A medida que nuestros sistemas maduran y comienzan a realizar cálculos más complejos, crece la necesidad de velocidad y la optimización de procesos se convierte en una necesidad. Cuando pasamos por alto este problema, terminamos con aplicaciones que tardan mucho en ejecutarse y demandan una gran cantidad de recursos del sistema.
En este artículo, veremos la memoización, que es una técnica que puede ayudarnos a reducir significativamente el tiempo de procesamiento si se hace de la manera correcta.
Memoización: la memorización es una técnica para acelerar las aplicaciones al almacenar en caché los resultados de costosas llamadas a funciones y devolverlos cuando se usan las mismas entradas nuevamente.
Tratemos de entender esto dividiendo la definición en partes pequeñas.
- Llamadas de función costosas: el tiempo y la memoria son los dos recursos más importantes en las aplicaciones informáticas. Como resultado, una llamada de función costosa es aquella que consume grandes cantidades de estos dos recursos debido al extenso cálculo durante la ejecución.
- Caché: un caché es solo un almacén de datos temporal que almacena datos para atender futuras requests de esos datos con mayor rapidez.
Importancia de la memorización: cuando se proporciona una función en la entrada, realiza el cálculo necesario y guarda el resultado en un caché antes de devolver el valor. Si en el futuro se vuelve a recibir la misma entrada, no será necesario repetir el proceso. Simplemente devolvería la respuesta almacenada en caché de la memoria. Esto dará como resultado una gran reducción en el tiempo de ejecución de un código.
Memoización en Javascript: En JavaScript, el concepto de memorización se basa principalmente en dos ideas. Son los siguientes:
- Cierres
- Funciones de orden superior
Cierres: antes de hablar sobre el cierre, echemos un vistazo rápido al concepto de alcance léxico en JavaScript. El alcance léxico define el alcance de una variable por la posición de esa variable declarada en el código fuente.
Ejemplo:
Javascript
let hello = "Hello";
function salutation() {
let name = "Aayush";
console.log(`${hello} ${name}!`);
}
En el código anterior:
- La variable hola es una variable global. Se puede acceder desde cualquier ubicación, incluida la función saludo() .
- El nombre de la variable es una variable local a la que solo se puede acceder dentro de la función saludo() .
Según el ámbito léxico, los ámbitos se pueden anidar y la función interna puede acceder a las variables declaradas en su ámbito externo. Por lo tanto, en el código siguiente, la función interna greeting() tiene acceso al nombre de la variable .
Javascript
function salutation() {
let name = "Aayush";
function greet() {
console.log(`Hello ${name}!`);
}
greet();
}
Ahora modifiquemos esta función saludo() y, en lugar de invocar la función saludo() , devolvemos el objeto de la función saludo() .
Javascript
function salutation() {
let name = 'Aayush';
function greet() {
console.log(`Hello ${name}!`);
}
return greet;
}
let wish = salutation();
wish();
Si ejecutamos este código, obtendremos el mismo resultado que antes. Sin embargo, vale la pena señalar que una variable local generalmente solo está presente durante la ejecución de la función. Significa que cuando se completa la ejecución de saludo() , la variable de nombre ya no es accesible. En este caso, cuando ejecutamos wish() , la referencia a greeting() , la variable de nombre todavía existe. Un cierre es una función que conserva el ámbito exterior en su ámbito interior.
Funciones de orden superior: Las funciones de orden superior son funciones que operan sobre otras funciones tomándolas como argumentos o devolviéndolas. Por ejemplo, en el código anterior, saludo() es una función de orden superior.
Ahora, usando la famosa secuencia de Fibonacci, examinemos cómo la memorización hace uso de estos conceptos.
Secuencia de Fibonacci: La secuencia de Fibonacci es una serie de números que comienza con uno y termina con uno, siguiendo la regla de que cada número (llamado número de Fibonacci ) es igual a la suma de los dos números anteriores.
1, 1, 2, 3, 5, 8, 13, 21, 34, 55, ...
Una solución recursiva simple a este problema sería:
Javascript
function fibonacci(n) {
if (n < 2)
return 1;
return fibonacci(n - 1) + fibonacci(n - 2);
}
Si tuviéramos que trazar el árbol de recurrencia para la función anterior cuando n=4 , se vería así:

Como puede notar, hay demasiados cálculos redundantes.
Intentemos arreglar esto con la memorización.
Javascript
function memoisedFibonacci(n, cache) {
cache = cache || [1, 1]
if (cache[n])
return cache[n]
return cache[n] = memoisedFibonacci(n - 1, cache) +
memoisedFibonacci(n - 2, cache);
}
Cambiamos la función en el ejemplo de código anterior para aceptar un argumento opcional llamado caché . Usamos el objeto de caché como una memoria temporal para almacenar números de Fibonacci con sus índices asociados como claves , que luego se pueden recuperar según sea necesario más adelante en la ejecución.
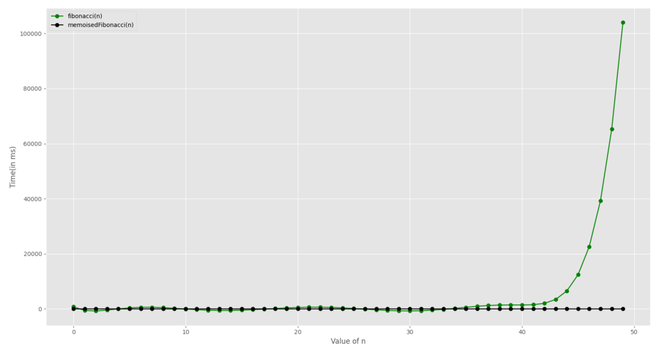
Si graficamos el tiempo de ejecución, para ambas versiones de la función de Fibonacci, es bastante evidente que el empleo de la técnica de memorización conduce a una reducción significativa del tiempo.
Ejemplo práctico: memorización de Javascript para una respuesta web: para demostrar esto, usaremos un ejemplo de API de modismos. Es una API REST simple creada con Node.js.
Tiempos de respuesta antes de la memorización: a continuación se muestra una ruta Express.js simple que devuelve todos los modismos almacenados en la API. En esta situación, cada llamada dará como resultado una consulta a la base de datos.
Javascript
import express from 'express';
const router = express.Router();
import { getAllIdioms } from '../services/database.js';
router.get('/', async function(req, res, next) {
try {
res.json(await getAllIdioms());
} catch (err) {
console.log('Error while getting idioms ', err.message);
res.status(err.statusCode || 500).json({
'message': err.message
});
}
})
Echemos un vistazo a cuánto tiempo tarda este enfoque en responder. Realicé una prueba de carga rápida con la herramienta de prueba de carga de Vegeta .
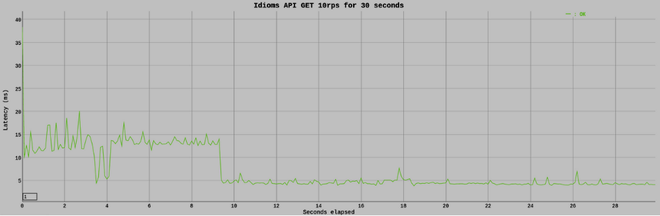
Tiempos de respuesta después de la memorización: ahora modifiquemos el código anterior para agregar la memorización. Para los propósitos de esta ilustración, he usado el paquete p-memoize .
Javascript
import express from 'express';
const router = express.Router();
import { getAllIdioms } from '../services/database.js';
import pMemoize from 'p-memoize';
const ONE_MINUTE_IN_MS = 60000;
const memGetAllIdioms = pMemoize(getAllIdioms, { maxAge: ONE_MINUTE_IN_MS });
router.get('/', async function (req, res, next) {
try {
res.json(await memGetAllIdioms());
} catch (err) {
console.log('Error while getting idioms ', err.message);
res.status(err.statusCode || 500).json({'message': err.message});
}
})
Como resultado,
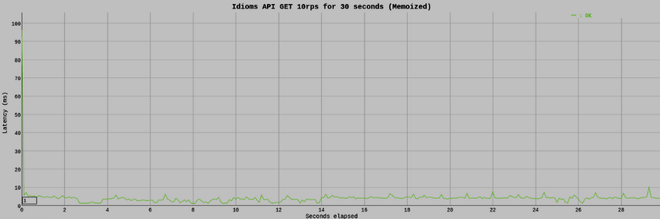
Cuando se compara con el gráfico anterior, podemos observar que la ruta Express.js que usa memorización es significativamente más rápida que el equivalente sin memorización.
Publicación traducida automáticamente
Artículo escrito por aayushmohansinha y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA