En este artículo, vamos a ver cómo leer archivos de texto en PySpark Dataframe.
Hay tres formas de leer archivos de texto en PySpark DataFrame.
- Usando chispa.read.text()
- Usando chispa.read.csv()
- Usando spark.read.format().load()
Con estos, podemos leer un solo archivo de texto, varios archivos y todos los archivos de un directorio en Spark DataFrame y Dataset.
Archivo de texto utilizado:

Método 1: Usar spark.read.text()
Se utiliza para cargar archivos de texto en DataFrame cuyo esquema comienza con una columna de string. Cada línea en el archivo de texto es una nueva fila en el DataFrame resultante. Con este método también podemos leer varios archivos a la vez.
Sintaxis: spark.read.text(rutas)
Parámetros: este método acepta el siguiente parámetro como se mencionó anteriormente y se describe a continuación.
- rutas: es una string, o una lista de strings, para la(s) ruta(s) de entrada.
Devoluciones: marco de datos
Ejemplo: Lea un archivo de texto usando spark.read.text().
Aquí importaremos el módulo y crearemos una sesión de chispa y luego leeremos el archivo con spark.read.text() , luego crearemos columnas y dividiremos los datos del archivo txt que se muestra en un marco de datos.
Python3
from pyspark.sql import SparkSession
spark = SparkSession.builder.appName("DataFrame").getOrCreate()
df = spark.read.text("output.txt")
df.selectExpr("split(value, ' ') as\
Text_Data_In_Rows_Using_Text").show(4,False)
Producción:

Método 2: Usar spark.read.csv()
Se utiliza para cargar archivos de texto en DataFrame. Usando este método, revisaremos la entrada una vez para determinar el esquema de entrada si inferSchema está habilitado. Para evitar pasar por todos los datos una vez, deshabilite la opción inferSchema o especifique el esquema explícitamente usando el esquema.
Sintaxis: spark.read.csv(ruta)
Devoluciones: marco de datos
Ejemplo: Lea un archivo de texto usando spark.read.csv().
Primero, importe los módulos y cree una sesión de chispa y luego lea el archivo con spark.read.csv(), luego cree columnas y divida los datos del archivo txt que se muestra en un marco de datos.
Python3
from pyspark.sql import SparkSession
spark = SparkSession.builder.getOrCreate()
df = spark.read.csv("output.txt")
df.selectExpr("split(_c0, ' ')\
as Text_Data_In_Rows_Using_CSV").show(4,False)
Producción:

Método 3: Usar spark.read.format()
Se utiliza para cargar archivos de texto en DataFrame. El .format() especifica el formato de la fuente de datos de entrada como «texto». El .load() carga datos de una fuente de datos y devuelve DataFrame.
Sintaxis: spark.read.format(“texto”).load(ruta=Ninguno, formato=Ninguno, esquema=Ninguno, **opciones)
Parámetros: este método acepta el siguiente parámetro como se mencionó anteriormente y se describe a continuación.
- rutas: es una string, o una lista de strings, para la(s) ruta(s) de entrada.
- format : es una string opcional para el formato de la fuente de datos. Predeterminado a ‘parquet’.
- esquema: es un pyspark.sql.types.StructType opcional para el esquema de entrada.
- opciones: todas las demás opciones de string
Devoluciones: marco de datos
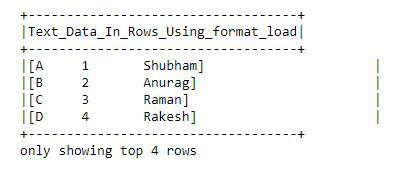
Ejemplo: Lea un archivo de texto usando spark.read.format().
Primero, importe los módulos y cree una sesión de chispa y luego lea el archivo con spark.read.format() , luego cree columnas y divida los datos del archivo txt que se muestra en un marco de datos.
Python3
from pyspark.sql import SparkSession
spark = SparkSession.builder.getOrCreate()
df = spark.read.format("text").load("output.txt")
df.selectExpr("split(value, ' ')\
as Text_Data_In_Rows_Using_format_load").show(4,False)
Producción:
Publicación traducida automáticamente
Artículo escrito por SHUBHAMSINGH10 y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA