Introducción: este proyecto se basa en el aprendizaje por refuerzo, que entrena a la serpiente para que coma los alimentos presentes en el entorno.
A continuación se muestra un gif de muestra para que pueda tener una idea de lo que vamos a construir.

Serpiente impulsada por IA
Los requisitos previos para este proyecto son:
- Aprendizaje reforzado
- Aprendizaje profundo (red neuronal densa)
- Pygame
Para comprender cómo podemos construir manualmente esta simulación de animación 2D de serpiente usando pygame, siga el enlace: https://www.geeksforgeeks.org/snake-game-in-python-using-pygame-module/
Después de construir el juego básico de serpientes, ahora nos centraremos en cómo aplicarle el aprendizaje por refuerzo.
Tenemos que crear tres Módulos para este proyecto:
- El entorno (el juego que construimos)
- El modelo (modelo de refuerzo para la predicción de movimientos)
- El Agente (Intermediario entre Entorno y Modelo)
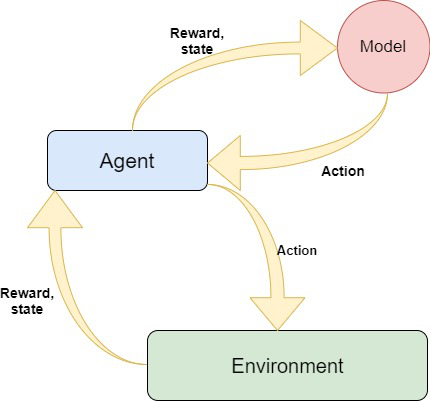
Vinculación de Módulos
Algoritmo:
Tenemos serpiente y comida en el tablero colocadas al azar.
- Calcule el estado de la serpiente utilizando los 11 valores y, si alguna de las condiciones es verdadera, establezca ese valor en cero; de lo contrario, establezca uno.
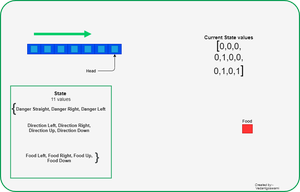
Cómo se definen 11 estados
En función de la posición actual del Jefe, el agente calculará los 11 valores de estado como se describe anteriormente.
- Después de obtener estos estados, el agente pasaría esto al modelo y obtendría el siguiente movimiento para realizar.
- Después de ejecutar el siguiente estado, calcule la recompensa. Las recompensas se definen de la siguiente manera:
- Comer comida: +10
- Juego terminado: -10
- Más: 0
- Actualice el valor Q (que se discutirá más adelante) y entrene el modelo.
- Después de analizar el algoritmo ahora tenemos que construir la idea para proceder con la codificación de este algoritmo.
El modelo:
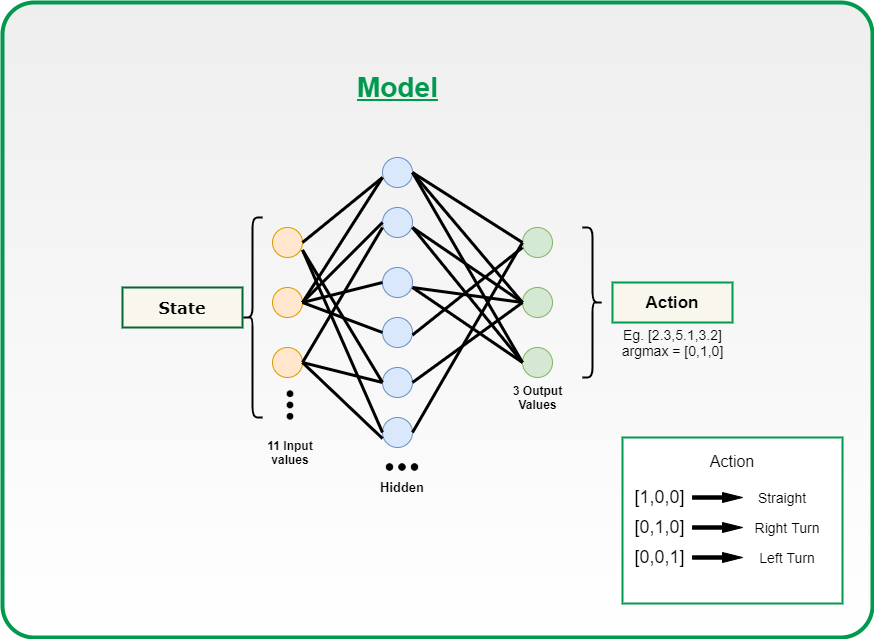
Modelo de red neuronal
El modelo está diseñado con Pytorch, pero también puede usar TensorFlow según su comodidad.
Estamos utilizando una red neuronal densa con una capa de entrada de tamaño 11 y una capa densa con 256 neuronas y una salida de 3 neuronas. Puede modificar estos hiperparámetros para obtener el mejor resultado.
¿Cómo funcionan los modelos?
- El juego comienza y el valor Q se inicializa aleatoriamente.
- El sistema obtiene el estado actual s.
- En función de s, ejecuta una acción, de forma aleatoria o en función de su red neuronal. Durante la primera fase del entrenamiento, el sistema a menudo elige acciones aleatorias para maximizar la exploración. Más tarde, el sistema depende cada vez más de su red neuronal.
- Cuando la IA elige y realiza la acción, el entorno otorga una recompensa. Luego, el agente alcanza el nuevo estado y actualiza su valor Q de acuerdo con la ecuación de Bellman. Esta ecuación la habías cubierto definitivamente en el curso de aprendizaje por refuerzo. Si no, puede consultar Q-learning Mathematics .
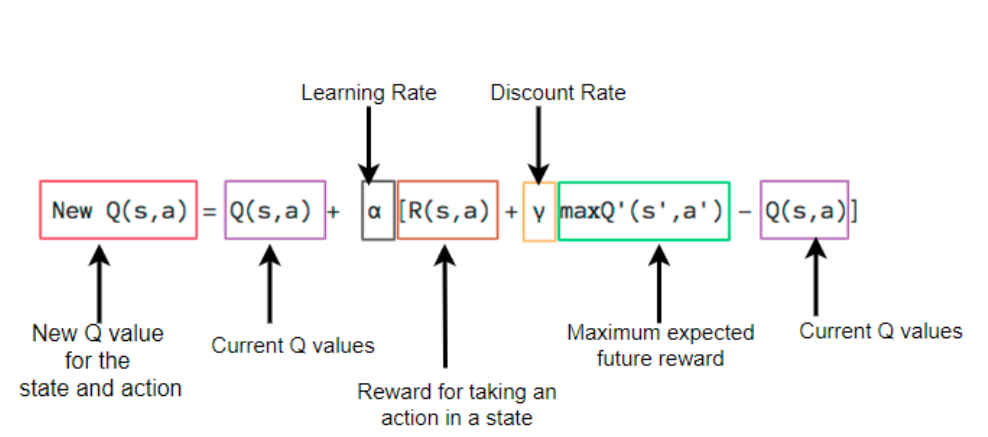
Ecuación de Bellman
- Además, para cada movimiento, almacena el estado original, la acción, el estado alcanzado después de realizar esa acción, la recompensa obtenida y si el juego terminó o no. Estos datos se muestrean posteriormente para entrenar la red neuronal. Esta operación se llama memoria de repetición.
- Estas dos últimas operaciones se repiten hasta que se cumple una determinada condición (ejemplo: finaliza el juego).
El corazón de este proyecto es el modelo que vas a entrenar, porque la precisión del movimiento que haría la serpiente dependerá de la calidad del modelo que hayas construido. Así que me gustaría explicar esto usando el código en partes.
Parte-I
1. Creating a class named Linear_Qnet for initializing the linear neural network. 2. The function forward is used to take the input(11 state vector) and pass it through the Neural network and apply relu activation function and give the output back i.e the next move of 1 x 3 vector size. In short, this is the prediction function that would be called by the agent. 3. The save function is used to save the trained model for future use.
Python3
class Linear_QNet(nn.Module): def __init__(self, input_size, hidden_size, output_size): super().__init__() self.linear1 = nn.Linear(input_size, hidden_size) self.linear2 = nn.Linear(hidden_size, output_size) def forward(self, x): x = F.relu(self.linear1(x)) x = self.linear2(x) return x def save(self, file_name='model_name.pth'): model_folder_path = 'Path' file_name = os.path.join(model_folder_path, file_name) torch.save(self.state_dict(), file_name)
Parte II
1. Initialising QTrainer class
∗ setting the learning rate for the optimizer.
* Gamma value that is the discount rate used in Bellman equation.
* initialising the Adam optimizer for updation of weight and biases.
* criterion is the Mean squared loss function.
2. Train_step function
* As you know that PyTorch work only on tensors, so we are converting all the input
to tensors.
* As discussed above we had a short memory training then we would only pass one value
of state, action, reward, move so we need to convert them into a vector, so we had used
unsqueezed function .
* Get the state from the model and calculate the new Q value using the below formula:
Q_new = reward + gamma * max(next_predicted Qvalue)
* calculate the mean squared error between the new Q value and previous Q value and
backpropagate that loss for weight updation.
Python3
class QTrainer: def __init__(self,model,lr,gamma): #Learning Rate for Optimizer self.lr = lr #Discount Rate self.gamma = gamma #Linear NN defined above. self.model = model #optimizer for weight and biases updation self.optimer = optim.Adam(model.parameters(),lr = self.lr) #Mean Squared error loss function self.criterion = nn.MSELoss() def train_step(self,state,action,reward,next_state,done): state = torch.tensor(state,dtype=torch.float) next_state = torch.tensor(next_state,dtype=torch.float) action = torch.tensor(action,dtype=torch.long) reward = torch.tensor(reward,dtype=torch.float) # if only one parameter to train , then convert to tuple of shape (1, x) if(len(state.shape) == 1): #(1, x) state = torch.unsqueeze(state,0) next_state = torch.unsqueeze(next_state,0) action = torch.unsqueeze(action,0) reward = torch.unsqueeze(reward,0) done = (done, ) # 1. Predicted Q value with current state pred = self.model(state) target = pred.clone() for idx in range(len(done)): Q_new = reward[idx] if not done[idx]: Q_new = reward[idx] + self.gamma * torch.max(self.model(next_state[idx])) target[idx][torch.argmax(action).item()] = Q_new # 2. Q_new = reward + gamma * max(next_predicted Qvalue) #pred.clone() #preds[argmax(action)] = Q_new self.optimer.zero_grad() loss = self.criterion(target,pred) loss.backward() # backward propagation of loss self.optimer.step()
El agente
- Obtenga el estado actual de la serpiente del entorno.
Python3
def get_state(self, game): head = game.snake[0] point_l = Point(head.x - BLOCK_SIZE, head.y) point_r = Point(head.x + BLOCK_SIZE, head.y) point_u = Point(head.x, head.y - BLOCK_SIZE) point_d = Point(head.x, head.y + BLOCK_SIZE) dir_l = game.direction == Direction.LEFT dir_r = game.direction == Direction.RIGHT dir_u = game.direction == Direction.UP dir_d = game.direction == Direction.DOWN state = [ # Danger Straight (dir_u and game.is_collision(point_u))or (dir_d and game.is_collision(point_d))or (dir_l and game.is_collision(point_l))or (dir_r and game.is_collision(point_r)), # Danger right (dir_u and game.is_collision(point_r))or (dir_d and game.is_collision(point_l))or (dir_u and game.is_collision(point_u))or (dir_d and game.is_collision(point_d)), # Danger Left (dir_u and game.is_collision(point_r))or (dir_d and game.is_collision(point_l))or (dir_r and game.is_collision(point_u))or (dir_l and game.is_collision(point_d)), # Move Direction dir_l, dir_r, dir_u, dir_d, # Food Location game.food.x < game.head.x, # food is in left game.food.x > game.head.x, # food is in right game.food.y < game.head.y, # food is up game.food.y > game.head.y # food is down ] return np.array(state, dtype=int)
- Modelo de llamada para obtener el siguiente estado de la serpiente.
Python3
def get_action(self, state): # random moves: tradeoff explotation / exploitation self.epsilon = 80 - self.n_game final_move = [0, 0, 0] if(random.randint(0, 200) < self.epsilon): move = random.randint(0, 2) final_move[move] = 1 else: state0 = torch.tensor(state, dtype=torch.float).cuda() prediction = self.model(state0).cuda() # prediction by model move = torch.argmax(prediction).item() final_move[move] = 1 return final_move
Nota: Existe un compromiso entre explotación y exploración. Donde la explotación consiste en tomar la decisión que se supone óptima para los datos observados hasta el momento. Y la exploración es tomar decisiones al azar sin considerar las acciones anteriores y el par de recompensas. Entonces, ambos son necesarios porque tomar la explotación puede hacer que el agente no explore todo el entorno y la exploración no siempre puede proporcionar una mejor recompensa.
- Juega el paso predicho por el modelo en el entorno.
- Guarda el estado actual, el movimiento realizado y la recompensa.
- Entrena al modelo en función del movimiento realizado y la recompensa obtenida por el Entorno. (Entrenamiento de memoria corta)
Python3
def train_short_memory(self, state, action, reward, next_state, done): self.trainer.train_step(state, action, reward, next_state, done)
- Si el juego termina debido a que golpea una pared o un cuerpo, entrene al modelo en función de todos los movimientos realizados hasta ahora y reinicie el entorno. (Entrenamiento Memoria larga). Entrenamiento en un tamaño de lote de 1000.
Python3
def train_long_memory(self): if (len(self.memory) > BATCH_SIZE): mini_sample = random.sample(self.memory, BATCH_SIZE) else: mini_sample = self.memory states, actions, rewards, next_states, dones = zip(*mini_sample) self.trainer.train_step(states, actions, rewards, next_states, dones)
Entrenar el modelo llevaría un tiempo aproximado de 100 épocas para un mejor rendimiento. Ver el progreso de mi entrenamiento.
Producción:
- Para ejecutar este juego, primero cree un entorno en el indicador de anaconda o (cualquier plataforma). Luego instale los módulos necesarios, como Pytorch (para el modelo de aprendizaje DQ), Pygame (para las imágenes del juego) y otros módulos básicos.
- Luego ejecute el archivo agent.py en el entorno recién creado y luego comenzará el entrenamiento, y verá las siguientes dos GUI, una para el progreso del entrenamiento y la otra para el juego de serpientes impulsado por IA.
- Después de lograr cierta puntuación, puedes salir del juego y el modelo que acabas de entrenar se almacenará en la ruta que hayas definido en la función de guardado de models.py.
En el futuro, puede usar este modelo entrenado simplemente cambiando el código en el archivo agent.py como se muestra a continuación:
Python3
self.model.load_state_dict(torch.load('PATH'))
Nota: Comenta todas las llamadas a la función de entrenamiento.
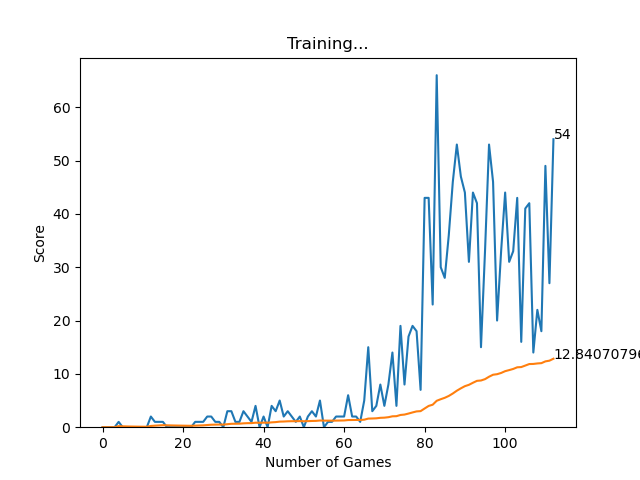
Progreso de entrenamiento

Entrenamiento inicial
Después de 100 épocas
Código fuente: https://github.com/vedantgoswami/SnakeGameAI
Solicitud:
El objetivo de este proyecto es dar una idea de cómo se puede aplicar el aprendizaje por refuerzo y cómo se puede usar en aplicaciones del mundo real, como automóviles autónomos (p. ej., AWS DeepRacer), robots de entrenamiento en la línea de ensamblaje y muchos más. más…
Puntas:
- Utilice un entorno independiente e instale todos los módulos necesarios. (Puedes usar el entorno anaconda)
- Para entrenar el modelo, puede usar GPU para un entrenamiento más rápido.
Publicación traducida automáticamente
Artículo escrito por vedantgoswami6227 y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA