En este artículo, veremos cómo leer múltiples archivos CSV en tramas de datos separadas. Para leer solo un marco de datos, podemos usar la función pd.read_csv() de pandas. Toma una ruta como entrada y devuelve un marco de datos como
df = pd.read_csv("file path")
Echemos un vistazo a cómo funciona.
Python3
# import module
import pandas as pd
# read dataset
df = pd.read_csv("./csv/crime.csv")
Aquí, crime.csv es el archivo en la carpeta actual. CSV es la carpeta que contiene el archivo crime.csv y CSV Reader.ipynb es el archivo que contiene el código anterior.
Producción:
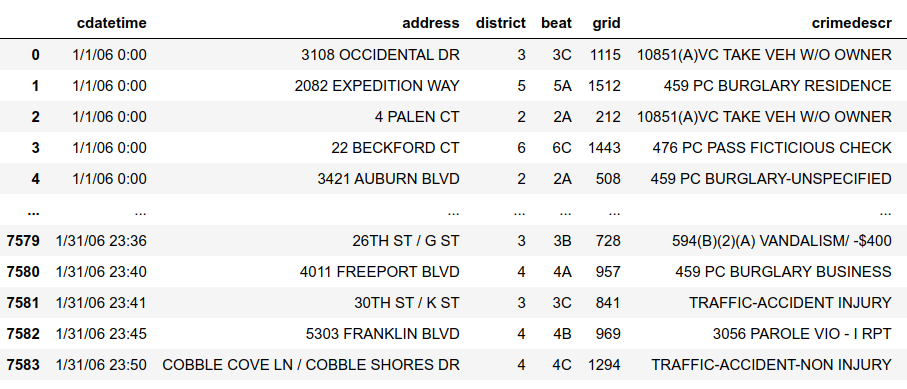
Es el marco de datos que se lee de la función anterior. Un archivo más está presente en la carpeta llamada: nombredeusuario.csv. Para leerlos y almacenarlos en diferentes marcos de datos, use el siguiente código
Python3
# import module
import pandas as pd
# assign dataset names
list_of_names = ['crime','username']
# create empty list
dataframes_list = []
# append datasets into the list
for i in range(len(list_of_names)):
temp_df = pd.read_csv("./csv/"+list_of_names[i]+".csv")
dataframes_list.append(temp_df)
dataframes_list contiene todos los marcos de datos por separado.
dataframes_list[0]:
lista_de_marcos_de_datos[1]:
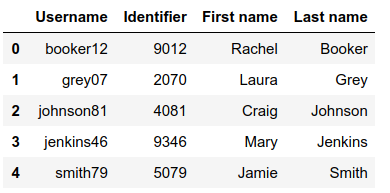
Aquí hay otro enfoque, ahora suponga que hay muchos archivos, y no sabemos los nombres y el número entonces, use el siguiente código
Python3
# import modules
import os
import pandas as pd
# assign path
path, dirs, files = next(os.walk("./csv/"))
file_count = len(files)
# create empty list
dataframes_list = []
# append datasets to the list
for i in range(file_count):
temp_df = pd.read_csv("./csv/"+files[i])
dataframes_list.append(temp_df)
# display datasets
for dataset in dataframes_list:
display(dataset)
Producción:
Publicación traducida automáticamente
Artículo escrito por AyanChawla y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA