El método to_excel() se usa para exportar el DataFrame al archivo de Excel. Para escribir un solo objeto en el archivo de Excel, debemos especificar el nombre del archivo de destino. Si queremos escribir en varias hojas, debemos crear un objeto ExcelWriter con el nombre de archivo de destino y también debemos especificar la hoja en el archivo en el que tenemos que escribir. Las hojas múltiples también se pueden escribir especificando el único sheet_name. Es necesario guardar los cambios para todos los datos escritos en el archivo.
Sintaxis:
data.to_excel( excel_writer, sheet_name='Sheet1', \*\*kwargs )
Parámetros:
| Argumentos | Escribe | Descripción |
|---|---|---|
| excelente_escritor | str o objeto ExcelWriter | Ruta del archivo o ExcelWriter existente |
| nombre_hoja | str, por defecto ‘Hoja1’ | Nombre de la hoja que contendrá DataFrame |
| columnas | secuencia o lista de str, opcional | columnas para escribir |
| índice | booleano, predeterminado Verdadero | Escribir nombres de fila (índice) |
| etiqueta_índice | str o secuencia, opcional | Etiqueta de columna para la(s) columna(s) de índice, si lo desea. Si no se especifica, y `header` e `index` son verdaderos, se utilizan los nombres de índice. Se debe dar una secuencia si el DataFrame usa MultiIndex. |
- Se puede proporcionar el nombre del archivo de Excel o el objeto Excelwrite.
- De forma predeterminada, el número de hoja es 1, se puede cambiar ingresando el valor del argumento «sheet_name».
- Se puede proporcionar el nombre de las columnas para almacenar los datos ingresando el valor del argumento «columnas».
- Por defecto, el índice está etiquetado con números como 0,1,2… y así sucesivamente, uno puede cambiarlo pasando una secuencia de la lista por el valor del argumento «índice».
A continuación se muestra la implementación del método anterior:
Python3
# importing packages
import pandas as pd
# dictionary of data
dct = {'ID': {0: 23, 1: 43, 2: 12,
3: 13, 4: 67, 5: 89,
6: 90, 7: 56, 8: 34},
'Name': {0: 'Ram', 1: 'Deep',
2: 'Yash', 3: 'Aman',
4: 'Arjun', 5: 'Aditya',
6: 'Divya', 7: 'Chalsea',
8: 'Akash' },
'Marks': {0: 89, 1: 97, 2: 45, 3: 78,
4: 56, 5: 76, 6: 100, 7: 87,
8: 81},
'Grade': {0: 'B', 1: 'A', 2: 'F', 3: 'C',
4: 'E', 5: 'C', 6: 'A', 7: 'B',
8: 'B'}
}
# forming dataframe
data = pd.DataFrame(dct)
# storing into the excel file
data.to_excel("output.xlsx")
Producción :
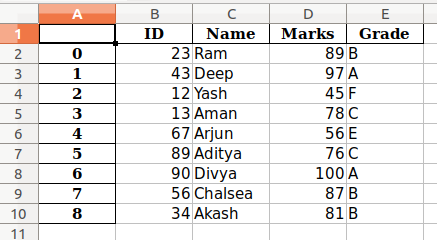
En el ejemplo anterior,
- Por defecto, el índice está etiquetado como 0,1,…. y así.
- Como nuestro DataFrame tiene nombres de columnas, las columnas están etiquetadas.
- Por defecto, se guarda en “Hoja1”.
Publicación traducida automáticamente
Artículo escrito por deepanshu_rustagi y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA