La minería de datos es un proceso de extracción de información útil de almacenes de datos o de datos masivos. Este artículo contiene las preguntas de entrevista más populares y más frecuentes sobre minería de datos junto con sus respuestas detalladas. Esto lo ayudará a descifrar cualquier entrevista para un trabajo de científico de datos. Entonces empecemos.

1. ¿Qué es la minería de datos?
La minería de datos se refiere a extraer o extraer conocimiento de grandes cantidades de datos. En otras palabras, la minería de datos es la ciencia, el arte y la tecnología de descubrir cuerpos de datos grandes y complejos para descubrir patrones útiles.
2. ¿Cuáles son las diferentes tareas de la minería de datos?
Durante la minería de datos se llevan a cabo las siguientes actividades:
- Clasificación
- Agrupación
- Descubrimiento de reglas de asociación
- Descubrimiento de patrones secuenciales
- Regresión
- Detección de desviación
3. ¿Discutir el ciclo de vida de los proyectos de minería de datos?
El ciclo de vida de los proyectos de minería de datos:
- Entendimiento de negocios: Entender los objetivos de los proyectos desde una perspectiva de negocios, definición de problemas de minería de datos.
- Comprensión de datos: recopilación inicial de datos y comprensión.
- Preparación de datos: construcción del conjunto de datos final a partir de datos sin procesar.
- Modelado: Seleccionar y aplicar técnicas de modelado de datos.
- Evaluación: evaluar el modelo, decidir sobre una mayor implementación.
- Implementación : cree un informe, realice acciones basadas en nuevos conocimientos.
4. Explique el proceso de KDD?
La minería de datos se trata como un sinónimo de otro término popular, Knowledge Discovery from Data o KDD. En otros, la minería de datos se ve simplemente como un paso esencial en el proceso de descubrimiento de conocimiento, en el que se aplican métodos inteligentes para extraer patrones de datos.
El descubrimiento de conocimiento a partir de datos consta de los siguientes pasos:
- Limpieza de datos (para eliminar ruido o datos irrelevantes).
- Integración de datos (donde se pueden combinar múltiples fuentes de datos).
- Selección de datos (donde los datos relevantes para la tarea de análisis se recuperan de la base de datos).
- Transformación de datos (donde los datos se transmutan o consolidan en formas apropiadas para la minería mediante la realización de funciones de resumen o agregación, para muestra).
- Minería de datos (un proceso importante donde se aplican métodos inteligentes para extraer patrones de datos).
- Evaluación de patrones (para identificar los patrones fascinantes que representan el conocimiento en función de algunas medidas de interés).
- Presentación del conocimiento (donde se utilizan técnicas de representación y visualización del conocimiento para presentar el conocimiento extraído al usuario).
5. ¿Qué es la Clasificación?
La clasificación es el procesamiento de encontrar un conjunto de modelos (o funciones) que describen y distinguen clases de datos o conceptos, con el fin de poder utilizar el modelo para predecir la clase de objetos cuya etiqueta de clase se desconoce. La clasificación se puede utilizar para predecir la etiqueta de clase de los elementos de datos. Sin embargo, en muchas aplicaciones, es posible que desee calcular algunos valores de datos faltantes o no disponibles en lugar de etiquetas de clase.
6. Explique ¿Evolución y análisis de desviación?
El análisis de evolución de datos describe y modela regularidades o tendencias para objetos cuyo comportamiento varía con el tiempo. Aunque esto puede implicar discriminación, asociación, clasificación, caracterización o agrupación de datos relacionados con el tiempo, las características distintivas de dicho análisis implican el análisis de datos de series temporales, la coincidencia de patrones de periodicidad y el análisis de datos basados en la similitud.
En el análisis de datos relacionados con el tiempo, a menudo se requiere no solo modelar la tendencia evolutiva general de los datos, sino también identificar las desviaciones de datos que ocurren con el tiempo. Las desviaciones son diferencias entre los valores medidos y las referencias correspondientes, como valores anteriores o valores normativos. Un sistema de minería de datos que realiza un análisis de desviaciones, al detectar un conjunto de desviaciones, puede hacer lo siguiente: describir las características de las desviaciones, tratar de describir la razón detrás de ellas y sugerir acciones para que los valores desviados vuelvan a sus valores esperados. .
7. ¿Qué es la predicción?
La predicción puede verse como la construcción y el uso de un modelo para evaluar la clase de un objeto sin etiquetar, o para medir el valor o los rangos de valores de un atributo que es probable que tenga un objeto dado. En esta interpretación, la clasificación y la regresión son los dos tipos principales de problemas de predicción en los que la clasificación se usa para predecir valores discretos o nominales, mientras que la regresión se usa para predecir valores incesantes u ordenados.
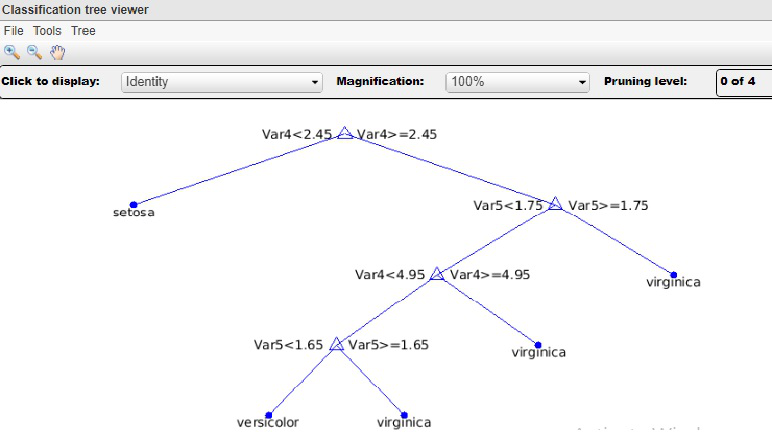
8. ¿Explicar el clasificador del árbol de decisiones?
Un árbol de decisión es una estructura de árbol similar a un diagrama de flujo, donde cada Node interno (Node no hoja) denota una prueba en un atributo, cada rama representa un resultado de la prueba y cada Node hoja (o Node terminal) tiene una etiqueta de clase. . El Node superior de un árbol es el Node raíz.
Un árbol de decisión es un esquema de clasificación que genera un árbol y un conjunto de reglas, que representan el modelo de diferentes clases, a partir de un conjunto de datos dado. El conjunto de registros disponibles para desarrollar métodos de clasificación generalmente se divide en dos subconjuntos separados, a saber, un conjunto de entrenamiento y un conjunto de prueba. El primero se usa para originar el clasificador, mientras que el segundo se usa para medir la precisión del clasificador. La precisión del clasificador está determinada por el porcentaje de ejemplos de prueba que se clasifican correctamente.
En el clasificador de árboles de decisión, categorizamos los atributos de los registros en dos tipos diferentes. Los atributos cuyo dominio es numérico se denominan atributos numéricos y los atributos cuyo dominio no es numérico se denominan atributos categóricos. Hay un atributo distinguido llamado etiqueta de clase. El objetivo de la clasificación es construir un modelo conciso que pueda usarse para predecir la clase de los registros cuya etiqueta de clase se desconoce. Los árboles de decisión se pueden convertir simplemente en reglas de clasificación.
9. ¿Cuáles son las ventajas de un clasificador de árboles de decisión?
- Los árboles de decisión pueden producir reglas comprensibles.
- Son capaces de manejar tanto atributos numéricos como categóricos.
- Son fáciles de entender.
- Una vez que se ha construido un modelo de árbol de decisión, la clasificación de un registro de prueba es extremadamente rápida.
- La representación del árbol de decisión es lo suficientemente rica como para representar cualquier clasificador de valor discreto.
- Los árboles de decisión pueden manejar conjuntos de datos que pueden tener errores.
- Los árboles de decisión pueden manejar conjuntos de datos que pueden tener valores faltantes.
- No requieren supuestos previos. Los árboles de decisión se explican por sí mismos y, cuando se compactan, también son fáciles de seguir. Es decir, si el árbol de decisión tiene un número razonable de hojas, puede ser manipulado por usuarios no profesionales. Además, dado que los árboles de decisión se pueden convertir en un conjunto de reglas, este tipo de representación se considera comprensible.
10. ¿Explicar la clasificación bayesiana en minería de datos?
Un clasificador bayesiano es un clasificador estadístico. Pueden predecir las probabilidades de pertenencia a una clase, por ejemplo, la probabilidad de que una muestra dada pertenezca a una clase en particular. La clasificación bayesiana se crea sobre el teorema de Bayes. Un clasificador bayesiano simple se conoce como el clasificador bayesiano ingenuo por ser comparable en rendimiento con árboles de decisión y clasificadores de redes neuronales. Los clasificadores bayesianos también han mostrado una alta precisión y velocidad cuando se aplican a grandes bases de datos.
11. ¿Por qué la lógica difusa es un área importante para la minería de datos?
Los sistemas de clasificación basados en reglas tienen la desventaja de que involucran valores exactos para atributos continuos. La lógica difusa es útil para los sistemas de minería de datos que realizan la clasificación. Proporciona la ventaja de trabajar a un alto nivel de abstracción. En general, el uso de la lógica difusa en los sistemas basados en reglas implica lo siguiente:
- Los valores de los atributos se cambian a valores borrosos.
- Para una nueva muestra dada, se puede aplicar más de una regla difusa. Cada regla aplicable aporta un voto para la pertenencia a las categorías. Por lo general, se suman los valores de verdad para cada categoría proyectada.
- Las sumas obtenidas anteriormente se combinan en un valor que devuelve el sistema. Este proceso se puede realizar ponderando cada categoría por su suma de verdad y multiplicando por el valor de verdad medio de cada categoría. Los cálculos involucrados pueden ser más complejos, dependiendo de la dificultad de los gráficos de pertenencia difusos.
12. ¿Qué son las redes neuronales?
Una red neuronal es un conjunto de unidades de entrada/salida conectadas donde cada conexión tiene un peso asociado. Durante la fase de conocimiento, la red adquiere ajustando los pesos para poder predecir la etiqueta de clase correcta de las muestras de entrada. El aprendizaje de redes neuronales también se denomina aprendizaje conexionista debido a las conexiones entre unidades. Las redes neuronales implican largos tiempos de entrenamiento y, por lo tanto, son más apropiadas para aplicaciones donde esto es factible. Requieren una serie de parámetros que, por lo general, se determinan mejor empíricamente, como la topología o la «estructura» de la red. Las redes neuronales han sido criticadas por su mala interpretabilidad, ya que es difícil para los humanos captar el significado simbólico detrás de los pesos aprendidos. En primer lugar, estas características hicieron que las redes neuronales fueran menos deseables para la minería de datos.
Sin embargo, las ventajas de las redes neuronales incluyen su alta tolerancia a los datos ruidosos, así como su capacidad para clasificar patrones en los que no han sido entrenadas. Además, recientemente se han desarrollado varios algoritmos para la extracción de reglas de redes neuronales entrenadas. Estos problemas contribuyen a la utilidad de las redes neuronales para la clasificación en la minería de datos. El algoritmo de red neuronal más popular es el algoritmo de retropropagación, propuesto en la década de 1980.
13. ¿Cómo funciona la red de retropropagación?
Una retropropagación aprende mediante el procesamiento iterativo de un conjunto de muestras de entrenamiento, comparando la estimación de la red para cada muestra con la etiqueta de clase conocida real. Para cada muestra de entrenamiento, los pesos se modifican para minimizar el error cuadrático medio entre la predicción de la red y la clase real. Estos cambios se realizan en la dirección «hacia atrás», es decir, desde la capa de salida, a través de cada capa oculta hasta la primera capa oculta (de ahí el nombre de propagación hacia atrás). Aunque no está garantizado, en general, los pesos finalmente convergen y el proceso de conocimiento se detiene.
14. ¿Qué es un Algoritmo Genético?
El algoritmo genético es una parte de la computación evolutiva, que es un área de inteligencia artificial en rápido crecimiento. El algoritmo genético está inspirado en la teoría de Darwin sobre la evolución. Aquí se desarrolla la solución a un problema resuelto por el algoritmo genético. En un algoritmo genético, una población de strings (llamadas cromosomas o el genotipo del gen me), que codifica soluciones candidatas (llamadas individuos, criaturas o fenotipos) para un problema de optimización, evoluciona hacia mejores soluciones. Tradicionalmente, las soluciones se representan en forma de strings binarias, compuestas por 0 y 1, de la misma manera que también se pueden aplicar otros esquemas de codificación.
15. ¿Qué es la precisión de clasificación?
La precisión de la clasificación o la precisión del clasificador está determinada por el porcentaje de ejemplos de conjuntos de datos de prueba que se clasifican correctamente. La precisión de clasificación de un árbol de clasificación = (1 – Error de generalización).
16. ¿Definir agrupamiento en minería de datos?
El agrupamiento es la tarea de dividir la población o los puntos de datos en varios grupos, de modo que los puntos de datos en los mismos grupos sean más similares a otros puntos de datos en el mismo grupo y diferentes a los puntos de datos en otros grupos. Es básicamente una colección de objetos sobre la base de la similitud y la diferencia entre ellos.
17. Escriba una diferencia entre clasificación y agrupamiento? [IMP]
| Parámetros | CLASIFICACIÓN | CLÚSTER |
|---|---|---|
| Escribe | Se utiliza para el aprendizaje de necesidad supervisada | Se utiliza para el aprendizaje no supervisado |
| Básico | Proceso de clasificación de las instancias de entrada en función de sus etiquetas de clase correspondientes | Agrupar las instancias en función de su similitud sin la ayuda de etiquetas de clase |
| Necesitar | Tiene etiquetas, por lo que es necesario un conjunto de datos de entrenamiento y prueba para verificar el modelo creado. | No hay necesidad de un conjunto de datos de entrenamiento y prueba. |
| Complejidad | Más complejo en comparación con la agrupación | Menos complejo en comparación con la clasificación. |
| Algoritmos de ejemplo | Regresión logística, clasificador Naive Bayes, máquinas de vectores de soporte, etc. | Algoritmo de agrupamiento k-means, algoritmo de agrupamiento Fuzzy c-means, algoritmo de agrupamiento gaussiano (EM), etc. |
18. ¿Qué es el aprendizaje supervisado y no supervisado? [Pregunta de la entrevista TCS]
El aprendizaje supervisado, como su nombre lo indica, cuenta con la presencia de un supervisor como docente. Básicamente, el aprendizaje supervisado es cuando enseñamos o entrenamos a la máquina utilizando datos que están bien etiquetados. Lo que significa que algunos datos ya están etiquetados con la respuesta correcta. Después de eso, la máquina recibe un nuevo conjunto de ejemplos (datos) para que el algoritmo de aprendizaje supervisado analice los datos de entrenamiento (conjunto de ejemplos de entrenamiento) y produzca un resultado correcto a partir de los datos etiquetados.
El aprendizaje no supervisado es el entrenamiento de una máquina que utiliza información que no está clasificada ni etiquetada y permite que el algoritmo actúe sobre esa información sin guía. Aquí, la tarea de la máquina es agrupar información no clasificada de acuerdo con similitudes, patrones y diferencias sin ningún entrenamiento previo de datos.
A diferencia del aprendizaje supervisado, no se proporciona ningún maestro, lo que significa que no se dará capacitación a la máquina. Por lo tanto, la máquina está restringida para encontrar la estructura oculta en datos sin etiquetar por sí misma.
19. Nombre las áreas de aplicación de la minería de datos.
- Aplicaciones de minería de datos para finanzas
- Cuidado de la salud
- Inteligencia
- Telecomunicación
- Energía
- Venta minorista
- comercio electrónico
- supermercados
- Agencias del Crimen
- Las empresas se benefician de la minería de datos
20. ¿Cuáles son los problemas en la minería de datos?
Una serie de cuestiones que deben abordarse en cualquier paquete de minería de datos serio
- Manejo de la incertidumbre
- Tratar con valores faltantes
- Tratar con datos ruidosos
- Eficiencia de los algoritmos
- Restringir el conocimiento descubierto a solo útil
- Incorporación del conocimiento del dominio
- Tamaño y complejidad de los datos
- Selección de datos
- Comprensiblemente del conocimiento descubierto: consistencia entre los datos y el conocimiento descubierto.
21. ¿Dar una introducción al lenguaje de consulta de minería de datos?
DBQL o Data Mining Query Language propuesto por Han, Fu, Wang, et.al. Este lenguaje funciona en el sistema de minería de datos DBMiner. Las consultas DBQL se basaron en SQL (lenguaje de consulta estructurada). También podemos utilizar este lenguaje para bases de datos y almacenes de datos. Este lenguaje de consulta admite la minería de datos interactiva y ad hoc.
22. ¿Diferenciar entre minería de datos y almacenamiento de datos?
Minería de datos: es el proceso de encontrar patrones y correlaciones dentro de grandes conjuntos de datos para identificar las relaciones entre los datos. Las herramientas de minería de datos permiten a una organización empresarial predecir el comportamiento del cliente. Las herramientas de minería de datos se utilizan para construir modelos de riesgo y detectar fraudes. La minería de datos se utiliza en el análisis y la gestión de mercados, la detección de fraudes, el análisis corporativo y la gestión de riesgos.
Es una tecnología que agrega datos estructurados de una o más fuentes para que puedan compararse y analizarse en lugar del procesamiento de transacciones.
Almacén de datos : un almacén de datos está diseñado para respaldar el proceso de toma de decisiones de gestión al proporcionar una plataforma para la limpieza, integración y consolidación de datos. Un almacén de datos contiene datos orientados a temas, integrados, variables en el tiempo y no volátiles.
El almacén de datos consolida datos de muchas fuentes al tiempo que garantiza la calidad, la coherencia y la precisión de los datos. El almacén de datos mejora el rendimiento del sistema al separar el procesamiento analítico de las bases de datos transnacionales. Los datos fluyen hacia un almacén de datos desde varias bases de datos. Un almacén de datos funciona organizando los datos en un esquema que describe el diseño y el tipo de datos. Las herramientas de consulta analizan las tablas de datos mediante el esquema.
23.¿Qué es la depuración de datos?
El término purga se puede definir como Borrar o Eliminar. En el contexto de la minería de datos, la depuración de datos es el proceso de eliminar datos innecesarios de la base de datos de forma permanente y limpiar los datos para mantener su integridad.
24. ¿Qué son los cubos?
Un cubo de datos almacena datos en una versión resumida que ayuda a un análisis más rápido de los datos. Los datos se almacenan de tal manera que permite informar fácilmente. Por ejemplo, utilizando un cubo de datos Un usuario puede querer analizar el rendimiento semanal o mensual de un empleado. Aquí, el mes y la semana podrían considerarse como las dimensiones del cubo.
25.¿Cuáles son las diferencias entre OLAP y OLTP?[IMP]
| OLAP (procesamiento analítico en línea) | OLTP (procesamiento de transacciones en línea) |
|---|---|
| Consiste en datos históricos de varias bases de datos. | Consiste únicamente en datos actuales operativos diarios orientados a la aplicación. |
| Orientado a la aplicación del día a día Está orientado a la materia. Utilizado para minería de datos, análisis, toma de decisiones, etc. | Está orientado a la aplicación. Se utiliza para tareas comerciales. |
| Los datos se utilizan en la planificación, la resolución de problemas y la toma de decisiones. | Los datos se utilizan para realizar operaciones fundamentales del día a día. |
| Revela una instantánea de las tareas comerciales actuales. | Proporciona una vista multidimensional de diferentes tareas comerciales. |
| Una gran cantidad de datos de forex se almacena típicamente en TB, PB | El tamaño de los datos es relativamente pequeño ya que se archivan los datos históricos. Por ejemplo, MB, GB |
| Relativamente lento ya que la cantidad de datos involucrados es grande. Las consultas pueden tardar horas. | Muy rápido ya que las consultas operan sobre el 5% de los datos. |
| Solo necesita una copia de seguridad de vez en cuando en comparación con OLTP. | El proceso de copia de seguridad y recuperación se mantiene religiosamente |
| Estos datos generalmente son administrados por el CEO, MD, GM. | Estos datos son administrados por empleados, gerentes. |
| Operación de solo lectura y raramente escritura. | Tanto operaciones de lectura como de escritura. |
26. ¿Explicar el algoritmo de asociación en la minería de datos?
El análisis de asociación es el hallazgo de reglas de asociación que muestran condiciones de valor de atributo que ocurren frecuentemente juntas en un conjunto dado de datos. El análisis de asociación se usa ampliamente para una canasta de mercado o análisis de datos de transacciones. La minería de reglas de asociación es un área significativa y excepcionalmente dinámica de la investigación de minería de datos. Un método de clasificación basada en asociaciones, llamado clasificación asociativa, consta de dos pasos. En el paso principal, las instrucciones de asociación se generan utilizando una versión modificada del algoritmo de minería de reglas de asociación estándar conocido como Apriori. El segundo paso construye un clasificador basado en las reglas de asociación descubiertas.
27. ¿Explicar cómo trabajar con algoritmos de minería de datos incluidos en la minería de datos del servidor SQL?
La minería de datos de SQL Server ofrece complementos de minería de datos para Office 2007 que permiten encontrar los patrones y relaciones de la información. Esto ayuda en un análisis mejorado. El Add-in llamado Data Mining Client for Excel se utiliza para preparar inicialmente información, crear modelos, gestionar, analizar, resultados.
28. Explique ¿Sobreajuste?
El concepto de sobreajuste es muy importante en la minería de datos. Se refiere a la situación en la que el algoritmo de inducción genera un clasificador que se ajusta perfectamente a los datos de entrenamiento pero ha perdido la capacidad de generalizar a instancias no presentadas durante el entrenamiento. En otras palabras, en lugar de aprender, el clasificador solo memoriza las instancias de entrenamiento. En los árboles de decisión, el ajuste excesivo suele ocurrir cuando el árbol tiene demasiados Nodes en relación con la cantidad de datos de entrenamiento disponibles. Al aumentar el número de Nodes, el error de entrenamiento suele disminuir, mientras que en algún momento el error de generalización empeora. El ajuste excesivo puede generar dificultades cuando hay ruido en los datos de entrenamiento o cuando el número de conjuntos de datos de entrenamiento, el error del árbol completamente construido es cero, mientras que el error real es probable que sea mayor.
Hay muchas desventajas de un árbol de decisión sobreajustado:
- Los modelos sobreajustados son incorrectos.
- Los árboles de decisión sobreajustados requieren más espacio y más recursos computacionales.
- Requieren la recopilación de características innecesarias.
29. ¿Define la poda de árboles?
Cuando se crea un árbol de decisiones, muchas de las ramas reflejarán anomalías en los datos de entrenamiento debido al ruido o a valores atípicos. Los métodos de poda de árboles abordan este problema de ajuste excesivo de los datos. Entonces, la poda de árboles es una técnica que elimina el problema del sobreajuste. Dichos métodos generalmente usan medidas estadísticas para eliminar las ramas menos confiables, lo que generalmente da como resultado una clasificación más rápida y una mejora en la capacidad del árbol para clasificar correctamente los datos de prueba independientes. La fase de poda elimina algunas de las ramas y nudos inferiores para mejorar su rendimiento. Procesamiento del árbol podado para mejorar la comprensibilidad.
30. ¿Qué es una picadura?
La Red de Información Estadística se llama STING; es una estrategia de agrupación en clústeres de resolución múltiple basada en cuadrículas. En la estrategia STING, cada uno de los elementos está contenido en celdas rectangulares, estas celdas se mantienen en diferentes grados de resolución y estos niveles se organizan en una estructura jerárquica.
31 . ¿Definir el método camaleón?
Chameleon es otra técnica de agrupación jerárquica que utiliza modelos dinámicos. Chameleon está familiarizado con la recuperación de las desventajas de la técnica de agrupamiento CURE. En esta técnica, se combinan dos grupos, si la interconectividad entre dos clústeres es mayor que la interconectividad entre el objeto dentro de un clúster/grupo.
32. Explique los problemas relacionados con la clasificación y la predicción.
Preparación de los datos para la clasificación y la predicción:
- Limpieza de datos
- Análisis de relevancia
- Transformación de datos
- Comparación de métodos de clasificación
- Precisión predictiva
- Velocidad
- Robustez
- Escalabilidad
- Interpretabilidad
33. Explique el uso de consultas de minería de datos o por qué las consultas de minería de datos son más útiles.
Las consultas de minería de datos se aplican principalmente al modelo de datos nuevos para generar resultados únicos o múltiples. También nos permite dar valores de entrada. La consulta puede recuperar información de manera efectiva si un patrón particular se define correctamente. Obtiene la memoria estadística de datos de entrenamiento y obtiene el diseño específico y la regla del caso común que aborda un patrón en el modelo. Ayuda a extraer las fórmulas de regresión y otros cálculos. También recupera los conocimientos sobre los casos individuales utilizados en el modelo. Incorpora la información que no se utiliza en el análisis, mantiene el modelo con la ayuda de agregar nuevos datos y realizar la tarea y la verificación cruzada.
34. ¿Qué es un enfoque basado en el aprendizaje automático para la minería de datos?
Esta pregunta es la Preguntas de entrevista de minería de datos de alto nivel que se hacen en una entrevista. El aprendizaje automático se utiliza básicamente en la minería de datos, ya que cubre los sistemas de procesamiento automático programado y dependía de tareas lógicas o binarias. . El aprendizaje automático en su mayor parte sigue la regla que nos permitiría administrar tipos de información más generales, incorporando casos y en estos tipos y la cantidad de atributos puede diferir. El aprendizaje automático es uno de los procedimientos famosos utilizados para la minería de datos y también en inteligencia artificial.
35.¿Qué es el algoritmo K-means?
Algoritmo de agrupamiento K-means : es el algoritmo de aprendizaje no supervisado más simple que resuelve problemas de agrupamiento. El algoritmo de K-medias divide n observaciones en k grupos, donde cada observación pertenece al grupo y la media más cercana sirve como prototipo del grupo.
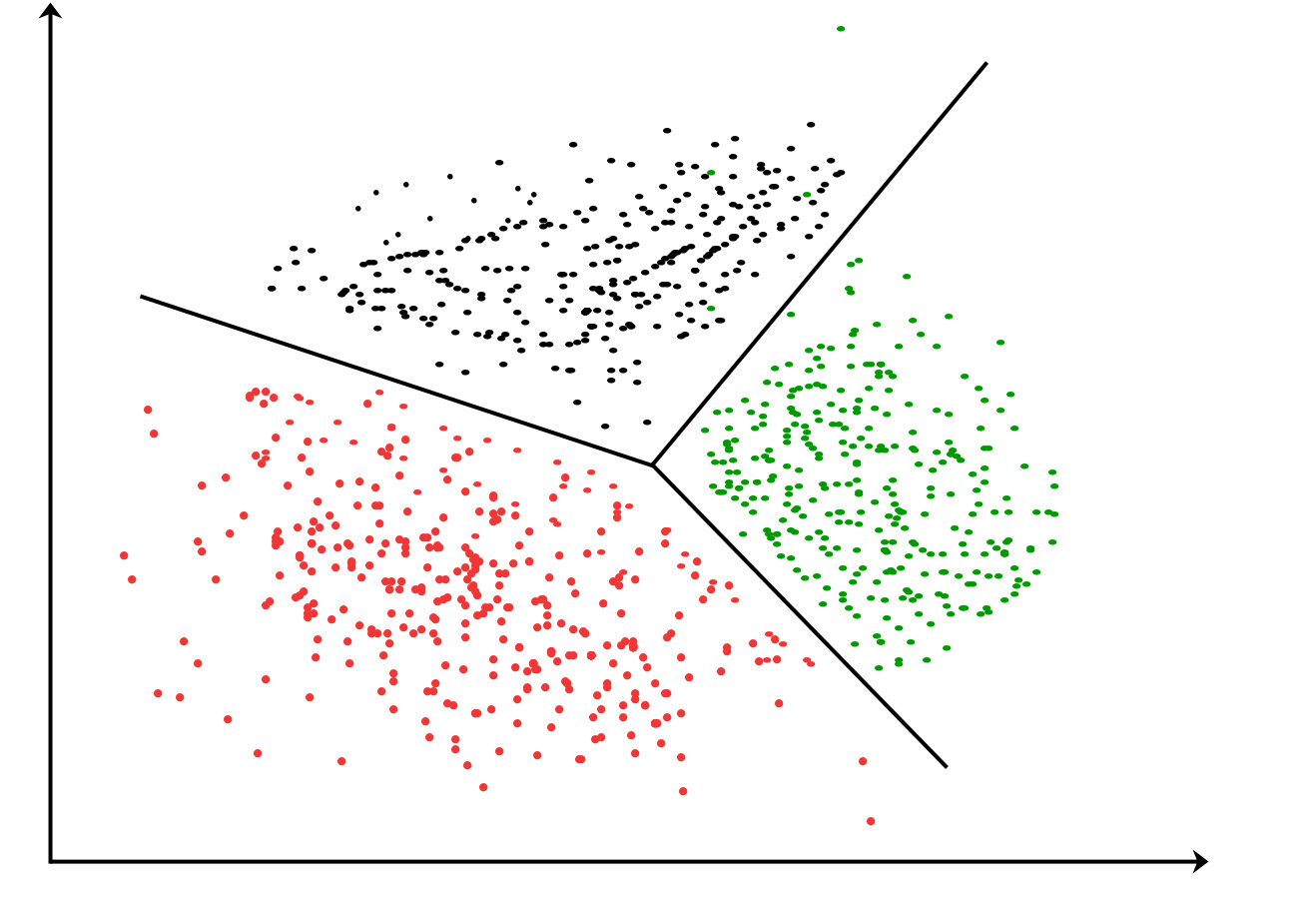
Figura: División de atributo de agrupamiento de K-Means
36. ¿Qué son la precisión y la recuperación? [IMP]
La precisión es la métrica de error más utilizada en el mecanismo de clasificación n. Su rango es de 0 a 1, donde 1 representa el 100%.
La recuperación se puede definir como el número de Positivos reales en nuestro modelo que tiene una etiqueta de clase como Positivo (Positivo verdadero)”. Recuerde y la tasa de verdaderos positivos es totalmente idéntica. Aquí está la fórmula para ello:
Recordar = (Verdadero positivo)/(Verdadero positivo + Falso negativo)
37. ¿Cuáles son las situaciones ideales en las que se puede utilizar la prueba t o la prueba z?
Es una práctica estándar que se utilice una prueba t cuando hay un tamaño de ejemplo por debajo de 30 atributos y la prueba z se considera cuando el tamaño de ejemplo supera los 30 en general.
38. ¿Cuál es la diferencia simple entre coeficientes estandarizados y no estandarizados?
En el caso de los coeficientes normalizados, se interpretan en función de sus valores de desviación estándar. Mientras que el coeficiente no estandarizado se estima en función del valor real presente en el conjunto de datos.
39. ¿Cómo se detectan los valores atípicos?
Se pueden utilizar numerosos enfoques para distinguir anomalías de valores atípicos, pero las dos técnicas más utilizadas generalmente son las siguientes:
- Estrategia de desviación estándar: Aquí, el valor se considera un valor atípico si el valor es inferior o superior a tres desviaciones estándar del valor medio.
- Técnica de diagrama de caja: aquí, un valor se considera un valor atípico si es menor o mayor que 1,5 veces el rango intercuartílico (RIC)
40. ¿Por qué se prefiere KNN al determinar los números que faltan en los datos?
Aquí se prefiere K-Vecino más cercano (KNN) debido al hecho de que KNN puede aproximar fácilmente el valor que se determinará en función de los valores más cercanos.
El clasificador k-vecino más cercano (K-NN) se tiene en cuenta como un clasificador basado en ejemplos, lo que significa que los documentos de capacitación se utilizan para la comparación en lugar de una ilustración de clase exacta, como los perfiles de clase utilizados por otros clasificadores. Como tal, no hay una sección de entrenamiento real. una vez que se tiene que clasificar un nuevo documento, se encuentran los k documentos más similares (vecinos) y si una proporción suficientemente grande de ellos se asigna a una clase precisa, el nuevo documento también se asigna a la clase actual, de lo contrario no. Además, la búsqueda de los vecinos más cercanos se acelera utilizando estrategias de clasificación tradicionales.
41. ¿Explicar el enfoque de prepoda y pospoda en la clasificación?
Prepoda: en el enfoque de prepoda, un árbol se «poda» deteniendo su construcción antes de tiempo (por ejemplo, al decidir no dividir o particionar más el subconjunto de muestras de entrenamiento en un Node determinado). Al detenerse, el Node se convierte en una hoja. La hoja puede contener la clase más frecuente entre las muestras de subconjuntos, o la distribución de probabilidad de esas muestras. Al construir un árbol, se pueden usar medidas como la significación estadística, la ganancia de información, etc., para evaluar la bondad de una división. Si la partición de las muestras en un Node da como resultado una división que cae por debajo de un umbral preespecificado, entonces se detiene la partición adicional del subconjunto dado. Hay problemas, sin embargo, en la elección de un umbral adecuado. Los umbrales altos pueden resultar en árboles simplificados en exceso, mientras que los umbrales bajos pueden resultar en una simplificación muy pequeña.
Postpoda:El enfoque posterior a la poda elimina las ramas de un árbol «completamente desarrollado». Un Node de árbol se poda quitando sus ramas. El algoritmo de poda de complejidad de costos es un ejemplo del enfoque posterior a la poda. El nudo podado se convierte en una hoja y se etiqueta con la clase más frecuente entre sus ramas anteriores. Para cada Node que no sea hoja en el árbol, el algoritmo calcula la tasa de error esperada que ocurriría si se podara el subárbol en ese Node. A continuación, se calcula la tasa de error predecible que se produciría si el Node no se podara utilizando las tasas de error de cada rama, colectivas mediante la ponderación según la proporción de observaciones a lo largo de cada rama. Si podar el Node conduce a una mayor tasa de error probable, entonces se reserva el subárbol. De lo contrario, se poda. Después de generar un conjunto de árboles progresivamente podados, se utiliza un conjunto de prueba independiente para estimar la precisión de cada árbol. Se prefiere el árbol de decisión que minimiza la tasa de error esperada.
42. ¿Cómo se pueden manejar datos sospechosos o faltantes en un conjunto de datos mientras se realiza el análisis?
Si hay alguna inconsistencia o incertidumbre en el conjunto de datos, un usuario puede proceder a utilizar cualquiera de las técnicas adjuntas: Creación de un informe de validación con información sobre los datos en conversación Escalar algo muy similar a un analista de datos experimentado para que eche un vistazo y aceptar una llamada. Reemplazar la información inválida con una comparación de datos sustanciales y más recientes. Usar numerosas metodologías juntas para descubrir valores faltantes y utilizar estimaciones aproximadas si es necesario.
43.¿Cuál es la diferencia simple entre el análisis de componentes principales (PCA) y el análisis factorial (FA)?
Entre numerosas diferencias, la diferencia significativa entre PCA y FA es que el análisis factorial se utiliza para determinar y trabajar con la varianza entre variables, pero el objetivo de PCA es explicar la covarianza entre los segmentos o variables actuales.
44 . ¿Cuál es la diferencia entre minería de datos y análisis de datos?
| Procesamiento de datos | Análisis de los datos |
|---|---|
| Se utiliza para percibir diseños en los datos almacenados. | Se utiliza para organizar y reunir información sin procesar de manera significativa. |
| La minería se realiza en lugares limpios y bien documentados. | El análisis de la información incluye Limpieza de Datos. Por lo tanto, la información no está disponible en un formato bien documentado. |
| Los resultados extraídos de la minería de datos son difíciles de interpretar. | Los resultados extraídos del análisis de la información no son difíciles de interpretar. |
45. ¿Cuál es la diferencia entre Data Mining y Data Profiling?
- Minería de datos: La minería de datos se refiere al análisis de información con respecto al descubrimiento de relaciones que no se han encontrado antes. Se centra principalmente en el reconocimiento de registros extraños, condiciones y examen de grupos.
- Perfilado de datos : el perfilado de datos se puede describir como un proceso de análisis de atributos únicos de datos. Se enfoca principalmente en brindar datos significativos sobre atributos de información, por ejemplo, tipo de información, recurrencia, etc.
46. ¿Cuáles son los pasos importantes en el proceso de validación de datos?
Como su nombre lo indica, la Validación de datos es el proceso de aprobación de la información. Esta progresión tiene principalmente dos métodos asociados con ella. Estos son la detección de datos y la verificación de datos.
- Detección de datos : se utilizan diferentes tipos de cálculos en esta progresión para filtrar toda la información para descubrir cualquier calidad inexacta.
- Verificación de datos: todos y cada uno de los valores supuestos se evalúan en diferentes casos de uso, y luego se toma una conclusión final sobre si el valor debe recordarse para la información o no.
47. ¿Cuál es la diferencia entre el análisis univariado, bivariado y multivariado?
La principal diferencia entre la investigación univariada, bivariada y multivariada es la siguiente:
- Univariado : Un procedimiento estadístico que se puede separar dependiendo de la verificación de factores requeridos en un momento dado.
- Bivariante : este análisis se utiliza para descubrir la distinción entre dos variables a la vez.
- Multivariante : El análisis de múltiples variables se conoce como multivariante. Este análisis se utiliza para comprender el impacto de los factores en las respuestas.
48. ¿Cuál es la diferencia entre varianza y covarianza?
La varianza y la covarianza son dos términos matemáticos que se encuentran con frecuencia en el campo de las estadísticas. La varianza procesa fundamentalmente cómo se separan los números según la media. La covarianza se refiere a cómo cambiarán juntos dos factores aleatorios/irregulares. Esto se utiliza esencialmente para calcular la correlación entre variables.
49. ¿Cuáles son los diferentes tipos de pruebas de hipótesis?
Los diversos tipos de pruebas de hipótesis son los siguientes:
- Prueba T: se utiliza una prueba T cuando se desconoce la desviación estándar y el tamaño de la muestra es casi pequeño.
- Prueba de Chi-Cuadrado para Independencia: Estas pruebas se utilizan para descubrir el significado de la asociación entre todas las variables categóricas en la muestra de población.
- Análisis de varianza (ANOVA): este tipo de prueba de hipótesis se utiliza para examinar los contrastes entre los métodos en diferentes grupos. Esta prueba se utiliza comparativamente con una prueba T, pero se utiliza para múltiples grupos.
Prueba T de Welch: esta prueba se utiliza para descubrir la prueba de igualdad de medias entre dos pruebas de muestra de prueba.
50. ¿Por qué deberíamos utilizar almacenamiento de datos y cómo se pueden extraer datos para su análisis?
El almacenamiento de datos es una tecnología clave en el camino hacia el establecimiento de inteligencia comercial. Un almacén de datos es una colección de datos extraídos de los sistemas operativos o transaccionales de una empresa, transformados para limpiar cualquier incoherencia en la codificación y definición de identificación, y luego organizados para respaldar informes y análisis rápidos.
Estos son algunos de los beneficios de un almacén de datos:
- Es independiente de la base de datos operativa.
- Integra datos de sistemas heterogéneos.
- Almacena una enorme cantidad de datos, más históricos que actuales.
- No requiere que los datos sean muy precisos.
Preguntas y respuestas de la entrevista de bonificación
1. ¿Qué es la visualización?
La visualización es para la representación de datos y para ganar intuición sobre los datos que se observan. Ayuda a los analistas a seleccionar los formatos de visualización, las perspectivas del espectador y el esquema de representación de datos.
2. ¿Dar algunas herramientas de minería de datos?
- DBMiner
- geominero
- minero multimedia
- WeblogMiner
3. ¿Cuáles son las ventajas más significativas de la Minería de Datos?
Hay muchas ventajas de la Minería de Datos. Algunos de ellos se enumeran a continuación:
- La minería de datos se utiliza para pulir los datos sin procesar y hacernos capaces de explorar, identificar y comprender los patrones ocultos dentro de los datos.
- Automatiza la búsqueda de información predictiva en grandes bases de datos, lo que ayuda a identificar rápidamente los patrones previamente ocultos.
- Ayuda a tomar mejores y más rápidas decisiones, lo que luego ayuda a las empresas a tomar las medidas necesarias para aumentar los ingresos y reducir los costos operativos.
- También se utiliza para ayudar a filtrar y validar datos para comprender de dónde provienen.
- Utilizando las técnicas de Minería de Datos, los expertos pueden gestionar aplicaciones en diversas áreas como Análisis de Mercado, Control de Producción, Deportes, Detección de Fraudes, Astrología, etc.
- Los sitios web de compras utilizan la minería de datos para definir un patrón de compras y diseñar o seleccionar los productos para una mejor generación de ingresos.
- La minería de datos también ayuda en la optimización de datos.
- La minería de datos también se puede utilizar para determinar la rentabilidad oculta.
4. ¿Qué son ‘Conjunto de entrenamiento’ y ‘Conjunto de prueba’?
En varias áreas de la ciencia de la información, como el aprendizaje automático, se utiliza un conjunto de datos para descubrir la relación potencialmente predictiva conocida como «Conjunto de entrenamiento». El conjunto de entrenamiento es un ejemplo que se le da al alumno, mientras que el Conjunto de prueba se usa para probar la precisión de las hipótesis generadas por el alumno, y es el conjunto de ejemplos retenidos del alumno. El conjunto de entrenamiento es distinto del conjunto de prueba.
5. Explique cuál es la función del ‘Aprendizaje no supervisado’.
- Buscar grupos de datos
- Encuentre representaciones de baja dimensión de los datos
- Encuentre direcciones interesantes en los datos
- Coordenadas y correlaciones interesantes
- Encuentre observaciones novedosas/limpieza de bases de datos
6. ¿En qué áreas se utiliza el reconocimiento de patrones?
El reconocimiento de patrones se puede utilizar en
- Visión por computador
- Reconocimiento de voz
- Procesamiento de datos
- Estadísticas
- Recuperación informal
- Bioinformática
7. ¿Qué es el aprendizaje conjunto?
Para resolver un programa computacional particular, múltiples modelos como clasificadores o expertos se generan estratégicamente y se combinan para resolver un programa computacional particular Múltiple. Este proceso se conoce como aprendizaje conjunto. El aprendizaje por conjuntos se usa cuando construimos clasificadores de componentes que son más precisos e independientes entre sí. Este aprendizaje se utiliza para mejorar la clasificación, la predicción de datos y la aproximación de funciones.
8. ¿Cuál es el principio general de un método de conjunto y qué es embolsado y potenciado en el método de conjunto?
El principio general de un método de conjunto es combinar las predicciones de varios modelos construidos con un algoritmo de aprendizaje dado para mejorar la robustez de un solo modelo. El embolsado es un método en un conjunto para mejorar los esquemas de estimación o clasificación inestables. Mientras que los métodos de impulso se utilizan secuencialmente para reducir el sesgo del modelo combinado. Boosting y Bagging pueden reducir los errores al reducir el término de varianza.
9. ¿Cuáles son los componentes de las técnicas de evaluación relacional?
Los componentes importantes de las técnicas de evaluación relacional son
- Adquisición de datos
- Adquisición de Ground Truth
- Técnica de validación cruzada
- Tipo de consulta
- Métrica de puntuación
- Prueba de significancia
10. ¿Cuáles son los diferentes métodos para el aprendizaje supervisado secuencial?
Los diferentes métodos para resolver problemas de Aprendizaje Supervisado Secuencial son
- Métodos de ventana deslizante
- Ventanas correderas recurrentes
- Modelos ocultos de Markow
- Máxima entropía Modelos de Markow
- Campos aleatorios condicionales
- Graficar redes de transformadores
11. ¿Qué es un bosque aleatorio?
Random forest es un método de aprendizaje automático que lo ayuda a realizar todo tipo de tareas de regresión y clasificación. También se utiliza para tratar valores perdidos y valores atípicos.
12. ¿Qué es el aprendizaje por refuerzo?
El aprendizaje por refuerzo es un mecanismo de aprendizaje sobre cómo mapear situaciones en acciones. El resultado final debería ayudarlo a aumentar la señal de recompensa binaria. En este método, al alumno no se le dice qué acción tomar, sino que debe descubrir qué acción ofrece la máxima recompensa. Este método se basa en el mecanismo de recompensa/penalización.
13. ¿Es posible capturar la correlación entre variables continuas y categóricas?
Sí, podemos utilizar la técnica de análisis de covarianza para capturar la asociación entre variables continuas y categóricas.
14. ¿Qué es la visualización?
La visualización es para la representación de información y para adquirir conocimiento sobre la información que se está observando. Ayuda a los expertos a elegir diseños de formato, perspectivas del espectador y patrones de representación de la información.
15. Mencione algunas de las mejores herramientas que se pueden usar para el análisis de datos.
Las herramientas útiles más comunes para el análisis de datos son:
- Operadores de búsqueda de Google
- cuchillo
- Cuadro
- solucionador
- RapidMiner
- yo
- NodeXL
16. ¿Describa la estructura de las Redes Neuronales Artificiales?
Una red neuronal artificial (ANN), también denominada simplemente «Red neuronal» (NN), podría ser un modelo de proceso respaldado por redes neuronales biológicas. Su estructura consiste en una colección interconectada de neuronas artificiales. Una red neuronal artificial es un sistema de adjetivos que cambia su información respaldada por estructura que fluye a través de la red artificial durante una sección de aprendizaje. La ANN se basa en el principio de aprender con el ejemplo. Hay, sin embargo, 2 tipos clásicos de redes neuronales, perceptrón y también perceptrón multicapa. Aquí vamos a centrarnos en la regla algorítmica del perceptrón.
17. ¿Crees que 50 árboles de decisión pequeños son mejores que uno grande? ¿Por qué?
Sí, 50 árboles de decisión pequeños son mejores que uno grande porque 50 árboles hacen un modelo más robusto (menos sujeto a sobreajuste) y más simple de interpretar.
Publicación traducida automáticamente
Artículo escrito por varshachoudhary y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA