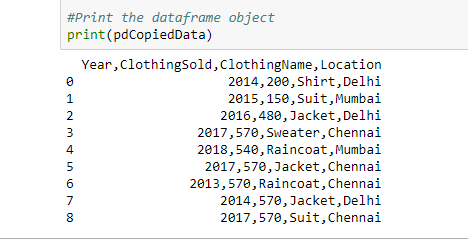
Los datos del portapapeles, en objeto de marco de datos
Leer datos del archivo HTML
Una página web generalmente está hecha de elementos HTML. Hay diferentes etiquetas HTML como <head>, <title>, <table>, <div> según el propósito de la visualización de datos en el navegador. Podemos transferir el contenido entre el elemento <table>, presente en una página web HTML, a un objeto de marco de datos de Pandas. Siga los pasos que se mencionan a continuación –
- Seleccione todos los elementos presentes en la <tabla>, entre las etiquetas de inicio y finalización. Asígnelo a una variable de Python.
- Use el método Pandas ‘read_html’ .
- Método utilizado: read_html (string dentro de la etiqueta <table>)
- Parámetro: el método acepta una variable de string que contiene los elementos presentes entre la etiqueta <table>. Lee los elementos, recorriendo la tabla, las etiquetas <tr> y <td>, y los convierte en un objeto de lista. El primer elemento del objeto de lista es el objeto de marco de datos deseado.
La página web HTML utilizada es la siguiente:
HTML
<!DOCTYPE html> <html> <head> <title>Data Ingestion with Pandas Example</title> </head> <body> <h2>Welcome To GFG</h2> <table> <thead> <tr> <th>Date</th> <th>Empname</th> <th>Year</th> <th>Rating</th> <th>Region</th> </tr> </thead> <tbody> <tr> <td>2020-01-01</td> <td>Savio</td> <td>2004</td> <td>0.5</td> <td>South</td> </tr> <tr> <td>2020-01-02</td> <td>Rahul</td> <td>1998</td> <td>1.34</td> <td>East</td> </tr> <tr> <td>2020-01-03</td> <td>Tina</td> <td>1988</td> <td>1.00023</td> <td>West</td> </tr> <tr> <td>2021-01-03</td> <td>Sonia</td> <td>2001</td> <td>2.23</td> <td>North</td> </tr> </tbody> </table> </body> </html>
Escriba el siguiente código para convertir el contenido de la tabla HTML en el objeto Pandas Dataframe:
Python
# Import the Pandas library import pandas # Variable containing the elements # between <table> tag from webpage html_string = """ <table> <thead> <tr> <th>Date</th> <th>Empname</th> <th>Year</th> <th>Rating</th> <th>Region</th> </tr> </thead> <tbody> <tr> <td>2020-01-01</td> <td>Savio</td> <td>2004</td> <td>0.5</td> <td>South</td> </tr> <tr> <td>2020-01-02</td> <td>Rahul</td> <td>1998</td> <td>1.34</td> <td>East</td> </tr> <tr> <td>2020-01-03</td> <td>Tina</td> <td>1988</td> <td>1.00023</td> <td>West</td> </tr> <tr> <td>2021-01-03</td> <td>Sonia</td> <td>2001</td> <td>2.23</td> <td>North</td> </tr> <tr> <td>2008-01-03</td> <td>Milo</td> <td>2008</td> <td>3.23</td> <td>East</td> </tr> <tr> <td>2006-01-03</td> <td>Edward</td> <td>2005</td> <td>0.43</td> <td>West</td> </tr> </tbody> </table>""" # Pass the string containing html table element df = pandas.read_html(html_string) # Since read_html, returns a list object, # extract first element of the list dfHtml = df[0] # Print the data frame object print(dfHtml)
Producción:
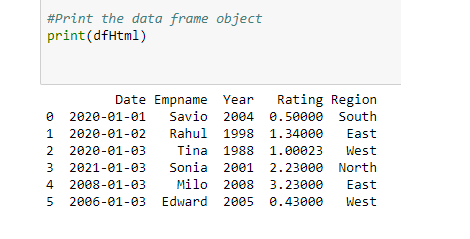
Los datos de la <tabla> HTML, en el objeto del marco de datos,
Leer datos de la tabla SQL
También podemos convertir los datos presentes en las tablas de la base de datos en objetos de marco de datos válidos. Python permite una interfaz fácil, con una variedad de bases de datos, como SQLite, MySQL, MongoDB, etc. SQLite es una base de datos liviana, que puede integrarse en cualquier programa. La base de datos SQLite contiene todas las tablas SQL relacionadas. Podemos cargar datos de tablas de SQLite en un objeto de marco de datos de Pandas. Siga los pasos, como se menciona a continuación:
- Prepare una tabla de SQLite de muestra utilizando ‘DB Browser for SQLite tool’ o cualquier herramienta similar. Estas herramientas permiten la creación y edición sin esfuerzo de archivos de bases de datos compatibles con SQLite. El archivo de la base de datos tiene una extensión de archivo ‘.db’. En este ejemplo, tenemos el archivo ‘Novels.db’ , que contiene una tabla llamada «novels». Esta tabla tiene información sobre las novelas, como el nombre de la novela, el precio, el género, etc.
- Aquí, para conectarnos a la base de datos, importaremos el módulo ‘sqlite3’, en nuestro código. El módulo sqlite3, es una interfaz, para conectarse a las bases de datos SQLite. La biblioteca sqlite3 está incluida en Python, desde la versión 2.5 de Python. Por lo tanto, no se requiere una instalación separada. Para conectarnos a la base de datos, utilizaremos el método ‘conectar’ de SQLite, que devuelve un objeto de conexión. El método connect acepta los siguientes parámetros:
- nombre_base_de_datos : el nombre de la base de datos en la que está presente la tabla. Este es un archivo de extensión .db. Si el archivo está presente, se devuelve un objeto de conexión abierta. Si el archivo no está presente, primero se crea y luego se devuelve un objeto de conexión.
- Use el método de Pandas ‘read_sql_query’.
- Método utilizado: read_sql_query
- Parámetro: este método acepta los siguientes parámetros
- Consulta SQL: seleccione la consulta para obtener las filas requeridas de la tabla.
- Objeto de conexión: el objeto de conexión devuelto por el método ‘conectar’. El método read_sql_query convierte las filas resultantes de la consulta en un objeto de marco de datos.
- Imprima el objeto del marco de datos utilizando el método de impresión.
El archivo de base de datos Novels.db tiene el siguiente aspecto:
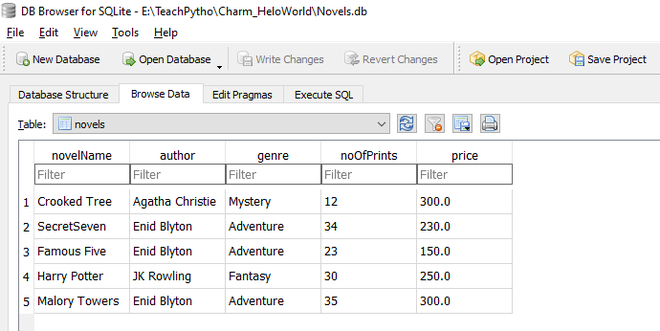
La tabla de novelas, como se ve, usando la herramienta DB Browser for SQLite
Escriba el siguiente código para convertir la tabla Novels, en el objeto del marco de datos de Pandas:
Python
# Import the required libraries
import sqlite3
import pandas
# Prepare a connection object
# Pass the Database name as a parameter
conn = sqlite3.connect("Novels.db")
# Use read_sql_query method
# Pass SELECT query and connection object as parameter
pdSql = pd.read_sql_query("SELECT * FROM novels", conn)
# Print the dataframe object
print(pdSql)
# Close the connection object
conn.close()
Producción:
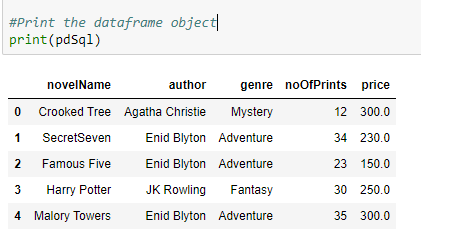
Los datos de la tabla Novels en el objeto dataframe
Publicación traducida automáticamente
Artículo escrito por phadnispradnya y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA