Al tratar con un marco de datos de gran tamaño que consta de muchas filas y columnas, también consta de muchos valores NULL o None en alguna fila o columna, o algunas de las filas son totalmente NULL o None. Entonces, en este caso, si aplicamos una operación en el mismo marco de datos que contiene muchos valores NULOS o ninguno, entonces no obtendremos el resultado correcto o deseado de ese marco de datos. Para obtener el resultado correcto del marco de datos, debemos limpiarlo, lo que significa que debemos hacer que el marco de datos esté libre de valores NULL o Ninguno.
Entonces, en este artículo, aprenderemos cómo limpiar el marco de datos. Para limpiar el Dataframe estamos usando la función dropna() . Esta función se utiliza para eliminar los valores NULL del marco de datos en función de un parámetro dado.
Sintaxis: df.dropna(how=”any”, thresh=Ninguno, subconjunto=Ninguno)
donde, df es el marco de datos
Parámetro:
- cómo: este parámetro se usa para determinar si la fila o columna debe eliminarse o no.
- ‘cualquiera’: si alguno de los valores en Dataframe es NULL, suelte esa fila o columna.
- ‘todos’: si todos los valores de una fila o columna en particular son NULOS, entonces suéltelos.
- umbral: si los valores no NULL de una fila o columna en particular son menores que el valor umbral, entonces suelte esa fila o columna.
- subconjunto: si la columna de subconjunto dada contiene alguno de los valores nulos, entonces doble esa fila o columna.
Para descartar los valores nulos usando el método dropna, primero, crearemos un marco de datos de Pyspark y luego lo aplicaremos.
Python
# importing necessary libraries
from pyspark.sql import SparkSession
# function to create new SparkSession
def create_session():
spk = SparkSession.builder \
.master("local") \
.appName("Employee_detail.com") \
.getOrCreate()
return spk
def create_df(spark, data, schema):
df1 = spark.createDataFrame(data, schema)
return df1
if __name__ == "__main__":
# calling function to create SparkSession
spark = create_session()
input_data = [(1, "Shivansh", "Data Scientist", "Noida"),
(2, None, "Software Developer", None),
(3, "Swati", "Data Analyst", "Hyderabad"),
(4, None, None, "Noida"),
(5, "Arpit", "Android Developer", "Banglore"),
(6, "Ritik", None, None),
(None, None, None, None)]
schema = ["Id", "Name", "Job Profile", "City"]
# calling function to create dataframe
df = create_df(spark, input_data, schema)
df.show()
Producción:
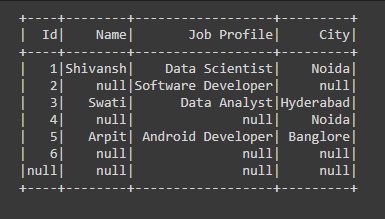
Ejemplo 1: limpieza de datos con dropna usando cualquier parámetro en PySpark.
En el siguiente código, hemos pasado el parámetro how=”any” en la función dropna(), lo que significa que si hay alguna fila o columna que tiene alguno de los valores nulos, estamos eliminando esa fila o columna del marco de datos.
Python
# if any row having any Null # value we are dropping that # rows df = df.dropna(how="any") df.show()
Producción:
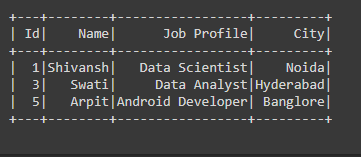
Ejemplo 2: Limpieza de datos con dropna usando todos los parámetros en PySpark.
En el siguiente código, hemos pasado el parámetro how=”all” en la función dropna(), lo que significa que si hay todas las filas o columnas que tienen todos los valores nulos, estamos eliminando esa fila o columna en particular del marco de datos.
Python
# if any row having all Null # values we are dropping that # rows. df = df.dropna(how="all") df.show()
Producción:
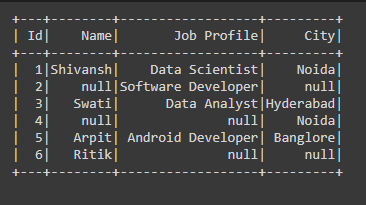
Ejemplo 3: limpieza de datos con dropna utilizando el parámetro de umbral en PySpark.
En el siguiente código, hemos pasado el parámetro thresh =2 en la función dropna(), lo que significa que si hay filas o columnas que tienen menos valores que no son NULL que los valores de umbral, estamos eliminando esa fila o columna de el marco de datos.
Python
# if thresh value is not # satisfied then dropping # that row df = df.dropna(thresh=2) df.show()
Producción:
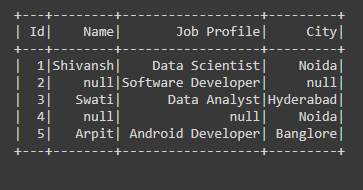
Ejemplo 4: limpieza de datos con dropna usando el parámetro de subconjunto en PySpark.
En el siguiente código, hemos pasado el parámetro subset=’City’ en la función dropna(), que es el nombre de la columna respectiva de la columna City, si alguno de los valores NULL está presente en esa columna, estamos eliminando esa fila del Dataframe. .
Python
# if the subset column any value # is NULL then dropping that row df = df.dropna(subset="City") df.show()
Producción:
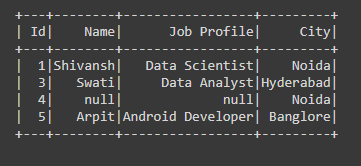
Ejemplo 5: Limpieza de datos con dropna usando umbral y parámetro de subconjunto en PySpark.
En el siguiente código, hemos pasado el parámetro (umbral =2, subconjunto=(“Id”,”Nombre”,”Ciudad”)) en la función dropna(), por lo que los valores NULL caerán cuando el umbral=2 y el subconjunto = («Id», «Nombre», «Ciudad») estas dos condiciones se cumplirán significa que entre estas tres columnas, la función dropna verifica si thresh = 2 también es satisfactoria o no, si se cumple, entonces suelte esa fila o columna en particular.
Python
# if thresh value is satisfied with subset
# column then dropping that row
df = df.dropna(thresh=2,subset=("Id","Name","City"))
df.show()
Producción:
Publicación traducida automáticamente
Artículo escrito por srishivansh5404 y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA