Las tareas del proceso de manejo de errores son detectar cada error, informarlo al usuario y luego hacer alguna estrategia de recuperación e implementarla para manejar el error. Durante todo este proceso, el tiempo de procesamiento del programa no debe ser lento.
Funciones del controlador de errores:
- Detección de errores
- Reporte de error
- Error de recuperación
Error handler=Error Detection+Error Report+Error Recovery.
Un error son las entradas en blanco en la tabla de símbolos.
Los errores en el programa deben ser detectados e informados por el analizador. Cada vez que ocurre un error, el analizador puede manejarlo y continuar analizando el resto de la entrada. Aunque el analizador es principalmente responsable de verificar errores, pueden ocurrir errores en varias etapas del proceso de compilación.
Entonces, hay muchos tipos de errores y algunos de estos son:
Tipos o fuentes de error: hay tres tipos de error: error lógico, de tiempo de ejecución y de tiempo de compilación:
- Los errores lógicos ocurren cuando los programas funcionan incorrectamente pero no terminan de manera anormal (o fallan). Las salidas inesperadas o no deseadas u otro comportamiento pueden resultar de un error lógico, incluso si no se reconoce inmediatamente como tal.
- Un error de tiempo de ejecución es un error que ocurre durante la ejecución de un programa y generalmente ocurre debido a parámetros de sistema adversos o datos de entrada no válidos. La falta de memoria suficiente para ejecutar una aplicación o un conflicto de memoria con otro programa y error lógico es un ejemplo de esto. Los errores lógicos ocurren cuando el código ejecutado no produce el resultado esperado. Los errores lógicos se manejan mejor mediante una depuración meticulosa del programa.
- Los errores en tiempo de compilación aumentan en tiempo de compilación, antes de la ejecución del programa. Un error de sintaxis o una referencia de archivo faltante que impide que el programa se compile correctamente es un ejemplo de esto.
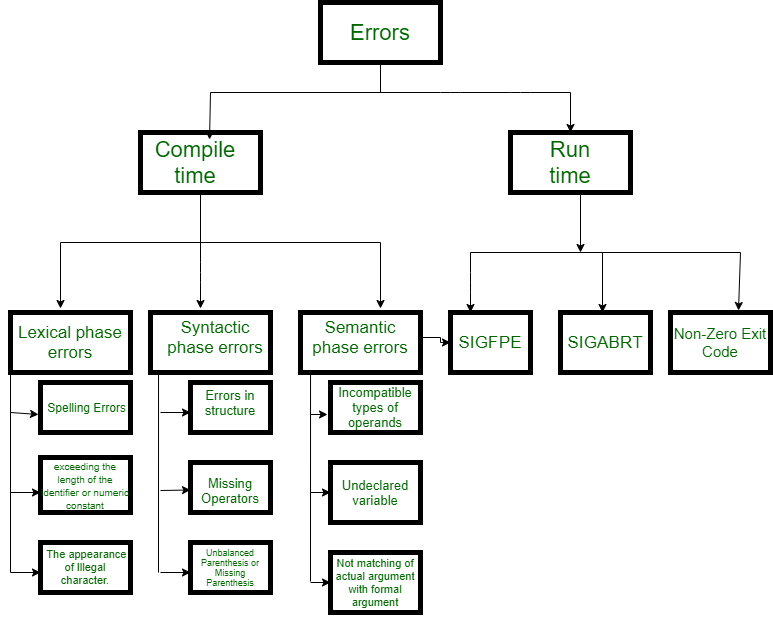
Clasificación del error de tiempo de compilación –
- Léxico : esto incluye errores ortográficos de identificadores, palabras clave u operadores
- Sintáctico : falta un punto y coma o un paréntesis desequilibrado
- Semántica : asignación de valor incompatible o desajustes de tipo entre operador y operando
- Lógico : código no accesible, bucle infinito.
Encontrar un error o informar un error: Viable-prefix es la propiedad de un analizador que permite la detección temprana de errores de sintaxis.
- Meta la detección de un error lo antes posible sin consumir más entradas innecesarias
- Cómo: detectar un error tan pronto como el prefijo de la entrada no coincida con un prefijo de cualquier string en el idioma.
Ejemplo: for( ; ), esto reportará un error por tener dos puntos y comas dentro de llaves.
Recuperación de errores:
el requisito básico para el compilador es simplemente detenerse y emitir un mensaje y detener la compilación. Hay algunos métodos de recuperación comunes que son los siguientes.
Ya discutimos los errores. Ahora, intentemos entender la recuperación de errores en cada fase del compilador.
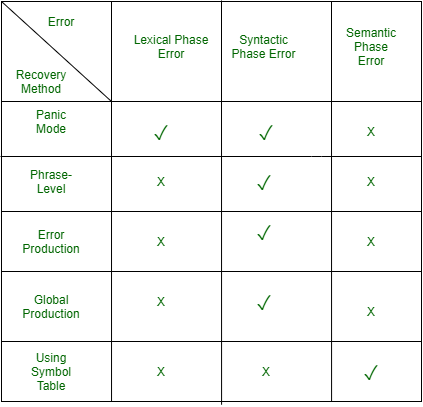
1. Recuperación en modo de pánico:
esta es la forma más fácil de recuperación de errores y también evita que el analizador desarrolle bucles infinitos mientras recupera errores. El analizador descarta el símbolo de entrada uno a la vez hasta que se encuentra uno de los conjuntos designados (como final, punto y coma) de tokens de sincronización (que suelen ser los terminadores de declaración o expresión). Esto es adecuado cuando la presencia de múltiples errores en la misma declaración es rara. Ejemplo: Considere la expresión errónea- (1 + + 2) + 3. Recuperación en modo de pánico: salte al siguiente número entero y luego continúe. Bison: use el error de terminal especial para describir cuánta entrada omitir.
E->int|E+E|(E)|error int|(error)
2. Recuperación de nivel de fase:
cuando se descubre un error, el analizador realiza una corrección local en la entrada restante. Si un analizador encuentra un error, realiza las correcciones necesarias en la entrada restante para que el analizador pueda continuar analizando el resto de la declaración. Puede corregir el error eliminando los puntos y comas adicionales, reemplazando las comas por puntos y comas o reintroduciendo los puntos y comas que faltan. Para evitar entrar en un bucle infinito durante la corrección, se debe tener sumo cuidado. Cada vez que se encuentra un prefijo en la entrada restante, se reemplaza con alguna string. De esta forma, el analizador puede seguir operando en su ejecución.
3. Producción de errores:
se puede incorporar el uso del método de producción de errores si el usuario es consciente de los errores comunes que se encuentran en la gramática junto con los errores que producen construcciones erróneas. Cuando se utiliza, se pueden generar mensajes de error durante el proceso de análisis y el análisis puede continuar. Ejemplo: escriba 5x en lugar de 5*x
4. Corrección global:
para recuperarse de una entrada errónea, el analizador analiza todo el programa e intenta encontrar la coincidencia más cercana, que no tenga errores. La coincidencia más cercana es aquella que no hace muchas inserciones, eliminaciones y cambios de tokens. Este método no es práctico debido a su alta complejidad temporal y espacial.
Siguiente artículo relacionado – Detección de errores y recuperación en el compilador
Publicación traducida automáticamente
Artículo escrito por Pragati_Agrawal y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA