Antes de manipular el marco de datos con pandas, debemos comprender qué es la manipulación de datos. Los datos en el mundo real son muy desagradables y desordenados, por lo que al realizar ciertas operaciones podemos hacer que los datos sean comprensibles según los requisitos de uno, este proceso de convertir datos desordenados en información significativa se puede realizar mediante la manipulación de datos.
Aquí, aprenderemos cómo manipular marcos de datos con pandas. Pandas es una biblioteca de código abierto que se utiliza desde la manipulación de datos hasta el análisis de datos y es una herramienta muy poderosa, flexible y fácil de usar que se puede importar usando importar pandas como pd. Los pandas tratan esencialmente con datos en arrays 1-D y 2-D; Aunque, los pandas manejan estos dos de manera diferente. En pandas, las arrays 1-D se expresan como una serie y un marco de datos es simplemente una array 2-D. El conjunto de datos utilizado aquí es country_code.csv .
A continuación se muestran varias operaciones utilizadas para manipular el marco de datos:
- Primero, importe la biblioteca que se utiliza en la manipulación de datos, es decir, pandas, luego asigne y lea el marco de datos:
Python3
# import module
import pandas as pd
# assign dataset
df = pd.read_csv("country_code.csv")
# display
print("Type-", type(df))
df
Producción:
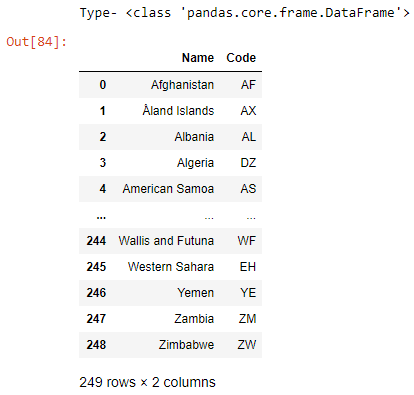
- Podemos leer el marco de datos usando la función head() también que tiene un argumento (n), es decir, el número de filas que se mostrarán.
Python3
df.head(10)
Producción:
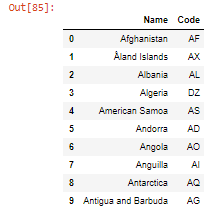
- Contando las filas y columnas en DataFrame usando shape(). Devuelve el nro. de filas y columnas encerradas en una tupla.
Python3
df.shape
Producción:
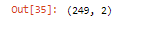
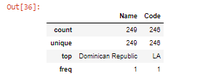
- Resumen de estadísticas de DataFrame usando el método describe() .
Python3
df.describe()
Producción:
- Al eliminar los valores faltantes en DataFrame, se puede hacer usando el método dropna() , elimina todos los valores NaN en el marco de datos.
Python3
df.dropna()
Producción:
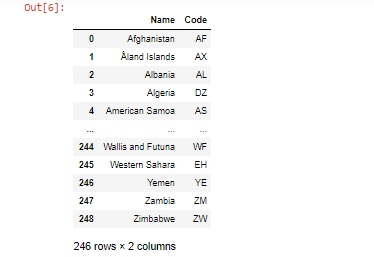
Otro ejemplo es:
Python3
df.dropna(axis=1)
Esto eliminará todas las columnas con valores faltantes.
Producción:
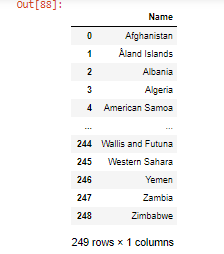
- Fusionando DataFrames usando merge() , los argumentos pasados son los dataframes que se fusionarán junto con el nombre de la columna.
Python3
df1 = pd.read_csv("country_code.csv")
merged_col = pd.merge(df, df1, on='Name')
merged_col
Producción:
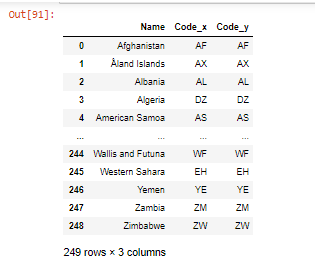
- Un argumento adicional ‘on’ es el nombre de la columna común, aquí ‘Nombre’ es la columna común dada a la función merge(). df es el primer marco de datos y df1 es el segundo marco de datos que se fusionará.
- Al cambiar el nombre de las columnas del marco de datos usando rename() , los argumentos pasados son las columnas que se cambiarán de nombre y en su lugar.
Python3
country_code = df.rename(columns={'Name': 'CountryName',
'Code': 'CountryCode'},
inplace=False)
country_code
Producción:
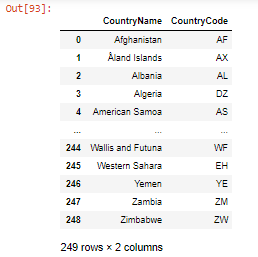
El código ‘inplace = False’ significa que el resultado se almacenaría en un nuevo DataFrame en lugar del original.
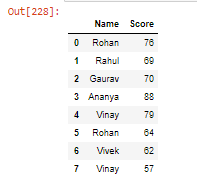
- Creando un marco de datos manualmente:
Python3
student = pd.DataFrame({'Name': ['Rohan', 'Rahul', 'Gaurav',
'Ananya', 'Vinay', 'Rohan',
'Vivek', 'Vinay'],
'Score': [76, 69, 70, 88, 79, 64, 62, 57]})
# Reading Dataframe
student
Producción:
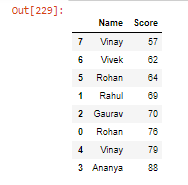
- Ordenar el DataFrame usando el método sort_values() .
Python3
student.sort_values(by=['Score'], ascending=True)
Producción:
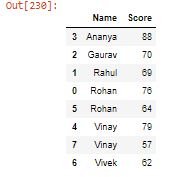
- Ordenar el DataFrame usando varias columnas:
Python3
student.sort_values(by=['Name', 'Score'], ascending=[True, False])
Producción:
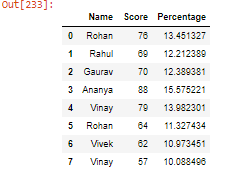
- Al crear otra columna en DataFrame, aquí crearemos un porcentaje de nombre de columna que calculará el porcentaje de la puntuación del estudiante mediante el uso de la función agregada sum().
Python3
student['Percentage'] = (student['Score'] / student['Score'].sum()) * 100 student
Producción:
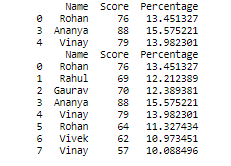
- Seleccionar filas de DataFrame usando operadores lógicos:
Python3
# Selecting rows where score is # greater than 70 print(student[student.Score>70]) # Selecting rows where score is greater than 60 # OR less than 70 print(student[(student.Score>60) | (student.Score<70)])
Producción:
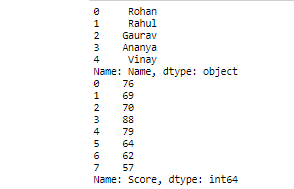
- Indexación y corte:
Aquí .loc es la base de la etiqueta y .iloc son los métodos basados en posiciones enteras que se utilizan para dividir e indexar datos.
Python3
# Printing five rows with name column only # i.e. printing first 5 student names. print(student.loc[0:4, 'Name']) # Printing all the rows with score column # only i.e. printing score of all the # students print(student.loc[:, 'Score']) # Printing only first rows having name, # score columns i.e. print first student # name & their score. print(student.iloc[0, 0:2]) # Printing first 3 rows having name,score & # percentage columns i.e. printing first three # student name,score & percentage. print(student.iloc[0:3, 0:3]) # Printing all rows having name & score # columns i.e. printing all student # name & their score. print(student.iloc[:, 0:2])
Producción:
.loc:
.iloc:
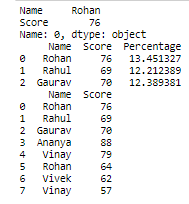
- Aplicar funciones, esta función se usa para aplicar una función a lo largo de un eje de marco de datos, ya sea fila (eje = 0) o columna (eje = 1).
Python3
# explicit function def double(a): return 2*a student['Score'] = student['Score'].apply(double) # Reading Dataframe student
Producción:
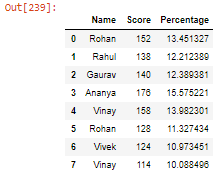
Publicación traducida automáticamente
Artículo escrito por prachisharma1320 y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA