El formato CSV (valores separados por comas) es el formato de importación y exportación más común para hojas de cálculo y bases de datos. Es uno de los métodos más comunes para intercambiar datos entre aplicaciones y un formato de datos popular utilizado en Data Science. Es compatible con una amplia gama de aplicaciones. Un archivo CSV almacena datos tabulares en los que cada campo de datos está separado por un delimitador (coma en la mayoría de los casos). Para representar un archivo CSV, debe guardarse con la extensión de archivo .csv .
Lectura desde un archivo CSV
Python contiene un módulo llamado csvpara el manejo de archivos CSV. La clase de lector del módulo se utiliza para leer datos de un archivo CSV. Al principio, el archivo CSV se abre usando el método open() en modo ‘r’ (especifica el modo de lectura al abrir un archivo) que devuelve el objeto de archivo y luego se lee usando el reader()método del módulo CSV que devuelve el objeto lector que itera a lo largo de las líneas en el documento CSV especificado.
Sintaxis:
csv.reader(csvfile, dialect='excel', **fmtparams
Nota: La palabra clave ‘with’ se usa junto con el open()método, ya que simplifica el manejo de excepciones y cierra automáticamente el archivo CSV.
Ejemplo:
Considere el siguiente archivo CSV –

import csv
# opening the CSV file
with open('Giants.csv', mode ='r')as file:
# reading the CSV file
csvFile = csv.reader(file)
# displaying the contents of the CSV file
for lines in csvFile:
print(lines)
Producción:
[['Steve', 13, 'A'], ['John', 14, 'F'], ['Nancy', 14, 'C'], ['Ravi', 13, 'B']]
Escribir en un archivo CSV
csv.writerLa clase se utiliza para insertar datos en el archivo CSV. Esta clase devuelve un objeto escritor que es responsable de convertir los datos del usuario en una string delimitada. Un objeto de archivo CSV debe abrirse con newline=”; de lo contrario, los caracteres de nueva línea dentro de los campos citados no se interpretarán correctamente.
Sintaxis:
csv.writer(csvfile, dialect='excel', **fmtparams)
La clase csv.writer proporciona dos métodos para escribir en CSV. son writerow()y writerows().
- writerow(): este método escribe una sola fila a la vez. La fila de campo se puede escribir usando este método.
Sintaxis:writerow(fields)
- writerows(): este método se utiliza para escribir varias filas a la vez. Esto se puede usar para escribir una lista de filas.
Sintaxis:writerows(rows)
Ejemplo:
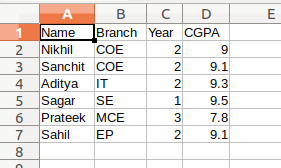
# Python program to demonstrate # writing to CSV import csv # field names fields = ['Name', 'Branch', 'Year', 'CGPA'] # data rows of csv file rows = [ ['Nikhil', 'COE', '2', '9.0'], ['Sanchit', 'COE', '2', '9.1'], ['Aditya', 'IT', '2', '9.3'], ['Sagar', 'SE', '1', '9.5'], ['Prateek', 'MCE', '3', '7.8'], ['Sahil', 'EP', '2', '9.1']] # name of csv file filename = "university_records.csv" # writing to csv file with open(filename, 'w') as csvfile: # creating a csv writer object csvwriter = csv.writer(csvfile) # writing the fields csvwriter.writerow(fields) # writing the data rows csvwriter.writerows(rows)
Producción:
También podemos escribir diccionario en el archivo CSV. Para esto, el módulo CSV proporciona la clase csv.DictWriter. Esta clase devuelve un objeto escritor que asigna diccionarios a las filas de salida.
Sintaxis:
csv.DictWriter(csvfile, nombres de campo, restval=”, extrasaction=’raise’, dialect=’excel’, *args, **kwds)
csv.DictWriter proporciona dos métodos para escribir en CSV. Están:
- writeheader():
writeheader()el método simplemente escribe la primera fila de su archivo csv usando los nombres de campo preespecificados.Sintaxis:
writeheader()
- writerows():
writerowsel método simplemente escribe todas las filas, pero en cada fila, escribe solo los valores (no las claves).Sintaxis:
writerows(mydict)
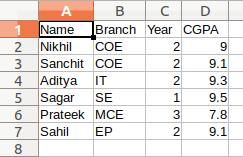
Ejemplo:
# importing the csv module
import csv
# my data rows as dictionary objects
mydict =[{'branch': 'COE', 'cgpa': '9.0', 'name': 'Nikhil', 'year': '2'},
{'branch': 'COE', 'cgpa': '9.1', 'name': 'Sanchit', 'year': '2'},
{'branch': 'IT', 'cgpa': '9.3', 'name': 'Aditya', 'year': '2'},
{'branch': 'SE', 'cgpa': '9.5', 'name': 'Sagar', 'year': '1'},
{'branch': 'MCE', 'cgpa': '7.8', 'name': 'Prateek', 'year': '3'},
{'branch': 'EP', 'cgpa': '9.1', 'name': 'Sahil', 'year': '2'}]
# field names
fields = ['name', 'branch', 'year', 'cgpa']
# name of csv file
filename = "university_records.csv"
# writing to csv file
with open(filename, 'w') as csvfile:
# creating a csv dict writer object
writer = csv.DictWriter(csvfile, fieldnames = fields)
# writing headers (field names)
writer.writeheader()
# writing data rows
writer.writerows(mydict)
Producción:
Publicación traducida automáticamente
Artículo escrito por Raghav Ganesh y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA