En este artículo, aprenderemos sobre el mecanismo de alta disponibilidad en Cassandra utilizando la siguiente terminología clave.
1. Seed Node 2. Gossip Communication Protocol 3. Failure Detection 4. Hinted Handoff
vamos a discutir uno por uno.
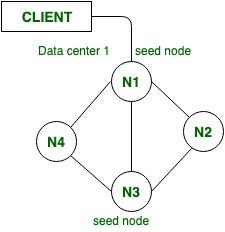
1. Node semilla:
en Apache Cassandra, son los primeros Nodes que se inician en el clúster. Si queremos configurar el Node semilla, entonces podemos configurarlo en el archivo Cassandra.yaml, que es el archivo principal en Cassandra para cambiar cualquier ajuste de configuración. El Node semilla ayuda en Bootstrapping para nuevos Nodes que se unen al clúster en Cassandra.
El Node semilla también es útil para proporcionar información sobre otro Node. Cuando un nuevo Node se conecta, chismeará sobre el Node semilla para obtener información sobre los otros Nodes en el clúster.
Secuencia de inicio:
En Cassandra, la secuencia de inicio juega un papel importante. La secuencia de inicio proporciona la secuencia inicial, por lo tanto, inicie los Nodes semilla uno por uno y luego los otros Nodes.
Práctica recomendada: en Cassandra, siempre es una buena práctica establecer más de un Node semilla por centro de datos en un clúster.
Dirección del oyente y puerto de almacenamiento:
en la comunicación entre Nodes, usamos la dirección del oyente y el puerto de almacenamiento para la comunicación en Cassandra. El ID de puerto predeterminado para Cassandra es 7000. En Cassandra, el ID de puerto debe ser el mismo para todos los Nodes del clúster.
listener_address= ip address of node storage_port = 7000 (by default)
2. Protocolo de comunicación de chismes:
en Cassandra, los Nodes intercambian periódicamente (cada segundo) información de estado (por ejemplo, vivo o muerto) sobre ellos mismos y luego sobre otros Nodes que conocen. En Cassandra Gossip Communication Protocol también se conoce como protocolo epidémico. Es una forma automática rápida y descentralizada de aprender sobre sí mismo para el clúster, lo que es muy útil sobre la información de los Nodes en el clúster.
En el protocolo de comunicación de chismes para permitir un reinicio rápido, la información de chismes persiste localmente en cada Node. Comprender el significado de la persistencia es importante para evaluar diferentes sistemas de almacenamiento de datos.
La persistencia es “la continuación de un efecto después de que se elimina su causa”. En el contexto del almacenamiento de datos en un sistema informático, esto significa que los datos sobreviven después de que finaliza el proceso con el que se crearon. En otras palabras, para que un almacén de datos se considere persistente, debe escribir en un almacenamiento no volátil.
Crítico:
una de las tareas importantes es que la lista de Nodes semilla en cualquier centro de datos debe ser la misma en cada Node del clúster.
3. Detección de fallas:
en caso de detección de fallas, un Node determina localmente el estado y el historial de chismes y ajusta las rutas en consecuencia en un clúster. Phi Accrual es un algoritmo importante para el algoritmo de detección de fallas. Afirma que un nivel de sospecha continuo entre el estado vivo y muerto de un Node de cuán seguro ha fallado un Node. Puede ser el rendimiento de la red, el problema de la carga de trabajo debe tener prioridad, etc.
En caso de detección de fallas en un Node, otros Nodes intentarán periódicamente chismear con el Node fallido para ver si vuelve a estar en línea.
Ahora, echemos un vistazo con la consulta CQL para verificar el estado de un Node. Por defecto, cqlsh se conecta a 127.0.0.1. Para obtener la información, como la identificación del host, la versión de lanzamiento, etc., utilizó la siguiente consulta CQL.
SELECT peer, data_center, host_id,
preferred_ip, rack, release_version,
rpc_address, schema_version
FROM system.peers;
Para obtener la información de un Node se utilizó el siguiente comando CQL en Cassandra.
nodetool gossipinfo
Para terminar el Node ejecutando:
nodetool stopdaemon
Verifique la información de chismes en el Node1. Observe que la información de chismes del Node2 todavía está presente, ya que es parte del clúster, pero su estado de ESTADO es apagado.
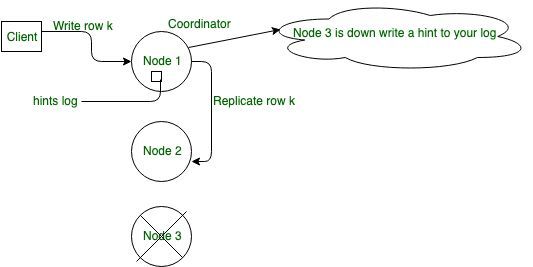
4. Transferencia sugerida:
en Cassandra es uno de los aspectos importantes para el mecanismo de alta disponibilidad. Ayuda a reducir el tiempo de restauración de un Node fallido que se reincorpora al clúster y a garantizar una disponibilidad de escritura absoluta al tolerar lecturas inconsistentes. Como se muestra en el diagrama, si la réplica está inactiva en el momento en que se produce una escritura, otra réplica en buen estado almacena una sugerencia y, si todas las réplicas relevantes están inactivas, el coordinador o almacena localmente la sugerencia.
Hint = location [failed replica]
+ affected [row key]
+ actual data being written
Nota:
En Cassandra, la sugerencia se entregará cuando un Node responsable de ese rango de token vuelva a estar activo.
Antientropía:
en el caso de un mecanismo de alta disponibilidad, la antientropía es un mecanismo de sincronización de réplicas para garantizar datos actualizados en todos los Nodes.
Ejemplo:
En general, la recomendación es tener suficientes Nodes en el clúster y un factor de replicación suficiente para evitar fallas en las requests de escritura. Por ejemplo, considere un clúster que consta de tres Nodes, Node 1, Node 2 y Node 3, con un factor de replicación de 2. Cuando se escribe una fila K en el coordinador (Node A en este caso), incluso si el Node 3 es hacia abajo, se puede alcanzar el nivel de consistencia de ONE o QUORUM. ¿Por qué? Tanto el Node 1 como el Node 2 recibirán los datos, por lo que se cumple el requisito del nivel de consistencia. La sugerencia del Node 1 se almacena para el Node 3 y se escribe cuando aparece el Node 3. Mientras tanto, el coordinador puede confirmar que la escritura se realizó correctamente.
Publicación traducida automáticamente
Artículo escrito por Ashish_rana y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA