La manipulación de strings es el proceso de cambiar, analizar, empalmar, pegar o analizar strings. Como sabemos, a veces, los datos en la string no son adecuados para manipular el análisis u obtener una descripción de los datos. Pero Python es conocido por su capacidad para manipular strings. Entonces, al extenderlo aquí, conoceremos cómo Pandas nos brinda las formas de manipular para modificar y procesar el marco de datos de string usando algunas funciones integradas. La biblioteca de Pandas tiene algunas de las funciones integradas que a menudo se usan para manipular strings de marcos de datos
En primer lugar, conoceremos formas de crear un marco de datos de string usando pandas:
Python3
# Importing the necessary libraries import pandas as pd import numpy as np # df stands for dataframe df = pd.Series(['Gulshan', 'Shashank', 'Bablu', 'Abhishek', 'Anand', np.nan, 'Pratap']) print(df)
Producción:

Cambiemos el tipo del marco de datos creado anteriormente al tipo de string. Puede haber varios métodos para hacer lo mismo. Echemos un vistazo a ellos en los siguientes ejemplos.
Ejemplo 1: podemos cambiar el tipo de d después de la creación del marco de datos:
Python3
# we can change the dtype after
# creation of dataframe
print(df.astype('string'))
Producción:

Ejemplo 2: Crear el dataframe como dtype = ‘string’:
Python3
# now creating the dataframe as dtype = 'string' import pandas as pd import numpy as np df = pd.Series(['Gulshan', 'Shashank', 'Bablu', 'Abhishek', 'Anand', np.nan, 'Pratap'], dtype='string') print(df)
Producción:
Ejemplo 3: Crear el dataframe como dtype = pd.StringDtype():
Python3
# now creating the dataframe as dtype = pd.StringDtype() import pandas as pd import numpy as np df = pd.Series(['Gulshan', 'Shashank', 'Bablu', 'Abhishek', 'Anand', np.nan, 'Pratap'], dtype=pd.StringDtype()) print(df)
Producción:
Manipulaciones de strings en Pandas
Ahora, vemos las manipulaciones de strings dentro de un marco de datos de pandas, así que primero, cree un marco de datos y manipule todas las operaciones de strings en este único marco de datos a continuación, para que todos puedan conocerlo fácilmente.
Ejemplo:
Python3
# python script for create a dataframe # for string manipulations import pandas as pd import numpy as np df = pd.Series(['night_fury1', 'Is ', 'Geeks, forgeeks', '100', np.nan, ' Contributor ']) df
Producción:
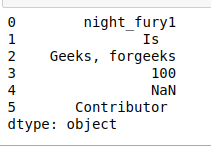
Echemos un vistazo a varios métodos proporcionados por esta biblioteca para la manipulación de strings.
- lower(): Convierte todos los caracteres en mayúsculas en strings en el DataFrame a minúsculas y devuelve las strings en minúsculas en el resultado.
Python3
# lower() print(df.str.lower())
0 night_fury1 1 is 2 geeks, forgeeks 3 100 4 NaN 5 contributor dtype: object
- upper(): Convierte todos los caracteres en minúsculas en strings en el DataFrame a mayúsculas y devuelve las strings en mayúsculas como resultado.
Python3
#upper() print(df.str.upper())
Producción:
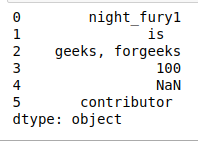
- strip(): si hay espacios al principio o al final de una string, debemos recortar las strings para eliminar los espacios usando strip() o eliminar los espacios adicionales que contiene una string en DataFrame.
Python3
# strip()
print(df)
print('\nAfter using the strip:')
print(df.str.strip())
Producción:

- split(‘ ‘): Divide cada string con el patrón dado. Las strings se dividen y los nuevos elementos después de la operación de división realizada se almacenan en una lista.
Python3
# split(pattern)
print(df)
print('\nAfter using the strip:')
print(df.str.split(','))
# now we can use [] or get() to fetch
# the index values
print('\nusing []:')
print(df.str.split(',').str[0])
print('\nusing get():')
print(df.str.split(',').str.get(1))
Producción:


- len(): con la ayuda de len() podemos calcular la longitud de cada string en DataFrame y si hay datos vacíos en DataFrame, devuelve NaN.
Python3
# len()
print("length of the dataframe: ", len(df))
print("length of each value of dataframe:")
print(df.str.len())
Producción:
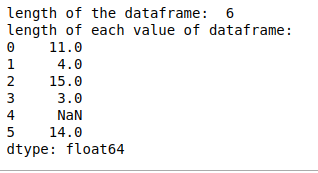
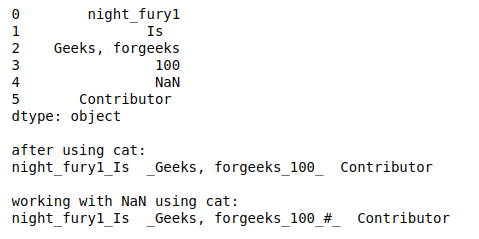
- cat(sep=’ ‘): Concatena los elementos del índice del marco de datos o cada string en DataFrame con el separador dado.
Python3
# cat(sep=pattern)
print(df)
print("\nafter using cat:")
print(df.str.cat(sep='_'))
print("\nworking with NaN using cat:")
print(df.str.cat(sep='_', na_rep='#'))
Producción:
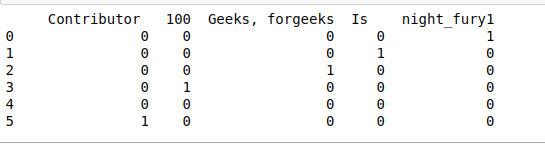
- get_dummies(): Devuelve el DataFrame con valores One-Hot Encoded como podemos ver que devuelve el valor booleano 1 si existe en el índice relativo o 0 si no existe.
Python3
# get_dummies() print(df.str.get_dummies())
Producción:
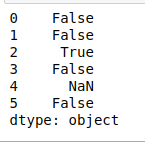
- comienza con (patrón): devuelve verdadero si el elemento o la string en el índice de trama de datos comienza con el patrón.
Python3
# startswith(pattern)
print(df.str.startswith('G'))
Producción:
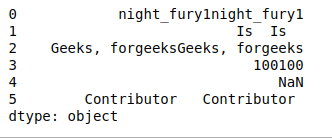
- termina con (patrón): devuelve verdadero si el elemento o la string en el Índice de DataFrame termina con el patrón.
Python3
# endswith(pattern)
print(df.str.endswith('1'))
Producción:

- replace(a,b): reemplaza el valor a con el valor b como se muestra a continuación en el ejemplo, ‘Geeks’ está siendo reemplazado por ‘Gulshan’.
Python3
# replace(a,b)
print(df)
print("\nAfter using replace:")
print(df.str.replace('Geeks', 'Gulshan'))
Producción:

- repetir (valor): repite cada elemento con un número determinado de veces como se muestra a continuación en el ejemplo, hay dos apariencias de cada string en DataFrame.
Python3
# repeat(value) print(df.str.repeat(2))
Producción:
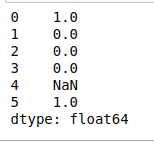
- count (patrón): devuelve el recuento de la aparición del patrón en cada elemento en Data-Frame como se muestra a continuación en el ejemplo, cuenta ‘n’ en cada string de DataFrame y devuelve el recuento total de ‘n’ en cada string.
Python3
# count(pattern)
print(df.str.count('n'))
Producción:
- find(pattern): Devuelve la primera posición de la primera aparición del patrón. Podemos ver en el ejemplo a continuación, que devuelve el valor de índice de aparición del carácter ‘n’ en cada string a lo largo del DataFrame.
Python3
# find(pattern)
# in result '-1' indicates there is no
# value matching with given pattern in
# particular row
print(df.str.find('n'))
Producción:

- findall(patrón): Devuelve una lista de todas las ocurrencias del patrón. Como podemos ver a continuación, hay una lista devuelta que consiste en n, ya que aparece solo una vez en la string.
Python3
# findall(pattern)
# in result [] indicates null list as
# there is no value matching with given
# pattern in particular row
print(df.str.findall('n'))
Producción:
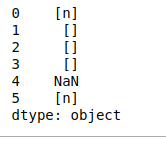
- islower(): comprueba si todos los caracteres de cada string del índice del marco de datos están en minúsculas o no, y devuelve un valor booleano.
Python3
# islower() print(df.str.islower())
Producción:
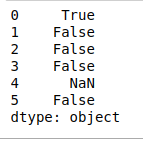
- isupper(): Comprueba si todos los caracteres de cada string en el índice del marco de datos están en mayúsculas o no, y devuelve un valor booleano.
Python3
# isupper() print(df.str.isupper())
Producción:

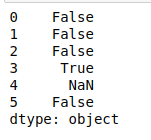
- isnumeric(): comprueba si todos los caracteres de cada string del índice del marco de datos son numéricos o no, y devuelve un valor booleano.
Python3
# isnumeric() print(df.str.isnumeric())
Producción:
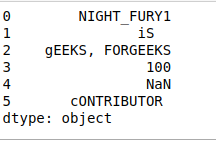
- swapcase(): Cambia de mayúsculas a minúsculas y viceversa. Como en el ejemplo siguiente, convierte todos los caracteres en mayúsculas de cada string en minúsculas y viceversa (minúsculas -> mayúsculas).
Python3
# swapcase() print(df.str.swapcase())
Producción:
Publicación traducida automáticamente
Artículo escrito por night_fury1 y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA