Apache Pig es una herramienta de manipulación de datos construida sobre MapReduce de Hadoop. Pig nos proporciona un lenguaje de secuencias de comandos para una manipulación de datos más fácil y rápida. Este lenguaje de scripting se llama Pig Latin.
Los scripts de Apache Pig se pueden ejecutar de 3 maneras de la siguiente manera:
- Usando Grunt Shell (modo interactivo): escriba los comandos en el grunt shell y obtenga la salida allí mismo usando el comando DUMP.
- Uso de secuencias de comandos Pig (modo por lotes): escriba los comandos latinos de Pig en un solo archivo con extensión .pig y ejecute la secuencia de comandos en el indicador.
- Uso de funciones definidas por el usuario (modo integrado): escriba sus propias funciones en lenguajes como Java y luego utilícelas en los scripts.
Instalación de cerdo:
Antes de continuar, debe asegurarse de tener todos estos requisitos previos de la siguiente manera.
- Hadoop Ecosystem instalado en su sistema y los cuatro componentes, es decir, DataNode, NameNode, ResourceManager, TaskManager, están funcionando. Si alguno de ellos se apaga aleatoriamente, debe arreglarlo antes de continuar.
- Se requiere 7-Zip para extraer los archivos .tar.gz en Windows.
Echemos un vistazo a Cómo instalar la versión Pig (0.17.0) en Windows de la siguiente manera.
Paso 1: Descargue el archivo tar Pig versión 0.17.0 del sitio oficial de Apache pig. Vaya al sitio web https://downloads.apache.org/pig/latest/ . Descargue el archivo ‘pig-0.17.0.tar.gz’ del sitio web.
Luego extraiga este archivo tar usando la herramienta 7-Zip (use 7-Zip para una extracción más rápida. Primero extraemos el archivo .tar.gz haciendo clic derecho sobre él y haciendo clic en ‘7-Zip → Extraer aquí’. Luego extraemos el .tar archivo de la misma manera). Para tener las mismas rutas que puede ver en el diagrama, debe extraer en la unidad C:.

Paso 2: agregue las variables de ruta de PIG_HOME y PIG_HOME\bin
Haga clic en el botón de Windows y en la barra de búsqueda escriba ‘Variables de entorno’. Luego haga clic en ‘Editar las variables de entorno del sistema’.

Luego haga clic en ‘Variables de entorno’ en la parte inferior de la pestaña. En la pestaña recién abierta, haga clic en el botón ‘Nuevo’ en la sección de variables de usuario.
Después de presionar nuevo, agregue los siguientes valores en los campos.
Variable Name - PIG_HOME Variable value - C:\pig-0.17.0

Toda la ruta a la carpeta de cerdo extraída en el campo Valor variable. Lo extraje en el directorio ‘C’. Y luego haga clic en Aceptar.

Ahora haga clic en la variable Ruta en las variables del sistema. Esto abrirá una nueva pestaña. Luego haga clic en el botón ‘Nuevo’. Y agregue el valor C:\pig-0.17.0\bin en el cuadro de texto. Luego presione Aceptar hasta que todas las pestañas se hayan cerrado.

Paso 3 : Corrección del archivo de comando Pig
Busque el archivo ‘pig.cmd’ en la carpeta bin del archivo pig (C:\pig-0.17.0\bin)
set HADOOP_BIN_PATH = %HADOOP_HOME%\bin
Encuentra la línea:
set HADOOP_BIN_PATH=%HADOOP_HOME%\bin
Reemplace esta línea por:
set HADOOP_BIN_PATH=%HADOOP_HOME%\libexec
Y guarde este archivo. Finalmente estamos aquí. Ahora ya está todo listo para comenzar a explorar Pig y su entorno.
Hay 2 formas de invocar el caparazón gruñido:
Modo local: todos los archivos se instalan, se accede a ellos y se ejecutan en la propia máquina local. No es necesario utilizar HDFS. El comando para ejecutar Pig en modo local es el siguiente.
pig -x local

Modo MapReduce: Todos los archivos están presentes en el HDFS. Necesitamos cargar estos datos para procesarlos. El comando para ejecutar Pig en modo MapReduce/HDFS es el siguiente.
pig -x mapreduce

1. Descargue el conjunto de datos que contiene datos relacionados con la agricultura sobre cultivos en varias regiones y su área y producción. El enlace para el conjunto de datos: https://www.kaggle.com/abhinand05/crop-production-in-india El conjunto de datos contiene 7 columnas, a saber, las siguientes.
State_Name : chararray ; District_Name : chararray ; Crop_Year : int ; Season : chararray ; Crop : chararray ; Area : int ; Production : int
No of rows: 246092 No of columns: 7

2. Ingrese al modo local de cerdo usando
grunt > pig -x local

3. Cargue el conjunto de datos en el modo local
grunt > agriculture= LOAD 'F:/csv files/crop_production.csv' using PigStorage (',')
as ( State_Name:chararray , District_Name:chararray , Crop_Year:int ,
Season:chararray , Crop:chararray , Area:int , Production:int ) ;

4. Volcar y describir el conjunto de datos agricultura usando
grunt > dump agriculture; grunt > describe agriculture;

5. Ejecutando las consultas PIG en modo local
Puede seguir estas consultas escritas para analizar el conjunto de datos utilizando las diversas funciones y operadores en PIG. Debe seguir todos los pasos anteriores antes de continuar.
Consulta 1: Agrupación de todos los registros por estado.
Este comando agrupará todos los registros por la columna State_Name.
grunt > statewisecrop = GROUP agriculture BY State_Name; grunt > DUMP statewisecrop; grunt > DESCRIBE statewisecrop;

Ahora almacene el resultado de la consulta en un archivo CSV para una mejor comprensión. Tenemos que mencionar el nombre del objeto y la ruta donde se debe almacenar.
pathname -> 'F:/csv files/statewiseoutput' grunt > STORE statewisecrop INTO ‘F:/csv files/statewiseoutput’;

El resultado estará en un archivo llamado ‘part-r-00000’ que debe cambiarse de nombre como ‘ part-r-00000.csv ‘ para abrirlo en formato Excel y hacerlo legible. Encontrará este archivo en la ruta que hemos mencionado en la consulta anterior. En mi caso estaba en la ruta ‘F:/csv files/statewiseoutput/’.
El archivo de salida se verá así:
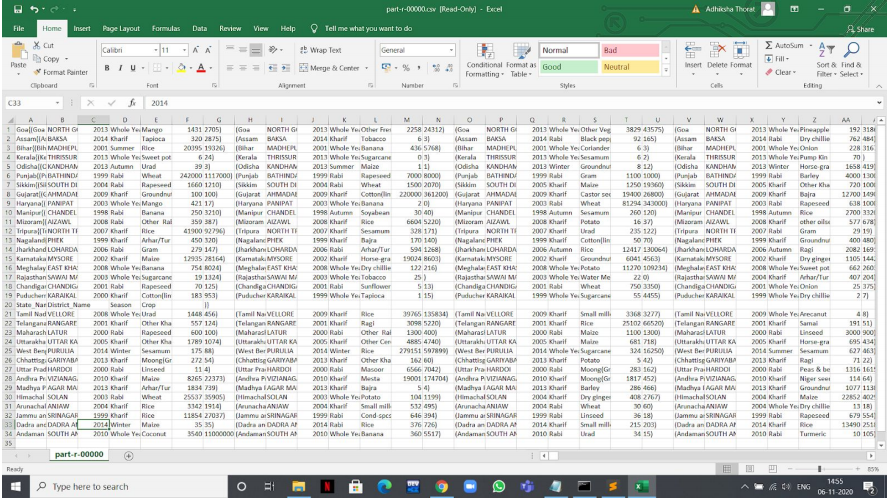
Archivo CSV de salida de la consulta 1
También puede verificar el archivo sin formato abriendo el símbolo del sistema en modo administrador y escribiendo el siguiente comando de la siguiente manera.
C:\Users\Adhiksha\ > Head -2 ‘F:\csv files\statewiseoutput\part-r-00000.csv’;
Este comando devuelve los 2 primeros registros del archivo de resultados de salida por estado. Se parece a esto.

Salida de la consulta número 1
Consulta 2: Generar área y producción total de cultivo inteligente
En la consulta anterior, necesitamos agrupar por tipo de Cultivo y luego encontrar la SUMA de sus Producciones y Área.
grunt > cropinfo = FOREACH( GROUP agriculture BY Crop ) GENERATE group AS Crop, SUM(agriculture.Area) as AreaPerCrop , SUM(agriculture.Production) as ProductionPerCrop; grunt > DESCRIBE cropinfo;

grunt > STORE cropinfo INTO ‘F:/csv files/cropinfooutput’;
La salida estará en un archivo llamado ‘part-r-00000’ que debe cambiarse de nombre como ‘part-r-00000.csv’ para abrirlo en formato Excel y hacerlo legible.
Puede verificar la salida csv abriendo el símbolo del sistema en modo administrador y ejecutando el comando de la siguiente manera.
C:\Users > cat ‘F:/csv files/cropinfooutput/part-r-00000.csv’
Esto devolverá toda la salida en el símbolo del sistema. Puede ver que tenemos tres columnas en la salida.
Producción:
Crop , AreaperCrop , ProductionPerCrop.

Consulta 3: La mayoría de los cultivos se cultivan en una temporada y en qué año.
En esta consulta, necesitamos agrupar los cultivos por temporada y ordenarlos alfabéticamente. Además, esto nos dirá qué cultivos se encuentran en una temporada y con año.
grunt > seasonalcrops = FOREACH (GROUP agriculture by Season ){
order_crops = ORDER agriculture BY Crop ASC;
GENERATE group AS Season , order_crops.(Crop) AS Crops;
};

grunt > DESCRIBE seasonalcrops;

grunt > STORE seasonalcrops INTO ‘F:/csv files/seasonaloutput;
La salida estará en un archivo llamado ‘part-r-00000’ que debe cambiarse de nombre como ‘part-r-00000.csv’ para abrirlo en formato Excel y hacerlo legible. Puede verificar la salida csv abriendo el símbolo del sistema en modo administrador y ejecutando el comando de la siguiente manera.
C:\Users > cat ‘F:/csv files/seasonaloutput/part-r-00000.csv’
Puede verificar la salida de ‘part-r-00000.csv’ abriendo el archivo. Puede ver todas las estaciones distintas en la primera fila seguidas de todos los cultivos y sus años de producción.
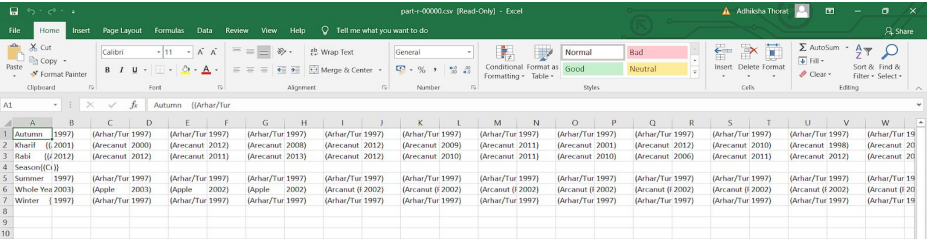
Resultado de esta consulta número 3
Consulta 4: Producción agrícola promedio en cada distrito después del año 2000.
Primero, necesitamos agrupar por nombre de distrito y luego encontrar el promedio de la producción total de cultivos, pero solo después del año 2000.
grunt > averagecrops = FOREACH (GROUP agriculture by District_Name){
after_year = FILTER agriculture BY Crop_Year>2000;
GENERATE group AS District_Name , AVG(after_year.(Production)) AS
AvgProd;
};

grunt > DESCRIBE averagecrops;

grunt > STORE averagecrops INTO ‘F:/csv files/averagecrops;
Puede verificar la salida de ‘part-r-00000.csv’ abriendo el archivo. Este archivo contendrá dos columnas. El primero tiene todos los nombres de distrito distintos y el segundo tendrá la producción promedio de todos los cultivos en cada distrito después del año 2000.
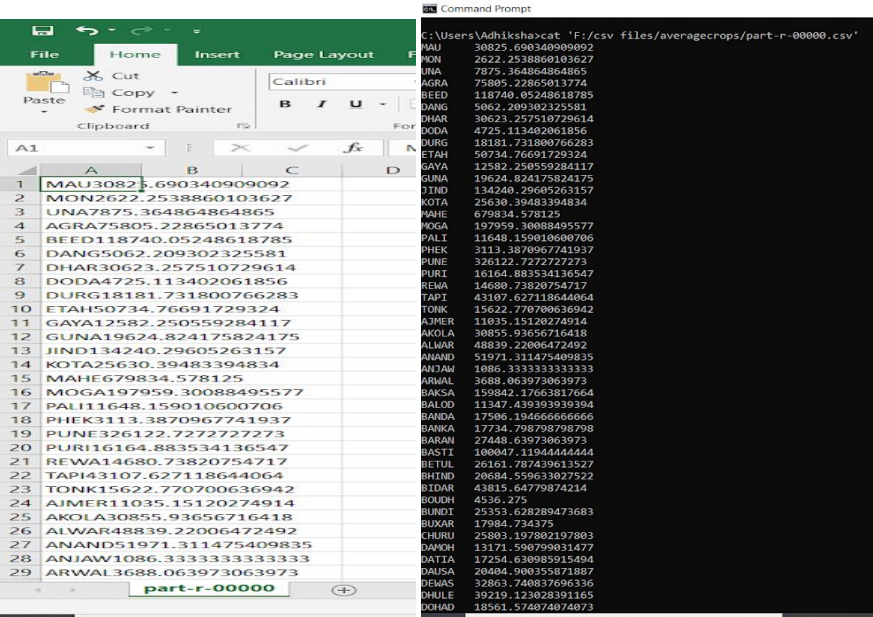
Salida de la consulta número 4
Consulta 5: Cultivos de mayor producción y detalle de cada Estado.
Primero, necesitamos agrupar la entrada por el nombre del estado. Luego itere a través de cada registro agrupado y luego encuentre el registro TOP 1 con la producción más alta de cada estado.
grunt > top_agri= GROUP agriculture BY State_Name;
grunt > data_top = FOREACH top_agri{
top = TOP(1, 6 , agriculture);
GENERATE top as Record;
}

grunt > DESCRIBE cropinfo;

grunt > STORE averagecrops INTO ‘F:/csv files/averagecrops;
Puede verificar la salida de ‘part-r-00000.csv’ abriendo el archivo. Este archivo contiene registros de cada estado único que tiene la mayor cantidad de producción. Lea arriba y siga los pasos para crear ‘part-r-00000.csv’. Puede verificar la salida csv abriendo el símbolo del sistema en modo administrador y ejecutando el comando:
C:\Users > cat ‘F:/csv files/top1prod/part-r-00000.csv’
