El comando de localización en Linux se usa para encontrar los archivos por nombre. Las dos utilidades de búsqueda de archivos más utilizadas a las que pueden acceder los usuarios se denominan buscar y localizar . La utilidad de localización funciona mejor y más rápido que la contraparte del comando de búsqueda porque en lugar de buscar en el sistema de archivos cuando se inicia una búsqueda de archivos, buscaría a través de una base de datos. Esta base de datos contiene fragmentos y partes de archivos y sus rutas correspondientes en su sistema. De forma predeterminada, el comando de localización no comprueba si los archivos encontrados en la base de datos aún existen y nunca informa sobre los archivos creados después de la actualización más reciente de la base de datos relevante.
Sintaxis:
locate [OPTION]... PATTERN...
Estado de salida: este comando saldrá con el estado 0 si se encuentra alguna coincidencia especificada. Si no se encuentra ninguna coincidencia o se encuentra un error fatal, se cerrará con el estado 1.
Opciones:
- -b, –basename : hace coincidir solo el nombre base con los patrones especificados, que es lo opuesto a –wholename .
- -c, –count : en lugar de escribir nombres de archivo en la salida estándar, escriba solo el número de entradas coincidentes.
- -d, –database DBPATH : reemplaza la base de datos predeterminada con DBPATH. DBPATH es una
: (colon)lista separada de nombres de archivos de bases de datos. Si se especifica más de una opción de base de datos , la ruta resultante es una concatenación de rutas separadas. Un nombre de archivo de base de datos vacío se reemplaza por la base de datos predeterminada. Un nombre de archivo de base de datos: se refiere a la entrada estándar. Tenga en cuenta que una base de datos se puede leer desde la entrada estándar solo una vez. - -e, –existing : imprime solo las entradas que hacen referencia a los archivos existentes en el momento en que se ejecuta la localización.
- -L, –follow: al comprobar si existen archivos (si se especifica la opción –existente ), siga los enlaces simbólicos finales. Esto hace que los enlaces simbólicos rotos se omitan de la salida. Esta opción es el comportamiento predeterminado. Se puede especificar lo contrario usando –nofollow .
- -h, –help: escriba un resumen de las opciones disponibles en la salida estándar y salga correctamente.
- -i, –ignore-case : ignora las distinciones de mayúsculas y minúsculas al hacer coincidir patrones.
- -l, –limit, -n LIMIT: Salir con éxito después de encontrar LIMIT entradas. Si se especifica la opción –count , el recuento resultante también se limita a LIMIT.
- -m, –mmap : Ignorado, pero incluido por compatibilidad con BSD y GNU localizar.
- -P, –nofollow, -H : Al verificar si existen archivos (si se especifica la opción –existente ), no siga los enlaces simbólicos finales. Esto hace que los enlaces simbólicos rotos se notifiquen como otros archivos.
Esta opción es lo opuesto a –follow .
- -0, –null: separe las entradas en la salida usando el carácter ASCII NUL en lugar de escribir cada entrada en una línea separada. Esta opción está diseñada para la interoperabilidad con la opción –null de GNU xargs.
- -S, –statistics: escribe estadísticas sobre cada base de datos leída en la salida estándar en lugar de buscar archivos y salir correctamente.
- -q, –quiet: no escribe mensajes sobre errores encontrados al leer y procesar bases de datos.
- -r, –regexp REGEXP: busca una expresión regular básica REGEXP. No se permiten PATRONES si se usa esta opción, pero esta opción se puede especificar varias veces.
- –regex : Interpreta todos los PATRONES como expresiones regulares extendidas.
- -s, –stdio : Ignorado, por compatibilidad con BSD y GNU.
- -V, –version: escriba información sobre la versión y la licencia de la ubicación en la salida estándar y salga correctamente.
- -w, –wholename: coincide solo con el nombre completo de la ruta con los patrones especificados. Esta opción es el comportamiento predeterminado. Se puede especificar lo contrario usando –basename .
Ejemplo 1: Buscar un archivo con un nombre específico.
$ locate sample.txt
Buscará sample.txt en un directorio en particular.
Producción:

Ejemplo 2: limitar las consultas de búsqueda a un número específico.
$ locate "*.html" -n 20
Mostrará 20 resultados para la búsqueda de archivos que terminen en .html .
Producción:

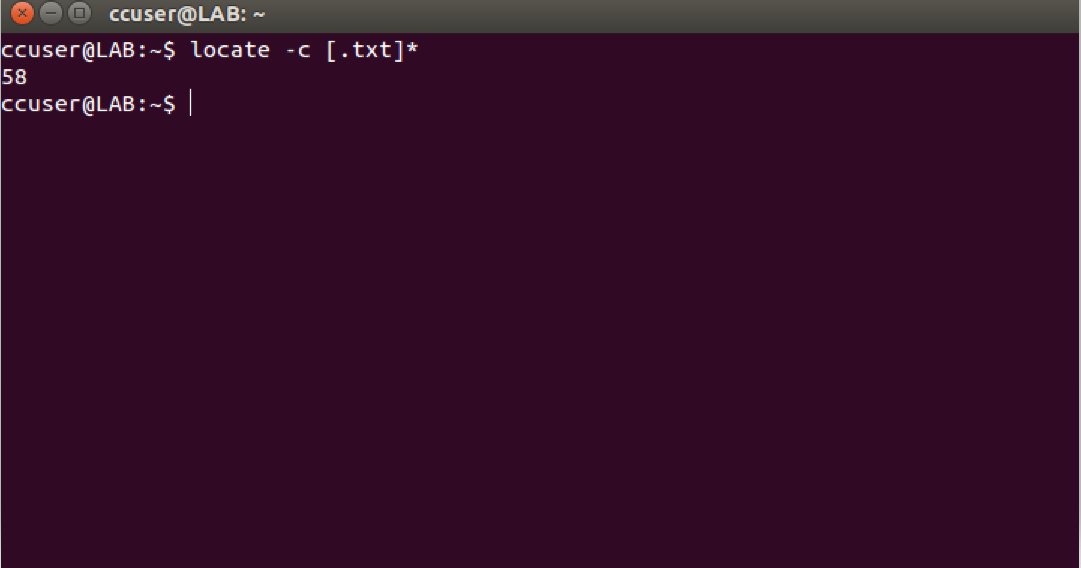
Ejemplo 3. Mostrar el número de entradas coincidentes.
$ locate -c [.txt]*
Contará los archivos que terminen en .txt .
Producción:
Ejemplo 4: Ignorar las salidas de localización que distinguen entre mayúsculas y minúsculas. Este comando está configurado para procesar consultas distinguiendo entre mayúsculas y minúsculas. Significa que SAMPLE.TXT mostrará un resultado diferente al de sample.txt .
$ locate -i *SAMPLE.txt*
Producción:

Ejemplo 5: entradas de salida separadas sin nueva línea.
$ locate -i -0 *sample.txt*
El separador predeterminado para el comando de localización es el carácter de nueva línea (\\n). Pero si alguien quiere usar un separador diferente como ASCII NUL, puede hacerlo usando la opción de línea de comando -0 .
Producción:

Publicación traducida automáticamente
Artículo escrito por Pragya_Chaurasia y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA