El análisis léxico es la primera fase del compilador, también conocido como escáner. Convierte el programa de entrada de alto nivel en una secuencia de tokens .
- El análisis léxico se puede implementar con los autómatas finitos deterministas .
- El resultado es una secuencia de tokens que se envía al analizador para el análisis de sintaxis.
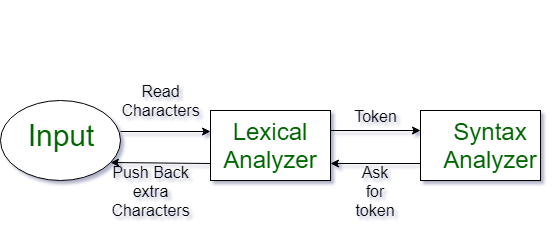
¿Qué es una ficha?
Un token léxico es una secuencia de caracteres que puede tratarse como una unidad en la gramática de los lenguajes de programación.
Ejemplo de fichas:
- Tipo token (id, número, real, . . . )
- Fichas de puntuación (IF, void, return, . . . )
- Tokens alfabéticos (palabras clave)
Keywords; Examples-for, while, if etc. Identifier; Examples-Variable name, function name, etc. Operators; Examples '+', '++', '-' etc. Separators; Examples ',' ';' etc
Ejemplo de no tokens:
- Comentarios, directiva de preprocesador, macros, espacios en blanco, tabuladores, nueva línea, etc.
Lexema : la secuencia de caracteres emparejados por un patrón para formar
el token correspondiente o una secuencia de caracteres de entrada que comprende un solo token se denomina lexema. por ejemplo, «flotante», «abs_cero_Kelvin», «=», «-«, «273», «;» .
Cómo funciona Lexical Analyzer
1. Tokenización, es decir, dividir el programa en tokens válidos.
2. Elimina los espacios en blanco.
3. Eliminar comentarios.
4. También proporciona ayuda para generar mensajes de error proporcionando números de fila y números de columna.
{kind=link}
Supongamos que pasamos una declaración a través del analizador léxico:
a = b + c ; Generará una secuencia de tokens como esta:
id=id+id ; Donde cada id se refiere a su variable en la tabla de símbolos que hace referencia a todos los detalles
Por ejemplo, considere el programa
int main()
{
// 2 variables
int a, b;
a = 10;
return 0;
}
Todos los tokens válidos son:
'int' 'main' '(' ')' '{' 'int' 'a' ',' 'b' ';'
'a' '=' '10' ';' 'return' '0' ';' '}'
Arriba están los tokens válidos.
Puede observar que hemos omitido los comentarios.
Como otro ejemplo, considere la siguiente instrucción printf. Hay 5 tokens válidos en esta instrucción printf. Ejercicio 1: Contar el número de fichas:
int main()
{
int a = 10, b = 20;
printf("sum is :%d",a+b);
return 0;
}
Answer: Total number of token: 27.
Ejercicio 2:
Cuente el número de fichas:
int max(int i);
- El analizador léxico primero lee int y encuentra que es válido y lo acepta como token
- max es leído por él y se encuentra que es un nombre de función válido después de leer (
- int también es un token, luego otra vez i como otro token y finalmente ;
Answer: Total number of tokens 7: int, max, ( ,int, i, ), ;
A continuación se encuentran las preguntas de GATE del año anterior sobre el análisis léxico.
https://www.geeksforgeeks.org/lexical-analysis-gq/
Escriba comentarios si encuentra algo incorrecto o si desea compartir más información sobre el tema tratado anteriormente
Publicación traducida automáticamente
Artículo escrito por GeeksforGeeks-1 y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA