MapReduce es un modelo de programación que se utiliza para realizar el procesamiento distribuido en paralelo en un clúster de Hadoop, lo que hace que Hadoop funcione tan rápido. Cuando se trata de Big Data, el procesamiento en serie ya no sirve de nada. MapReduce tiene principalmente dos tareas que se dividen en fases:
- Tarea de mapa
- Reducir tarea
Entendámoslo con un ejemplo en tiempo real, y el ejemplo lo ayudará a comprender el modelo de programación de Mapreduce de una manera narrativa:
- Suponga que el gobierno indio le ha asignado la tarea de contar la población de India. Puedes exigir todos los recursos que quieras, pero tienes que hacer esta tarea en 4 meses. Calcular la población de un país tan grande no es tarea fácil para una sola persona (tú). Entonces, ¿cuál será su enfoque?.
- Una de las formas de resolver este problema es dividir el país por estados y asignar individuos a cargo de cada estado para contar la población de ese estado.
- Tarea de cada individuo: cada individuo debe visitar todos los hogares presentes en el estado y debe llevar un registro de los miembros de cada casa como:
State_Name Member_House1 State_Name Member_House2 State_Name Member_House3 . . State_Name Member_House n . .
- Una vez que hayan contado a cada integrante de la casa en su respectivo estado. Ahora necesitan resumir sus resultados y enviarlos a la sede en Nueva Delhi.
- Tenemos un oficial capacitado en la sede para recibir todos los resultados de cada estado y agregarlos por cada estado para obtener la población de todo ese estado. y Ahora, con este enfoque, puede contar fácilmente la población de la India sumando los resultados obtenidos en la sede.
- El gobierno indio está contento con su trabajo y al año siguiente le pidieron que hiciera el mismo trabajo en 2 meses en lugar de 4 meses. Nuevamente se le proporcionarán todos los recursos que desee.
- Desde el Gob. le ha proporcionado todos los recursos, simplemente duplicará el número de encargados individuales asignados para cada estado de uno a dos. Para eso, divida cada estado en 2 divisiones y asigne diferentes encargados para estas dos divisiones como:
State_Name_Incharge_division1 State_Name_Incharge_division2
- Asimismo, cada responsable de su división reunirá la información de los miembros de cada casa y llevará su registro.
- También podemos hacer lo mismo en el cuartel general, así que también dividamos el cuartel general en dos divisiones como:
Head-qurter_Division1 Head-qurter_Division2
- Ahora, con este enfoque, puede encontrar la población de la India en dos meses. Pero hay un pequeño problema con esto, nunca queremos que las divisiones del mismo estado envíen su resultado a diferentes Sedes, entonces, en ese caso, tenemos la población parcial de ese estado en Sede_División1 y Sede_División2 que es inconsistente porque queremos la población consolidada por el estado, no el conteo parcial.
- Una forma sencilla de resolverlo es que podemos indicar a todas las personas de un estado que envíen el resultado a Head-quarter_Division1 o Head- Quarter_Division2. Del mismo modo, para todos los estados.
- Nuestro problema ha sido resuelto, y lo hiciste con éxito en dos meses.
- Ahora bien, si te piden que hagas este proceso en un mes, ya sabes cómo abordar la solución.
- Genial, ahora tenemos un buen modelo escalable que funciona muy bien. El modelo que hemos visto en este ejemplo es como el modelo de programación de MapReduce. así que ahora debe tener en cuenta que MapReduce es un modelo de programación, no un lenguaje de programación.
Por simplicidad, hemos tomado solo tres estados.

Este es un enfoque simple de divide y vencerás y será seguido por cada individuo para contar a las personas en su estado.
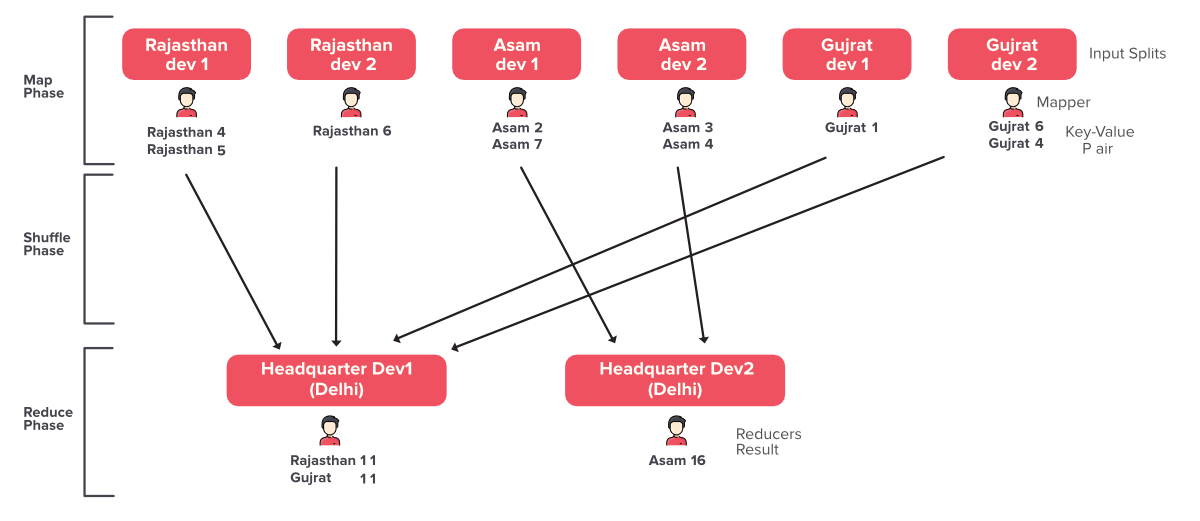
Ahora analicemos las fases y las cosas importantes involucradas en nuestro modelo.
1. Fase de Mapa: La Fase en la que los encargados individuales recopilan la población de cada casa en su división es la Fase de Mapa.
- Mapeador: Individuo involucrado en el cálculo de la población
- Divisiones de entrada: el estado o la división del estado
- Par clave-valor: salida de cada mapeador individual como si la clave fuera Rajasthan y el valor fuera 2
2. Fase de reducción: la fase en la que está agregando su resultado
- Reductores: Individuos que están agregando el resultado real. Aquí en nuestro ejemplo, los oficiales entrenados. Cada Reducer produce la salida como un par clave-valor
3. Fase aleatoria: la fase en la que se copian los datos de Mappers a Reducers es la fase Shuffler. Se encuentra entre la fase Mapa y Reduce. Ahora la fase de mapa, la fase de reducción y la fase de barajado son las tres fases principales de nuestro Mapreduce.
Publicación traducida automáticamente
Artículo escrito por dikshantmalidev y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA