Trabajar en Big Data se ha vuelto muy común hoy en día, por lo que necesitamos algunas bibliotecas que puedan facilitarnos trabajar en big data desde nuestros sistemas (es decir, computadoras de escritorio, portátiles) con ejecución instantánea de Código y bajo uso de memoria.
Vaex es una biblioteca de Python que nos ayuda a lograrlo y hace que trabajar con grandes conjuntos de datos sea muy fácil. Es especialmente para marcos de datos perezosos fuera del núcleo (similar a Pandas). Puede visualizar, explorar y realizar cálculos en grandes conjuntos de datos tabulares rápidamente y con un uso mínimo de memoria.
Instalación:
Usando Conda:
conda install -c conda-forge vaex
Usando pipa:
pip install --upgrade vaex
¿Por qué Vaex?
Vaex nos ayuda a trabajar con grandes conjuntos de datos de manera eficiente y rápida mediante cálculos perezosos, columnas virtuales, mapeo de memoria, política de copia de memoria cero, limpieza de datos eficiente, etc. Vaex tiene algoritmos eficientes y enfatiza las propiedades de datos agregados en lugar de mirar muestras individuales. Es capaz de superar varias deficiencias de otras bibliotecas (como: – pandas). Entonces, exploremos Vaex: –
Para grandes datos tabulares, el rendimiento de lectura de Vaex es mucho más rápido que el de pandas. Analicemos importando un conjunto de datos del mismo tamaño con ambas bibliotecas. Enlace al conjunto de datos
Rendimiento de lectura de pandas :
Python3
import pandas as pd
%time df_pandas = pd.read_csv("dataset1.csv")
Producción:
Wall time: 1min 8s
Rendimiento de lectura de Vaex : (leemos el conjunto de datos en Vaex usando vaex.open)
Python3
import vaex
%time df_vaex = vaex.open("dataset1.csv.hdf5")
Producción:
Wall time: 1.34 s
Vaex tardó muy poco tiempo en leer el conjunto de datos del mismo tamaño en comparación con los pandas:
Python3
print("Size =")
print(df_pandas.shape)
print(df_vaex.shape)
Producción:
Size = 12852000, 36 12852000, 36
Vaex hace cálculos perezosamente
Vaex utiliza una técnica de cálculo perezoso (es decir, calcula sobre la marcha sin desperdiciar RAM). En esta técnica, Vaex no realiza los cálculos completos, sino que crea una expresión Vaex y, cuando se imprime, muestra algunos valores de vista previa. Entonces, Vaex realiza cálculos solo cuando es necesario, de lo contrario, almacena la expresión. Esto hace que la velocidad de cálculo de Vaex sea excepcionalmente rápida. Realicemos un ejemplo en un cálculo simple:
Marco de datos de pandas :
Python3
%time df_pandas['column2'] + df_pandas['column3']
Producción:
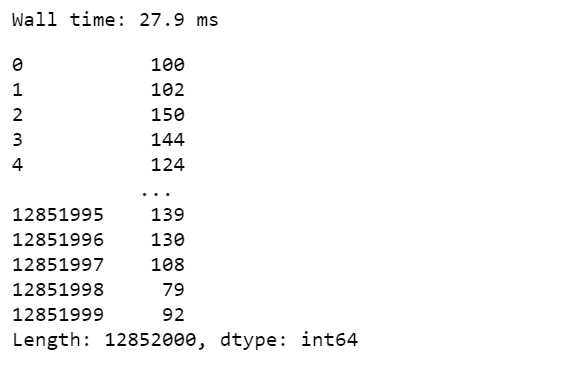
Marco de datos Vaex :
Python3
%time df_vaex.column2 + df_vaex.column3
Producción:
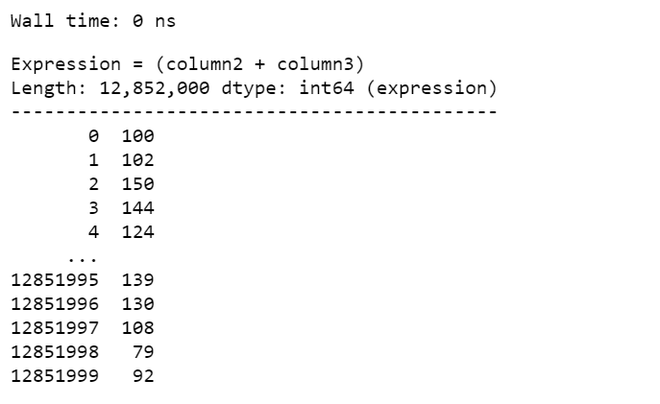
Rendimiento de las estadísticas:
Vaex puede calcular estadísticas como la media, la suma, el conteo, la desviación estándar, etc., en una cuadrícula de N dimensiones de hasta mil millones (10 9 ) de objetos/filas por segundo. Entonces, comparemos el rendimiento de pandas y Vaex mientras calculamos estadísticas: –
Marco de datos de pandas :
Python3
%time df_pandas["column3"].mean()
Producción:
Wall time: 741 ms 49.49811570183629
Marco de datos Vaex:
Python3
%time df_vaex.mean(df_vaex.column3)
Producción:
Wall time: 347 ms array(49.4981157)
Vaex sigue la política de copia de memoria cero
A diferencia de Pandas, no se crean copias de la memoria en Vaex durante el filtrado de datos, selecciones, subconjuntos, limpieza. Tomemos el caso del filtrado de datos, para lograr esta tarea, Vaex usa muy poca memoria ya que no se realiza ninguna copia de memoria en Vaex. y el tiempo de ejecución también es mínimo.
pandas :
Python3
%time df_pandas_filtered = df_pandas[df_pandas['column5'] > 1]
Producción:
Wall time: 24.1 s
Vaex :
Python3
%time df_vaex_filtered = df_vaex[df_vaex['column5'] > 1]
Producción:
Wall time: 91.4 ms
Aquí, el filtrado de datos da como resultado una referencia a los datos existentes con una máscara booleana que realiza un seguimiento de las filas seleccionadas y las filas no seleccionadas. Vaex realiza múltiples cálculos en un solo paso sobre los datos:-
Python3
df_vaex.select(df_vaex.column4 < 20, name='less_than') df_vaex.select(df_vaex.column4 >= 20, name='gr_than') %time df_vaex.mean(df_vaex.column4, selection=['less_than', 'gr_than'])
Producción:
Wall time: 128 ms array([ 9.4940431, 59.49137605])
Columnas virtuales en Vaex
Cuando creamos una nueva columna agregando una expresión a un DataFrame, se crean columnas virtuales. Estas columnas son como columnas normales, pero no ocupan memoria y solo almacenan la expresión que las define. Esto hace que la tarea sea muy rápida y reduce el desperdicio de RAM. Y Vaex no hace distinción entre columnas regulares o virtuales.
Python3
%time df_vaex['new_col'] = df_vaex['column3']**2 df_vaex.mean(df_vaex['new_col'])
Producción:
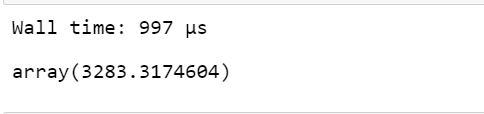
Estadísticas agrupadas en Vaex:
Vaex proporciona una alternativa más rápida al grupo de pandas como ‘binby’ que puede calcular estadísticas en una cuadrícula N-dimensional regular rápidamente en contenedores regulares.
Python3
%time df_vaex.count(binby=df_vaex.column7, limits=[0, 20], shape=10)
Producción:

La visualización de un gran conjunto de datos es una tarea tediosa. Pero Vaex puede calcular estas visualizaciones con bastante rapidez. El conjunto de datos da una mejor idea de la distribución de datos cuando se calcula en contenedores y Vaex sobresale en propiedades, selecciones y contenedores de agregados de grupo. Por lo tanto, Vaex puede visualizar de forma rápida e interactiva. Con Vaex, las visualizaciones se pueden realizar incluso en 3 dimensiones en grandes conjuntos de datos.
Tracemos un gráfico unidimensional simple:
Python3
%time df_vaex.viz.histogram(df_vaex.column1, limits = [0, 20])
Producción:
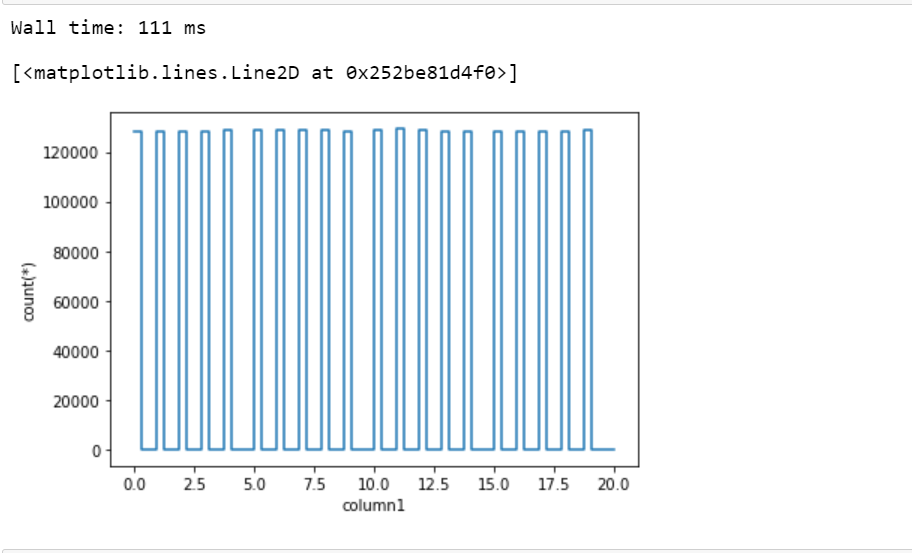
Tracemos un mapa de calor bidimensional:
Python
df_vaex.viz.heatmap(df_vaex.column7, df_vaex.column8 + df_vaex.column9, limits=[-3, 20])
Producción:
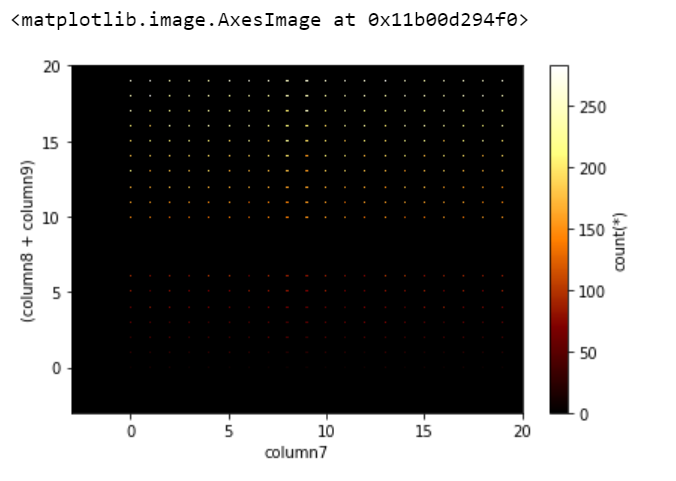
Podemos agregar una expresión estadística y visualizar pasando el argumento “qué=<estadística>(<expresión>)”. Así que vamos a realizar una visualización un poco complicada:
Python3
df_vaex.viz.heatmap(df_vaex.column1, df_vaex.column2, what=(vaex.stat.mean(df_vaex.column4) / vaex.stat.std(df_vaex.column4)), limits='99.7%')
Producción:
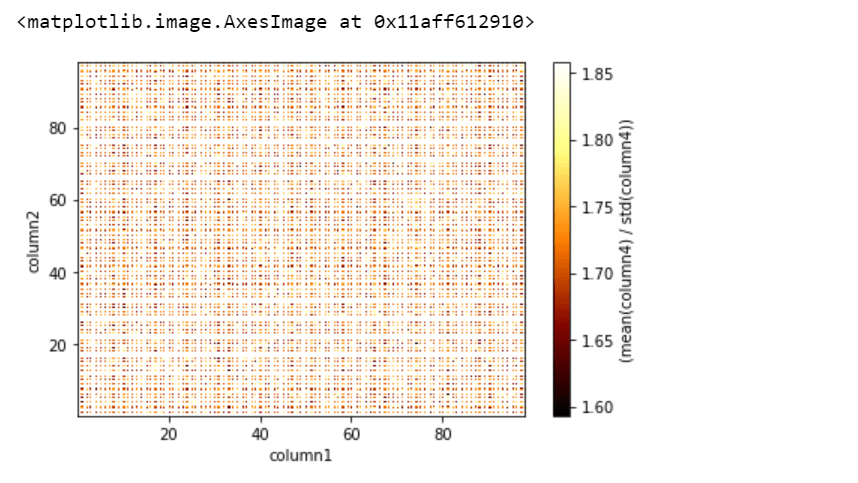
Aquí, los objetos ‘vaex.stat.<statistic>’ son muy similares a las expresiones Vaex, que representan un cálculo subyacente, y también podemos aplicar funciones aritméticas y Numpy típicas a estos cálculos.