LOOCV (Leave One Out Cross-Validation) es un tipo de enfoque de validación cruzada en el que cada observación se considera como el conjunto de validación y el resto (N-1) observaciones se consideran como el conjunto de entrenamiento. En LOOCV, el ajuste del modelo se realiza y se predice utilizando un conjunto de validación de observación. Además, repetir esto N veces para cada observación como conjunto de validación. El modelo se ajusta y el modelo se utiliza para predecir un valor para la observación. Este es un caso especial de validación cruzada K-fold en el que el número de pliegues es el mismo que el número de observaciones (K = N). Este método ayuda a reducir el sesgo y la aleatoriedad.El método tiene como objetivo reducir la tasa de error cuadrático medio y evitar el sobreajuste. Es muy fácil realizar LOOCV en programación R.
Expresión Matemática
LOOCV implica un pliegue por observación, es decir, cada observación por sí misma desempeña el papel del conjunto de validación. Las observaciones (N-1) juegan el papel del conjunto de entrenamiento. Con mínimos cuadrados lineales, el costo de rendimiento de un solo modelo es el mismo que el de un solo modelo. En LOOCV, se puede evitar el reajuste del modelo mientras se implementa el método LOOCV. El MSE (error cuadrático medio) se calcula ajustando el conjunto de datos completo.
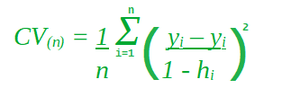
En la fórmula anterior, h i representa cuánta influencia tiene una observación en su propio ajuste, es decir, entre 0 y 1 que castiga el residuo, ya que se divide por un número pequeño. Infla el residual.
Implementación en R
El conjunto de datos:
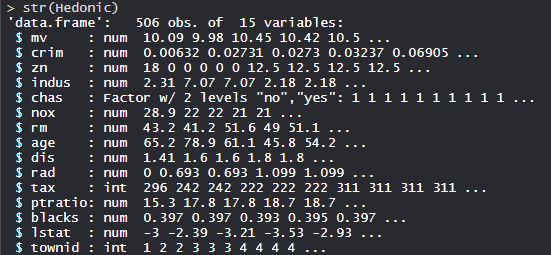
The Hedonic es un conjunto de datos de precios de Census Tracts en Boston. Comprende las tasas de criminalidad, la proporción de lotes residenciales de 25,000 pies cuadrados, el número promedio de habitaciones, la proporción de unidades de propietarios construidas antes de 1940, etc. de un total de 15 aspectos. Viene preinstalado con el paquete Eclat en R.
R
# Installing the package
install.packages("Ecdat")
# Loading package
library(Ecdat)
# Structure of dataset in package
str(Hedonic)
Producción:
Realización de la validación cruzada Leave One Out (LOOCV) en el conjunto de datos:
Usar la validación cruzada Leave One Out (LOOCV) en el conjunto de datos entrenando el modelo usando características o variables en el conjunto de datos.
R
# Installing Packages
install.packages("Ecdat")
install.packages("boot")
install.packages("dplyr")
install.packages("ggplot2")
install.packages("caret")
# Loading the packages
library(Ecdat)
library(boot)
library(dplyr)
library(ggplot2)
library(caret)
# Model Building
age.glm <- glm(age ~ mv + crim + zn + indus
+ chas + nox + rm + tax + dis
+ rad + ptratio + blacks + lstat,
data = Hedonic)
age.glm
# Mean Squared Error
cv.mse <- cv.glm(Hedonic, age.glm)
cv.mse$delta
# Generating error of
# Different models
cv.mse = rep(0,5)
for (i in 1:5)
{
age.loocv <- glm(age ~ mv + poly(crim, i)
+ zn + indus + chas + nox
+ rm + poly(tax, i) + dis
+ rad + ptratio + blacks
+ lstat, data = Hedonic)
cv.mse[i] = cv.glm(Hedonic, age.loocv)$delta[1]
}
cv.mse
Producción:
- Edad del modelo.glm:
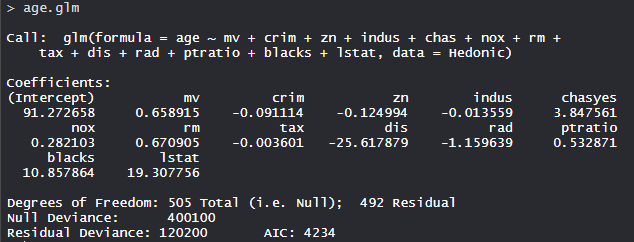
El modelo age.glm tiene 505 grados de libertad con una desviación nula de 400100 y una desviación residual de 120200. El AIC es 4234.
- Error medio cuadrado:

El primer error 250.2985 es el error cuadrático medio (MSE) para el conjunto de entrenamiento y el segundo error 250.2856 es para la validación cruzada Leave One Out (LOOCV). Los números de salida generados son casi iguales.
- Errores de diferentes modelos:

El error aumenta continuamente. Esto establece que los polinomios de alto orden no son beneficiosos en el caso general.
Las ventajas de LOOCV son las siguientes:
- No tiene aleatoriedad en el uso de algunas observaciones para el entrenamiento frente al conjunto de validación. En el método de conjunto de validación, cada observación se considera tanto para el entrenamiento como para la validación, por lo que tiene menos variabilidad debido a que no es aleatoria, sin importar cuántas veces se ejecute.
- Tiene menos sesgo que el método del conjunto de validación, ya que el conjunto de entrenamiento tiene un tamaño n-1. En todo el conjunto de datos. Como resultado, hay una sobreestimación reducida del error de prueba en comparación con el método del conjunto de validación.
La desventaja de LOOCV es la siguiente:
- Entrenar el modelo N veces conduce a un tiempo de cálculo costoso si el conjunto de datos es grande.