Distribución simplemente significa recopilación o recopilación de datos, o puntajes, en la variable. En general, todas estas puntuaciones se organizan en un orden específico de menor a mayor. Luego, estos puntajes se pueden presentar gráficamente. Muchos datos cumplen con las reglas de funciones matemáticas conocidas y muy entendidas.
Una función generalmente puede ajustar datos con algunas modificaciones y cambios en los parámetros de las funciones. Tan pronto como se conozca e identifique la función de distribución, se puede usar como abreviatura para describir y calcular cantidades relacionadas. Estas cantidades pueden ser la probabilidad de las observaciones y trazar la relación entre las observaciones en el dominio.
Las distribuciones se describen generalmente en términos de su densidad o funciones de densidad. Las funciones de densidad se describen simplemente como funciones que explican cómo cambia la proporción de datos o la probabilidad de la proporción de observaciones en un amplio rango de distribución. Las funciones de densidad son de dos tipos:
- Función de densidad de probabilidad (PDF) –
Calcula la probabilidad de observar un valor dado. - Función de densidad acumulativa (CDF) –
Calcula la probabilidad de una observación igual o menor que el valor.
Tanto los PDF como los CDF son tipos de funciones continuas. Para la distribución discreta, el equivalente de PDF se llama función de masa de probabilidad (PMF).
Tipos de distribuciones de datos estadísticos:
- Distribución gaussiana :
lleva el nombre de Carl Friedrich Gauss. La distribución gaussiana es el foco de gran parte del campo de las estadísticas. También se conoce como Distribución Normal . Con el uso de la distribución gaussiana, se pueden describir los datos de diferentes campos de estudio. En general, la distribución gaussiana se describe utilizando dos parámetros:- Media:
Se denota con la letra minúscula griega “mu”. Es el valor esperado de la distribución. - Varianza:
Se denota con la letra griega minúscula “sigma” elevada a la segunda potencia (esto se debe a que las unidades de las variables están elevadas al cuadrado). Generalmente describe la dispersión de la observación desde la media.Es un cálculo de varianza normalizado muy común y fácil de usar llamado Desviación Estándar. La desviación estándar se denota con la letra minúscula griega «sigma». Generalmente describe la dispersión normalizada de las observaciones a partir de la media.
Ejemplo:
el ejemplo que se proporciona a continuación crea una PDF gaussiana con un espacio de muestra de -5 a 5, una media de 0 y una desviación estándar de 1. Este tipo de gaussiana con estos valores de media y desviación estándar se denomina gaussiana estándar .Código de Python para el gráfico de líneas de la función de densidad de probabilidad gaussiana:
# plot the gaussian pdf from numpy import arrange from matplotlib import pyplot from scipy.stats import norm # define the distribution parameters sample_space= arange (-5, 5, 0.001) mean= 0.0 stdev= 1.0 # calculate the pdf pdf= norm.pdf (sample_space, mean, stdev) # plot pyplot.plot (sample_space, pdf) pyplot.show()
Cuando ejecutamos el ejemplo anterior, crea una gráfica rayada que muestra el espacio de muestra en el eje x y la probabilidad de cada valor del eje Y. El diagrama de líneas generalmente muestra y representa una forma de campana familiar para la distribución gaussiana.
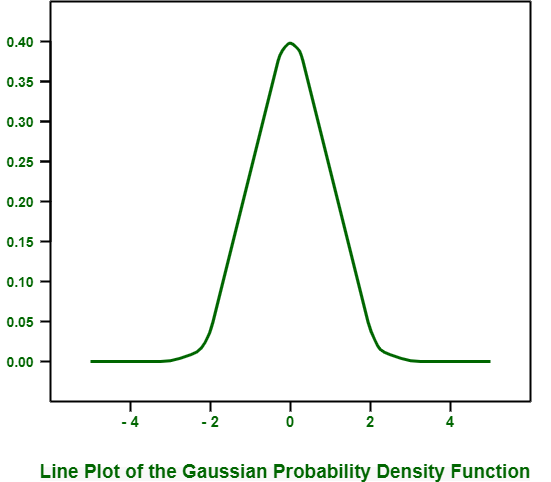
En este gráfico, la parte superior de la campana muestra el valor esperado o la media, que en este caso es cero, como ya lo especificamos al crear la distribución.
- Media:
- T- Distribución :
lleva el nombre de Willian Sealy Gosset. La distribución T generalmente surge cuando intentamos encontrar la media de la distribución normal con muestras de diferentes tamaños. Es muy útil cuando se describe la incertidumbre o el error relacionado con la estimación o la búsqueda de estadísticas de población para datos extraídos de distribuciones gaussianas cuando se debe considerar el tamaño de la muestra. La distribución T se puede describir usando un solo parámetro.Número de Grados de Libertad:
Se denota con la letra minúscula griega “nu (v)”. Simplemente denota el número de grados de libertad. El número de grados de libertad generalmente explica el número de piezas de información que se utilizan para describir la cantidad de población.Ejemplo:
el ejemplo que se proporciona a continuación crea una distribución t con un espacio de muestra de -5 a 5 y (10, 000-1) grados de libertad.Código de Python para el gráfico de líneas de la función de densidad de probabilidad de distribución t de Student:
# plot the t-distribution pdf from numpy import arange from matplotlib import pyplot from scipy.stats import t # define the distribution parameters sample_space= arange (-5, 5, 0.001) dof= len(sample_space) - 1 # calculate the pdf pdf= t.pdf (sample_space, dof) # plot pyplot.plot (sample_space, pdf) pyplot.show()
Cuando ejecutamos el ejemplo anterior, crea y traza un PDF de distribución t.
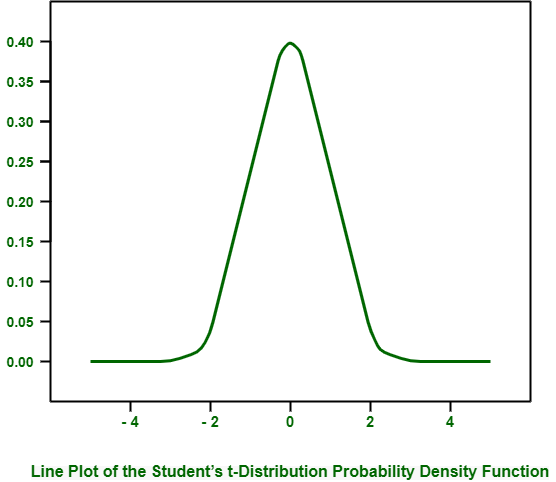
Puede ver una forma de campana similar a la distribución muy parecida a la normal. La principal diferencia son las colas más gruesas en la distribución, lo que destaca una mayor probabilidad de observaciones en las colas en comparación con la distribución gaussiana.
Publicación traducida automáticamente
Artículo escrito por madhurihammad y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA