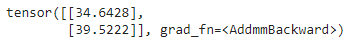Deep Learning es una rama de Machine Learning donde se escriben algoritmos que imitan el funcionamiento de un cerebro humano. Las bibliotecas más utilizadas en el aprendizaje profundo son Tensorflow y PyTorch. Como hay varios marcos de aprendizaje profundo disponibles, uno podría preguntarse cuándo usar PyTorch. Aquí hay razones por las que uno podría preferir usar Pytorch para tareas específicas.
Pytorch es un marco de aprendizaje profundo de código abierto disponible con una interfaz de Python y C++. Pytorch reside dentro del módulo de la antorcha. En PyTorch, los datos que deben procesarse se ingresan en forma de tensor.
Instalación de PyTorch
Si tiene instalado el administrador de paquetes de Anaconda Python en su sistema, al ejecutar el siguiente comando en la terminal se instalará PyTorch:
conda install pytorch torchvision cpuonly -c pytorch
Si desea usar PyTorch sin instalarlo explícitamente en su máquina local, puede usar Google Colab.
Tensores PyTorch
El Pytorch se utiliza para procesar los tensores. Los tensores son arrays multidimensionales como la array NumPy n-dimensional. Sin embargo, los tensores también se pueden usar en GPU, lo que no ocurre en el caso de la array NumPy. PyTorch acelera el cálculo científico de tensores ya que tiene varias funciones incorporadas.
Un vector es un tensor unidimensional y una array es un tensor bidimensional. Una diferencia significativa entre el tensor y la array multidimensional utilizada en C, C++ y Java es que los tensores deben tener el mismo tamaño de columnas en todas las dimensiones. Además, los tensores solo pueden contener tipos de datos numéricos.
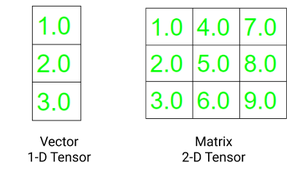
Los dos atributos fundamentales de un tensor son:
- Forma: se refiere a la dimensionalidad del arreglo o array
- Rango: se refiere al número de dimensiones presentes en el tensor
Código:
Python3
# importing torch
import torch
# creating a tensors
t1=torch.tensor([1, 2, 3, 4])
t2=torch.tensor([[1, 2, 3, 4],
[5, 6, 7, 8],
[9, 10, 11, 12]])
# printing the tensors:
print("Tensor t1: \n", t1)
print("\nTensor t2: \n", t2)
# rank of tensors
print("\nRank of t1: ", len(t1.shape))
print("Rank of t2: ", len(t2.shape))
# shape of tensors
print("\nRank of t1: ", t1.shape)
print("Rank of t2: ", t2.shape)
Producción:

Crear tensor en PyTorch
Hay varios métodos para crear un tensor en PyTorch. Un tensor puede contener elementos de un solo tipo de datos. Podemos crear un tensor usando una lista de python o una array NumPy. La antorcha tiene 10 variantes de tensores tanto para GPU como para CPU. A continuación se muestran diferentes formas de definir un tensor.
torch.Tensor() : Copia los datos y crea su tensor. Es un alias de torch.FloatTensor.
torch.tensor() : También copia los datos para crear un tensor; sin embargo, infiere el tipo de datos automáticamente.
torch.as_tensor() : los datos se comparten y no se copian en este caso mientras se crean los datos y acepta cualquier tipo de array para la creación de tensores.
torch.from_numpy() : es similar a tensor.as_tensor() sin embargo, solo acepta arrays numpy.
Código:
Python3
# importing torch module
import torch
import numpy as np
# list of values to be stored as tensor
data1 = [1, 2, 3, 4, 5, 6]
data2 = np.array([1.5, 3.4, 6.8,
9.3, 7.0, 2.8])
# creating tensors and printing
t1 = torch.tensor(data1)
t2 = torch.Tensor(data1)
t3 = torch.as_tensor(data2)
t4 = torch.from_numpy(data2)
print("Tensor: ",t1, "Data type: ", t1.dtype,"\n")
print("Tensor: ",t2, "Data type: ", t2.dtype,"\n")
print("Tensor: ",t3, "Data type: ", t3.dtype,"\n")
print("Tensor: ",t4, "Data type: ", t4.dtype,"\n")
Producción:

Reestructuración de tensores en Pytorch
Podemos modificar la forma y el tamaño de un tensor como deseemos en PyTorch. También podemos crear una transposición de un tensor de nd. A continuación hay tres formas comunes de cambiar la estructura de su tensor según lo desee:
.reshape(a, b) : devuelve un nuevo tensor con tamaño a,b
.resize(a, b) : devuelve el mismo tensor con el tamaño a,b
.transpose(a, b) : devuelve un tensor transpuesto en una dimensión a y b
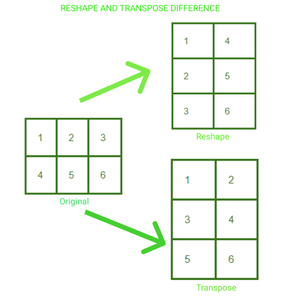
Una array de 2*3 ha sido remodelada y transpuesta a 3*2. Podemos visualizar el cambio en la disposición de los elementos en el tensor en ambos casos.
Código:
Python3
# import torch module
import torch
# defining tensor
t = torch.tensor([[1, 2, 3, 4],
[5, 6, 7, 8],
[9, 10, 11, 12]])
# reshaping the tensor
print("Reshaping")
print(t.reshape(6, 2))
# resizing the tensor
print("\nResizing")
print(t.resize(2, 6))
# transposing the tensor
print("\nTransposing")
print(t.transpose(1, 0))

Operaciones Matemáticas en Tensores en PyTorch
Podemos realizar varias operaciones matemáticas en tensores utilizando Pytorch. El código para realizar operaciones matemáticas es el mismo que en el caso de las arrays NumPy. A continuación se muestra el código para realizar las cuatro operaciones básicas en tensores.
Python3
# import torch module
import torch
# defining two tensors
t1 = torch.tensor([1, 2, 3, 4])
t2 = torch.tensor([5, 6, 7, 8])
# adding two tensors
print("tensor2 + tensor1")
print(torch.add(t2, t1))
# subtracting two tensor
print("\ntensor2 - tensor1")
print(torch.sub(t2, t1))
# multiplying two tensors
print("\ntensor2 * tensor1")
print(torch.mul(t2, t1))
# diving two tensors
print("\ntensor2 / tensor1")
print(torch.div(t2, t1))
Producción:

Para profundizar más en la multiplicación de arrays usando Pytorch, consulte este artículo.
Módulos Pytorch
Los módulos de la biblioteca PyTorch son esenciales para crear y entrenar redes neuronales. Los tres módulos principales de la biblioteca son Autograd, Optim y nn.
# 1. Módulo Autograd: El autograd proporciona la funcionalidad de fácil cálculo de gradientes sin la implementación explícitamente manual del paso hacia adelante y hacia atrás para todas las capas.
Para entrenar cualquier red neuronal, realizamos retropropagación para calcular el gradiente. Llamando a la función .backward() podemos calcular cada gradiente desde la raíz hasta la hoja.
Código:
Python3
# importing torch
import torch
# creating a tensor
t1=torch.tensor(1.0, requires_grad = True)
t2=torch.tensor(2.0, requires_grad = True)
# creating a variable and gradient
z=100 * t1 * t2
z.backward()
# printing gradient
print("dz/dt1 : ", t1.grad.data)
print("dz/dt2 : ", t2.grad.data)
Producción:

# 2. Optim Module: PyTorch Optium Module que ayuda en la implementación de varios algoritmos de optimización. Este paquete contiene los algoritmos más utilizados, como Adam, SGD y RMS-Prop. Para usar torch.optim, primero debemos construir un objeto Optimizer que mantendrá los parámetros y los actualizará en consecuencia. Primero, definimos el Optimizador proporcionando el algoritmo optimizador que queremos usar. Establecemos los gradientes en cero antes de la retropropagación. Luego, para actualizar los parámetros, se llama aOptimizer.step().
optimizador = torch.optim.Adam(modelo.parámetros(), lr=0.01) #definiendo el optimizador
optimizer.zero_grad() #establecer gradientes a cero
Optimizer.step() #actualización de parámetros
# 3. Módulo nn: Este paquete ayuda en la construcción de redes neuronales. Se utiliza para construir capas.
Para crear un modelo con una sola capa, simplemente podemos definirlo usando nn.Sequential().
modelo = nn.Sequential( nn.Linear(in, out), nn.Sigmoid(), nn.Linear(_in, _out), nn.Sigmoid() )
Para la implementación del modelo que no está en una sola secuencia, definimos un modelo subclasificando la clase nn.Module.
Python3
class Model (nn.Module) : def __init__(self): super(Model, self).__init__() self.linear = torch.nn.Linear(1, 1) def forward(self, x): y_pred = self.linear(x) return y_pred
Conjunto de datos y cargador de datos de PyTorch
La clase torch.utils.data.Dataset contiene todos los conjuntos de datos personalizados. Necesitamos implementar dos métodos, __len__() y __get_item__(), para crear nuestra propia clase de conjunto de datos.
PyTorch Dataloader tiene una característica sorprendente de cargar el conjunto de datos en paralelo con el procesamiento por lotes automático. Por lo tanto, reduce el tiempo de carga secuencial del conjunto de datos y, por lo tanto, mejora la velocidad.
Sintaxis: DataLoader(conjunto de datos, aleatorio=Verdadero, muestreador=Ninguno, muestreador_lote=Ninguno, tamaño_lote=32)
PyTorch DataLoader admite dos tipos de conjuntos de datos:
- Conjuntos de datos de estilo de mapa: los elementos de datos se asignan a los índices. En estos conjuntos de datos, el método __get_item__() se usa para recuperar el índice de cada elemento.
- Conjuntos de datos de estilo iterable: en estos conjuntos de datos se implementa el protocolo __iter__(). Las muestras de datos se recuperan en secuencia.
Consulte el artículo sobre el uso de un cargador de datos en PyTorch para obtener más información.
Construcción de redes neuronales con PyTorch
Veremos esto en una implementación paso a paso:
- Preparación del conjunto de datos: como todo en PyTorch se representa en forma de tensores, primero deberíamos hacerlo en tensores.
- Modelo de construcción: Para construir una red neutral, primero definimos el número de capas de entrada, capas ocultas y capas de salida. También necesitamos definir los pesos iniciales. Los valores de las arrays de pesos se eligen aleatoriamente usando torch.randn() . Torch.randn() devuelve un tensor que consta de números aleatorios de una distribución normal estándar.
- Propagación hacia adelante: los datos se alimentan a una red neuronal y se realiza una multiplicación de array entre los pesos y la entrada. Esto se puede hacer fácilmente usando una antorcha.
- Cálculo de pérdida: las funciones PyTorch.nn tienen múltiples funciones de pérdida. Las funciones de pérdida se utilizan para medir el error entre el valor predicho y el valor objetivo.
- Backpropagation: Se utiliza para optimizar pesos. Los pesos se cambian de manera que se minimice la pérdida.
Ahora construyamos una red neuronal desde cero:
Python3
# importing torch import torch # training input(X) and output(y) X = torch.Tensor([[1], [2], [3], [4], [5], [6]]) y = torch.Tensor([[5], [10], [15], [20], [25], [30]]) class Model(torch.nn.Module): # defining layer def __init__(self): super(Model, self).__init__() self.linear = torch.nn.Linear(1, 1) # implementing forward pass def forward(self, x): y_pred = self.linear(x) return y_pred model = torch.nn.Linear(1 , 1) # defining loss function and optimizer loss_fn = torch.nn.L1Loss() optimizer = torch.optim.Adam(model.parameters(), lr = 0.01 ) for epoch in range(1000): # predicting y using initial weights y_pred = model(X.requires_grad_()) # loss calculation loss = loss_fn(y_pred, y) # calculating gradients loss.backward() # updating weights optimizer.step() optimizer.zero_grad() # testing on new data X = torch.Tensor([[7], [8]]) predicted = model(X) print(predicted)
Producción: