A menudo, los datos que se van a leer y trabajar ya están almacenados en un archivo, pero están presentes fuera del entorno R. Por lo tanto, importar datos a R es una tarea obligatoria en tales circunstancias. Los formatos compatibles con R son CSV, JSON, Excel, Text, XML, etc. La mayoría de las veces, los datos que se leerán en R están en formato tabular. Las funciones utilizadas para leer dichos datos, que se almacenan en forma de filas y columnas, importan los datos y devuelven el marco de datos en R. Se prefiere el marco de datos en R porque es más fácil extraer datos de filas y columnas de un marco de datos. para tareas de cálculo estadístico que otras estructuras de datos en R. Las funciones más comunes que se utilizan para leer datos tabulares en R son: – read.table() ,read.csv() , fromJSON() y read.xlxs() .
Lectura de datos de un archivo de texto
Las funciones utilizadas para leer datos tabulares de un archivo de texto sonread.table()
Parámetros:
- archivo: especifica el nombre del archivo.
- encabezado: El encabezado es un indicador lógico que indica si la primera línea es una línea de encabezado que contiene datos o no.
- nrows: especifica el número de filas en el conjunto de datos.
- skip: Ayuda a saltar líneas desde el principio.
- colClasses: Es un vector de caracteres que indica la clase de cada columna del conjunto de datos.
- sep: Es una string que indica la forma en que se separan las columnas, es decir, por comas, espacios, dos puntos, tabulaciones, etc.
Para conjuntos de datos pequeños o de tamaño moderado, podemos llamar a read.table() sin ningún argumento. R calculará automáticamente la cantidad de filas, la cantidad de columnas, las clases de diferentes columnas, las líneas de salto que comienzan con # (símbolo de comentario), etc. Si especificamos los argumentos, hará que la ejecución sea más rápida y eficiente, pero aquí , dado que el conjunto de datos es pequeño, no haría mucha diferencia, ya que ya es rápido y eficiente.
Ejemplo:
Deje que haya un archivo de datos tabulares GeeksforGeeks.txt guardado en el directorio actual con datos de la siguiente manera: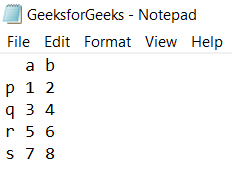
read.table("GeeksforGeeks.txt")
Producción: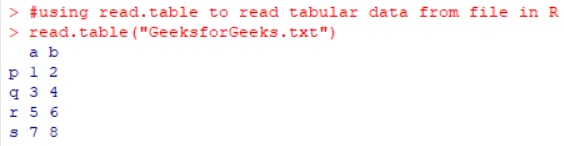
Lectura de datos de un archivo CSV
read.csv()La función se utiliza para leer archivos .csv, que es un formato muy común seguido por aplicaciones de hojas de cálculo como Microsoft Excel. read.csv() es similar a read.table() excepto que el separador predeterminado para la función read.csv() es la coma, mientras que el separador predeterminado para read.table() es el espacio. La otra cosa que especifica read.csv() es que siempre especificó que el encabezado sea igual a verdadero.
Al leer archivos grandes, un punto a tener en cuenta es calcular la memoria aproximada requerida para almacenar el conjunto de datos. Es para asegurarse de que no sea más que la RAM disponible en el dispositivo en el que estamos trabajando. La memoria requerida se puede calcular como se muestra a continuación:
Consider the table has 2000000 rows and 200 columns considering if all the columns are
of class numeric. 2000000 x 200 x 8 bytes/numeric #each number requires 8 bytes to be stored =3200000000/bytes/MB =3051.76/
MB =2.98 GB Approximately twice this amount of RAM i.e.5.96 GB will be required.
Otra medida que se puede seguir para reducir el consumo de tiempo es incluir el argumento colClasses para que R no tenga que buscar la clase de cada columna del dataset. Si el número de filas, es decir , nrows , se especifica de antemano, será útil para reducir el uso de la memoria.
Ejemplo:
Deje que haya un archivo de datos tabulares GeeksforGeeks.csv guardado en el directorio actual con datos de la siguiente manera: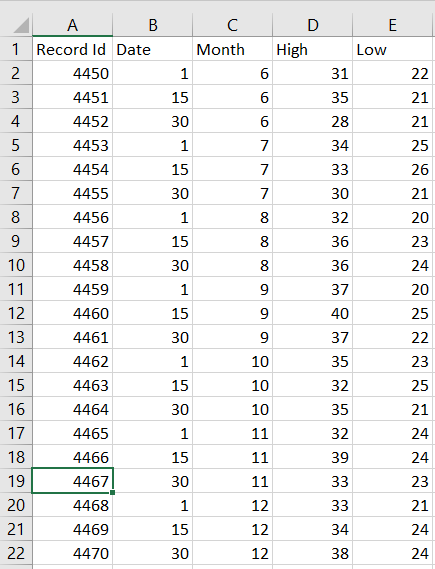
read.csv("GeeksforGeeks.csv")
Producción :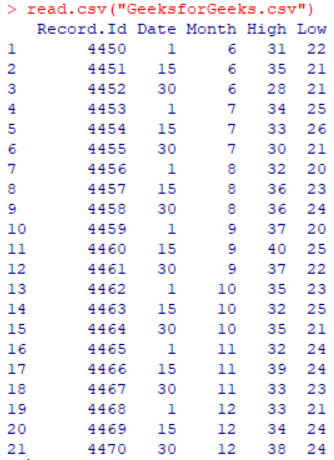
Lectura de datos del archivo JSON
fromJSON()La función se utiliza para convertir datos JSON en objetos R. Esta función requiere la instalación del paquete rjson . Esto se puede hacer con el siguiente comando:
install.packages("rjson")
Ejemplo:
Deje que haya un archivo .json GeeksforGeeks.json guardado en el directorio actual con el siguiente contenido:
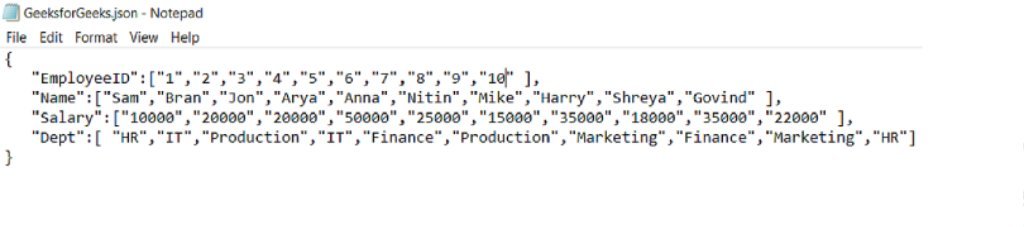
library(rjson) #loads the rjson library fromJSON(file="GeeksforGeeks.json")
Producción:
as.data.frame(fromJSON(file="GeeksforGeeks.json"))
Producción: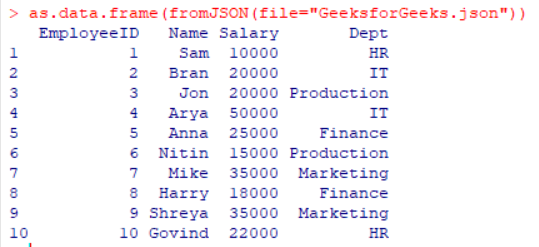
Lectura de hojas de Excel
La función R read.xlsx()se utiliza para leer el contenido de una hoja de cálculo de Excel en un marco de datos R. Esta función requiere la instalación del paquete xlsx . Esto se puede hacer usando el siguiente comando:
install.packages("xlsx")
Ejemplo:
Sea un archivo de Excel gfg.xlsx guardado en el directorio actual con el siguiente contenido:
library("xlsx") #loads the xlsx library
read.xlsx("gfg.xlsx", 1) #here 1 represents the sheet number
Producción:
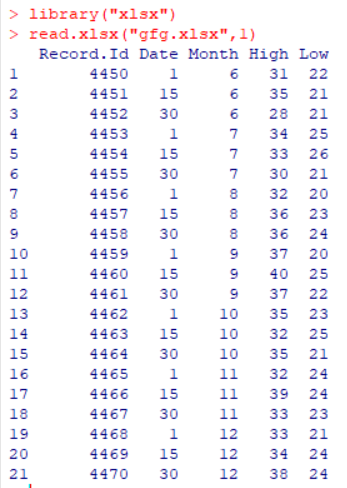
Here, we can observe that the read.xlsx() has returned a data.frame as output.
Pero si se van a leer grandes conjuntos de datos (con más de 100000 celdas), entonces se prefiere usar read.xlsx2() . read.xlsx2() funciona más rápido en archivos grandes que read.xlsx( ). El resultado de read.xlsx2() será diferente de read.xlsx() , porque internamente read.xlsx2() usa readColumns(), que está diseñado para datos tabulados.
Publicación traducida automáticamente
Artículo escrito por anupama0699 y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA